Command Palette
Search for a command to run...
Innovative Input/Output Technology! Tencent Hunyuan Launches HunyuanWorld-Mirror, Refreshing 3D Reconstruction to State-of-the-Art; Decoding the Full Picture of Netflix Content! Netflix Movie and TV Catalog Dataset Helps Insights Into Entertainment Trends

Visual geometry learning is a core topic in computer vision, widely applied in augmented reality, robot manipulation, and autonomous navigation. Traditional methods, such as structure-of-motion (SfM) and multi-view stereo techniques, typically rely on iterative optimization, resulting in high computational costs.In recent years, the field has gradually shifted towards end-to-end geometry reconstruction models based on feedforward neural networks.
Despite the significant results, existing methods still have obvious limitations in both the input and output dimensions.On the input side, the current model fails to utilize readily available prior information such as camera intrinsics, initial pose, and sensor depth because it only processes the raw image.This results in poor performance when dealing with issues such as scale ambiguity, inconsistencies between multiple viewpoints, and regions lacking texture. On the output side, existing methods are mostly limited to single or a few geometric tasks (such as depth or pose estimation), exhibiting high specialization and a lack of integration. Although research such as VGGT has promoted task unification, fundamental tasks such as surface normal estimation and novel viewpoint synthesis have not yet been incorporated into a unified framework.
The aforementioned limitations raise a key question: Is it possible to address both input and output challenges simultaneously within a general 3D reconstruction framework by effectively incorporating diverse prior information?
Based on this,Tencent's Hunyuan team has launched HunyuanWorld-Mirror, a fully integrated, feedforward model for versatile 3D geometry prediction tasks, designed to leverage any available geometric prior knowledge to perform general 3D reconstruction tasks.At the heart of the model is a novel multimodal prior cueing mechanism that flexibly integrates multiple geometric priors, including camera pose, intrinsic parameters, and depth maps, while simultaneously generating multiple 3D representations: dense point clouds, multi-view depth maps, camera parameters, surface normals, and 3D Gaussian distributions. This unified architecture leverages available prior information to resolve structural ambiguities and provides geometrically consistent 3D output in a single feedforward process.
HunyuanWorld-Mirror leverages available priors to enable robust reconstruction in challenging scenarios, and its multi-task design ensures geometric consistency across different outputs.State-of-the-art performance was achieved across a wide range of benchmarks, from camera, point map, depth and surface normal estimation to new perspective synthesis.
The HyperAI website now features "HunyuanWorld-Mirror: A 3D World Generation Model," so come and try it out!
Online use:https://go.hyper.ai/Ptv69
A quick overview of hyper.ai's official website updates from November 24th to November 28th:
* High-quality public datasets: 7
* High-quality tutorial selection: 6
* This week's recommended papers: 5
* Community article interpretation: 5 articles
* Popular encyclopedia entries: 5
Top conferences with December deadlines: 2
Visit the official website:hyper.ai
Selected public datasets
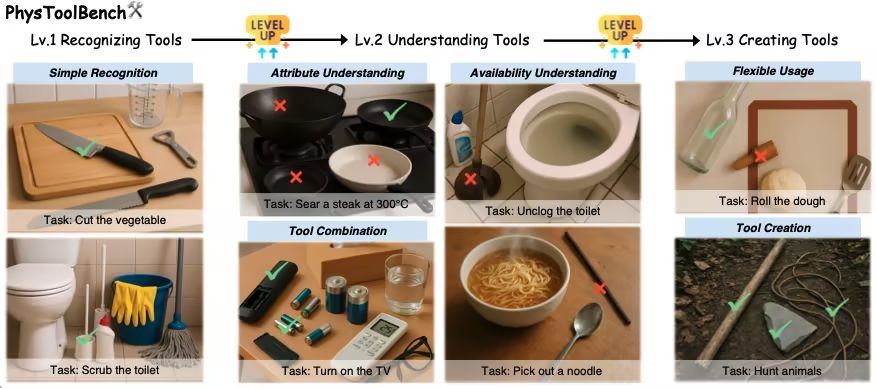
1. PhysToolBench Physics Tool Task Dataset
PhysToolBench is a visual-language question answering (VQA) dataset released by the Hong Kong University of Science and Technology (Guangzhou) in collaboration with Hong Kong University of Science and Technology, Beijing University of Aeronautics and Astronautics, and other institutions. It aims to evaluate the ability of multimodal large language models (MLLMs) to recognize, understand, and create physical tools. The dataset contains over 1,000 image-text pairs, covering various scenarios including daily life, industry, outdoor activities, and professional environments.
Direct use:https://go.hyper.ai/bP9Ad
2. CytoData Blood Cell Image Dataset
The CytoData blood cell image dataset is an anonymized blood cell dataset published in Nature by a research team from the University of Cambridge, UK. The dataset contains 2,904 blood smears from Addenbrooke's Hospital in Cambridge, totaling 559,808 single-cell images. Of these, 4,996 images are labeled with ten blood cell types, including erythroblasts and eosinophils.
Direct use:https://go.hyper.ai/uLXKt
3. MeshCoder: Structured 3D Object-Code Dataset
MeshCoder is a multimodal dataset for generating editable code from 3D point clouds, released by the Shanghai Artificial Intelligence Laboratory in collaboration with Tsinghua University, Harbin Institute of Technology (Shenzhen), and other institutions. It aims to promote the development of large language models in 3D scene parsing, structural understanding, and programmable geometric reconstruction.
Direct use:https://go.hyper.ai/x3zvv
4. Netflix Movie and TV Catalog Dataset
The Netflix Movies & TV Shows Catalog Dataset is a comprehensive catalog dataset covering various types of film and television content from multiple countries worldwide. It aims to showcase the overall content distribution on the Netflix platform and provide data support for research into entertainment trends, audience preferences, and content strategy. This dataset includes entries for movies and TV series already available on Netflix. Each entry represents a title and includes key information such as the title, content type (movie or TV series), and director.
Direct use:https://go.hyper.ai/8gzcZ
5. InteractMove 3D Scene Human-Object Interaction Dataset
InteractMove is a dataset for generating human-object interactions in 3D scenes, jointly released by the Institute of Computer Science and Technology at Peking University and the Beijing Institute of Electronic Science and Technology. It aims to support and promote research on text-based control-based interactive modeling of movable objects. The dataset covers multiple types of movable objects and various real-world scanned scenes, and provides human-object interaction action sequences that are strictly aligned with the scene.
Direct use:https://go.hyper.ai/uFrPd
6. GroundCUA Interface Operation Training Dataset
GroundCUA is a real-world user interface (UI) dataset released by the Mila Quebec Artificial Intelligence Institute in collaboration with McGill University, the University of Montreal, and other institutions. It aims to support research on multimodal intelligent agents capable of interacting with computers. The dataset is built upon expert-level human demonstrations and provides over 3.56 million manually verified element-level annotations.
Direct use:https://go.hyper.ai/5bDrX
7. Camera Clone Multi-view Dataset
Camera Clone, released by the University of Hong Kong in collaboration with Zhejiang University, Kuaishou Technology, and other institutions, is a large-scale synthetic video dataset based on Unreal Engine 5 rendering. It aims to support camera clone learning, which replicates the camera motion of a reference video while keeping the scene content unchanged, achieving "content reproduction + camera motion matching".
Direct use:https://go.hyper.ai/US4nY
Selected Public Tutorials
1. PyTorch Official Tutorial: Implementing Deep Learning with PyTorch
The goal of this tutorial is to understand how to use tensors and build neural networks in PyTorch, and to train a small neural network to classify images.
Run online:https://go.hyper.ai/Fb2c6
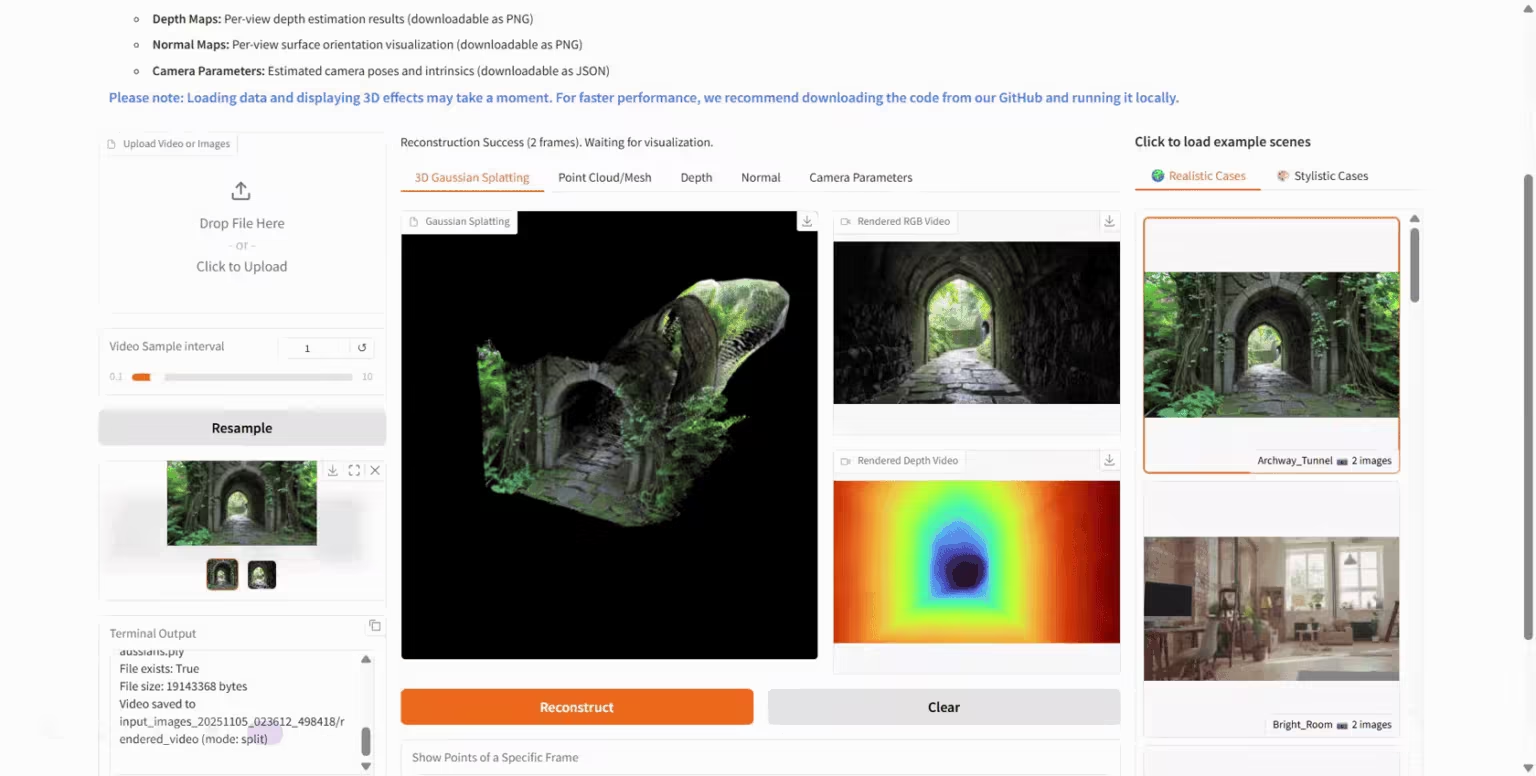
2. HunyuanWorld-Mirror: A 3D World Generation Model
HunyuanWorld-Mirror is an open-source 3D world generation model released by Tencent's Hunyuan team. It supports multiple input methods, including multi-view images and videos, and can output various 3D geometric prediction results such as point clouds, depth maps, and camera parameters. The model adopts a pure feedforward architecture, can be deployed on a single graphics card, and processes 8-32 view inputs locally in just 1 second, achieving second-level inference.
Run online:https://go.hyper.ai/Ptv69
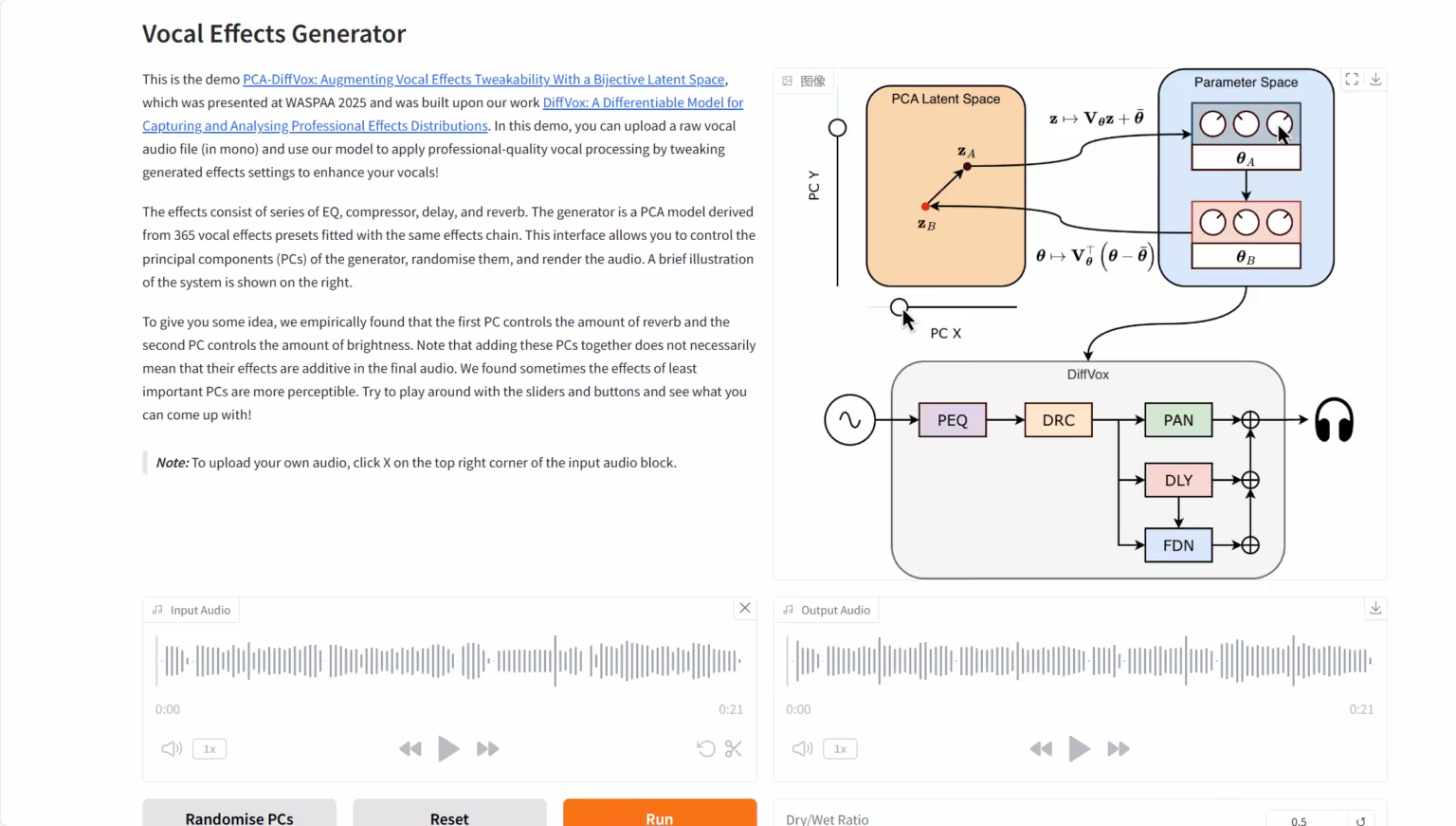
3. DiffVox: Sound Differentiation Model
The DiffVox project was jointly launched by Sony AI, Sony Group, and a research team from Queen Mary University of London. The core capability of this model lies in its use of advanced inference-time optimization methods and the innovative introduction of Gaussian prior constraints, which enables it to intelligently transform a raw human voice recording into high-quality audio that is audibly close to the target reference and meets professional mixing standards in terms of parameters.
Run online:https://go.hyper.ai/Y19Wv
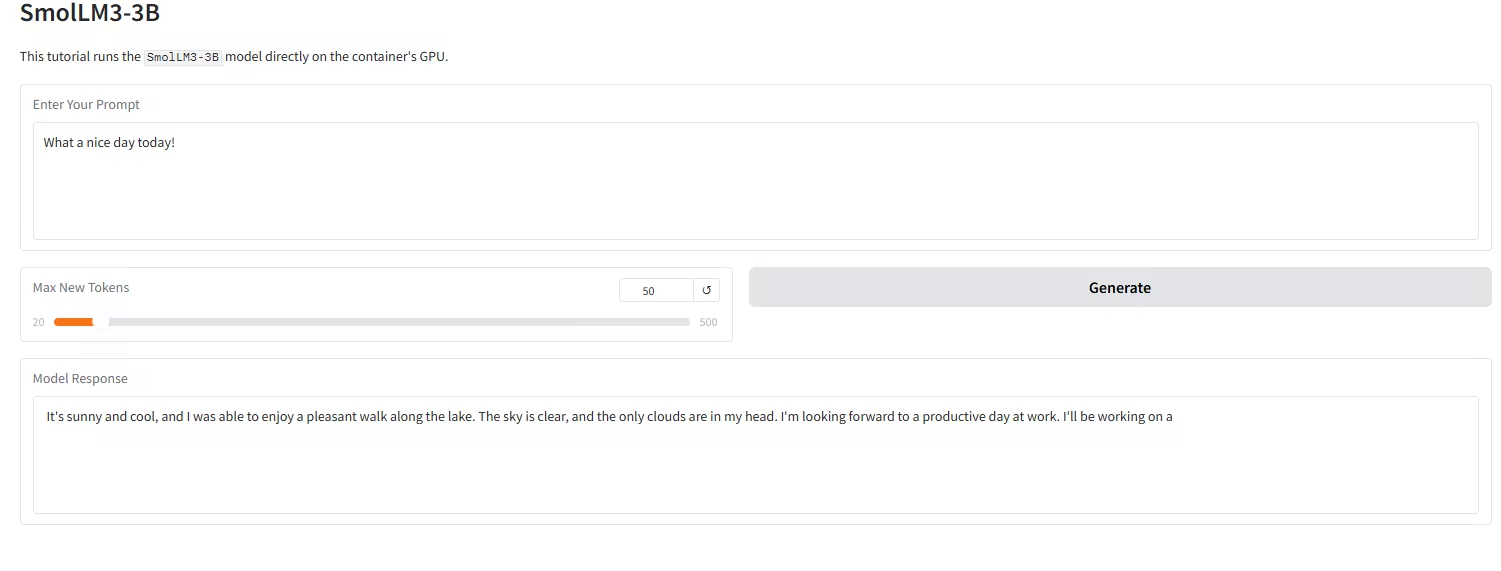
4. One-click deployment of SmolLM3-3B-Model
SmolLM3-3B, released by the Hugging Face TB (Transformer Big) team, is positioned as the "ceiling of edge performance." It is a revolutionary open-source language model with 3 billion parameters, aiming to break through the performance limits of small models in a compact 3B size.
Run online:https://go.hyper.ai/wZ48d
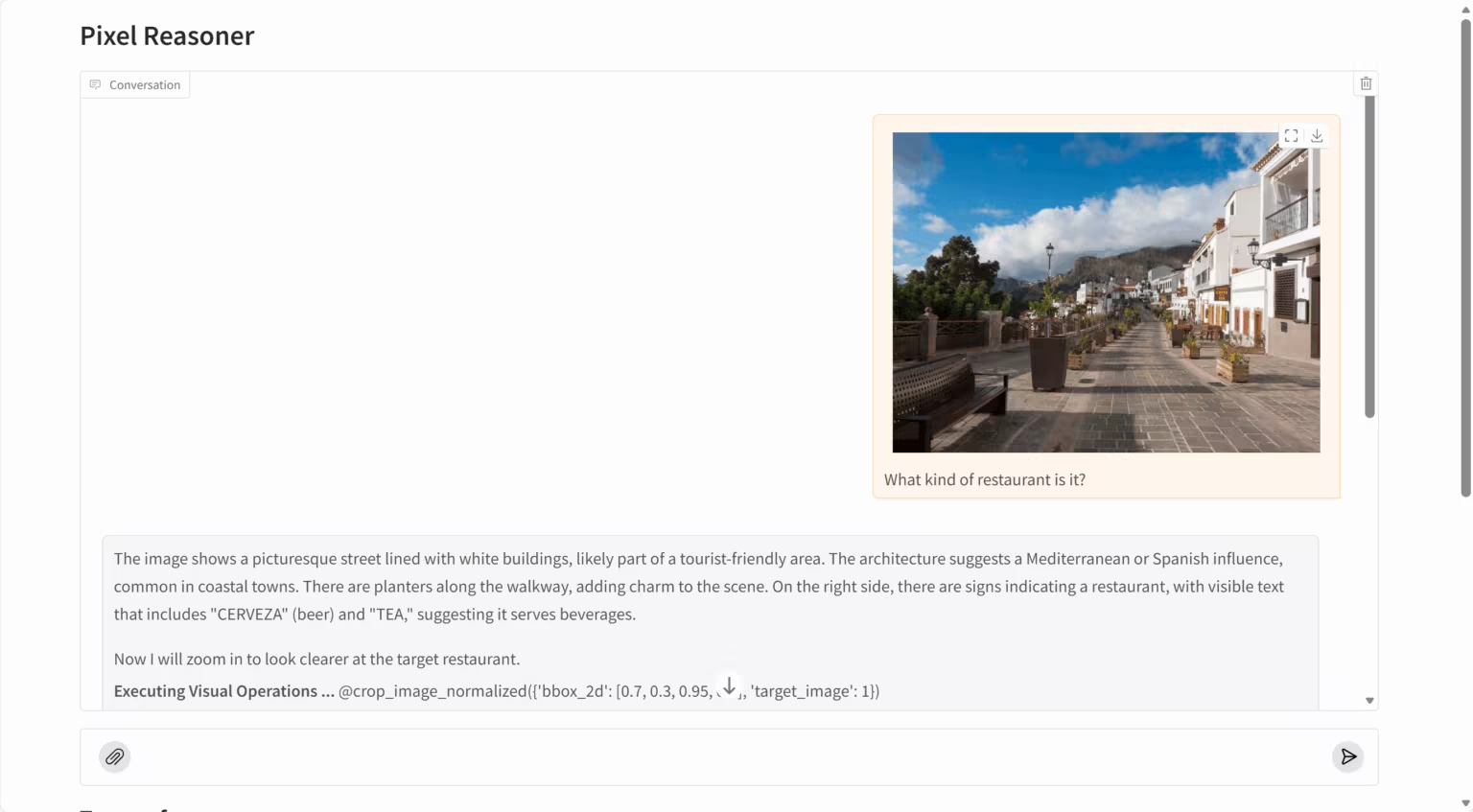
5. PixelReasoner-RL: Pixel-level visual inference model
PixelReasoner-RL-v1 is a groundbreaking visual language model released by TIGER AI Lab. Based on the Qwen2.5-VL architecture, the project utilizes an innovative curiosity-driven reinforcement learning training method to overcome the limitations of traditional visual language models that rely solely on text-based reasoning. The model can perform reasoning directly in pixel space, supporting visual operations such as scaling and frame selection, significantly improving its ability to understand image details, spatial relationships, and video content.
Run online:https://go.hyper.ai/t1rdr
6. Krea-realtime-video: Real-time video generation model
Krea Realtime 14B is a 14 billion parameter real-time video generation model released by the Krea team. It enables real-time long-form video generation and is one of the largest publicly available real-time video generation models. Based on the Wan 2.1 14B text-to-video model, this model uses self-forcing distillation training to transform the traditional video diffusion model into an autoregressive structure, thus achieving a truly real-time video generation experience.
Run online:https://go.hyper.ai/GS7oW

This week's paper recommendation
1. General Agentic Memory Via Deep Research
This paper proposes a novel framework called General Agentic Memory (GAM). This framework follows the "Just-In-Time" (JIT) principle: it retains only simple but practical memories offline, while focusing on building optimized contexts for its clients at runtime. Experimental studies demonstrate that GAM achieves significant performance improvements across various memory-based task completion scenarios compared to existing memory systems.
Paper link:https://go.hyper.ai/sA1RN
2. ROOT: Robust Orthogonalized Optimizer for Neural Network Training
This paper proposes ROOT, a robust orthogonalized optimizer, which significantly enhances training stability through a dual robustness mechanism. Extensive experimental results demonstrate that ROOT exhibits significantly enhanced robustness in noisy environments and non-convex optimization scenarios. Compared to Muon and Adam-based optimizers, it not only converges faster but also achieves superior final performance.
Paper link:https://go.hyper.ai/gv0x2
3. GigaEvo: An Open Source Optimization Framework Powered By LLMs And Evolution Algorithms
This paper proposes GigaEvo, a scalable open-source framework designed to support researchers in conducting research and experimentation on hybrid LLM-evolutionary computation methods inspired by AlphaEvolve. The GigaEvo system provides modular implementations of several core components: the MAP-Elites quality-diversity algorithm, an asynchronous evaluation pipeline based on directed acyclic graphs (DAGs), an LLM-driven mutation operator with insightful generative capabilities, and a bidirectional lineage tracing mechanism, while also supporting flexible multi-island evolutionary strategies.
Paper link:https://go.hyper.ai/jN3Q1
4. SAM 3: Segment Anything with Concepts
This paper proposes Segment Anything Model (SAM) 3, a unified model capable of detecting, segmenting, and tracking objects in images and videos based on concept prompts. SAM 3 achieves twice the accuracy of existing systems on image and video PCS tasks and improves the performance of previous generation SAMs on visual segmentation tasks. SAM 3 is now open source, and a new benchmark for promptable concept segmentation, Segment Anything with Concepts (SA-Co), has also been released.
Paper link:https://go.hyper.ai/KN3g7
5. OpenMMReasoner: Pushing the Frontiers for Multimodal Reasoning with an Open and General Recipe
This paper introduces OpenMMReasoner, a fully transparent two-stage multimodal inference training scheme encompassing supervised fine-tuning (SFT) and reinforcement learning (RL). In the SFT stage, researchers constructed a cold-start dataset containing 874,000 samples and employed a rigorous step-by-step validation mechanism to lay a solid foundation for inference capabilities. The subsequent RL stage utilizes a dataset of 74,000 samples covering multiple domains to further strengthen and stabilize these capabilities, thereby achieving a more robust and efficient learning process.
Paper link:https://go.hyper.ai/OfXKY
More AI frontier papers:https://go.hyper.ai/iSYSZ
Community article interpretation
1. The first multimodal astronomical model, AION-1, has been successfully developed! UC Berkeley and other researchers have successfully constructed a generalized multimodal astronomical AI framework based on pre-training on 200 million astronomical targets.
Teams from more than ten research institutions around the world, including the University of California, Berkeley, the University of Cambridge, and the University of Oxford, have collaborated to launch AION-1, the first large-scale multimodal foundational model family for astronomy. Through a unified early fusion backbone network, it integrates and models heterogeneous observational information such as images, spectra, and star catalog data. It not only performs well in zero-shot scenarios, but its linear detection accuracy can also rival or even surpass models specifically trained for specific tasks.
View the full report:https://go.hyper.ai/2zA0f
2. Meituan's open-source video generation model, LongCat-Video, possesses three major capabilities: text-based video generation, image-based video generation, and video continuation, comparable to top-tier open-source and closed-source models.
Meituan has open-sourced its latest video generation model, LongCat-Video. This model aims to handle various video generation tasks through a unified architecture, including text-to-video, image-to-video, and video-continuation. Based on its outstanding performance in general video generation tasks, the research team considers LongCat-Video a solid step towards building a true "world model."
View the full report:https://go.hyper.ai/b6pzF
3. Free CPU usage / 30 hours of GPU usage credit / 70GB of super-large storage, HyperAI Pro is officially launched!
HyperAI has curated hundreds of machine learning tutorials and compiled them into Jupyter Notebooks, allowing beginners and experienced engineers alike to easily access high-quality open-source projects or create and deploy entirely new models. HyperAI provides stable computing power to help AI projects go from initial inspiration to rapid deployment. To better meet the needs of its users and offer more flexible and affordable computing power billing options, HyperAI has officially launched its HyperAI Pro membership system.
View the full report:https://go.hyper.ai/Oi7d3
4. Cambridge University develops blood cell image classifier; diffusion model aids in leukemia detection, surpassing the capabilities of clinical experts.
A research team from the University of Cambridge in the UK has proposed CytoDiffusion, a blood cell image classification method based on a diffusion model. It faithfully models the morphological distribution of blood cells for accurate classification, while also possessing strong anomaly detection capabilities, resistance to distribution shifts, interpretability, high data efficiency, and uncertainty quantification capabilities that surpass those of clinical experts.
View the full report:https://go.hyper.ai/QSCmq
5. Broadcom's 72-year-old CEO, who built his company on acquisitions, has extended his contract until 2030, aiming to increase the company's AI revenue to $120 billion.
Looking at Hock Tan's resume, "mergers and acquisitions" are an unavoidable topic. However, viewing him solely from a business investment perspective is too narrow and simplistic. Each of his moves, beyond profit and revenue calculations, also gradually elevates his company to a core position; the underlying trend predictions are even more crucial.
View the full report:https://go.hyper.ai/6lPG5
Popular Encyclopedia Articles
1. DALL-E
2. HyperNetworks
3. Pareto Front
4. Bidirectional Long Short-Term Memory (Bi-LSTM)
5. Reciprocal Rank Fusion
Here are hundreds of AI-related terms compiled to help you understand "artificial intelligence" here:
Top conference with a December deadline

One-stop tracking of top AI academic conferences:https://go.hyper.ai/event
The above is all the content of this week’s editor’s selection. If you have resources that you want to include on the hyper.ai official website, you are also welcome to leave a message or submit an article to tell us!
See you next week!
About HyperAI
HyperAI (hyper.ai) is the leading artificial intelligence and high-performance computing community in China.We are committed to becoming the infrastructure in the field of data science in China and providing rich and high-quality public resources for domestic developers. So far, we have:
* Provide domestic accelerated download nodes for 1800+ public datasets
* Includes 600+ classic and popular online tutorials
* Interpretation of 200+ AI4Science paper cases
* Supports 600+ related terms search
* Hosting the first complete Apache TVM Chinese documentation in China
Visit the official website to start your learning journey: