Command Palette
Search for a command to run...
Long-VITA: A Multimodal Understanding Demo With Millions of Tokens
1. Tutorial Introduction

Long-VITA is a research achievement of long-context multimodal large-scale models released in February 2025 by Tencent YouTu Lab, Nanjing University, and Xiamen University. This model maintains leading accuracy with short contexts while extending the context length to 1 million tokens, enabling efficient processing of multimodal inputs such as text and images. The related paper is titled "...".Long-VITA: Scaling Large Multi-modal Models to 1 Million Tokens with Leading Short-Context Accuracy".
This tutorial uses a single RTX 4090 graphics card and deploys a Long-VITA-16K_HF model.
2. Effect Examples
Text Conversation
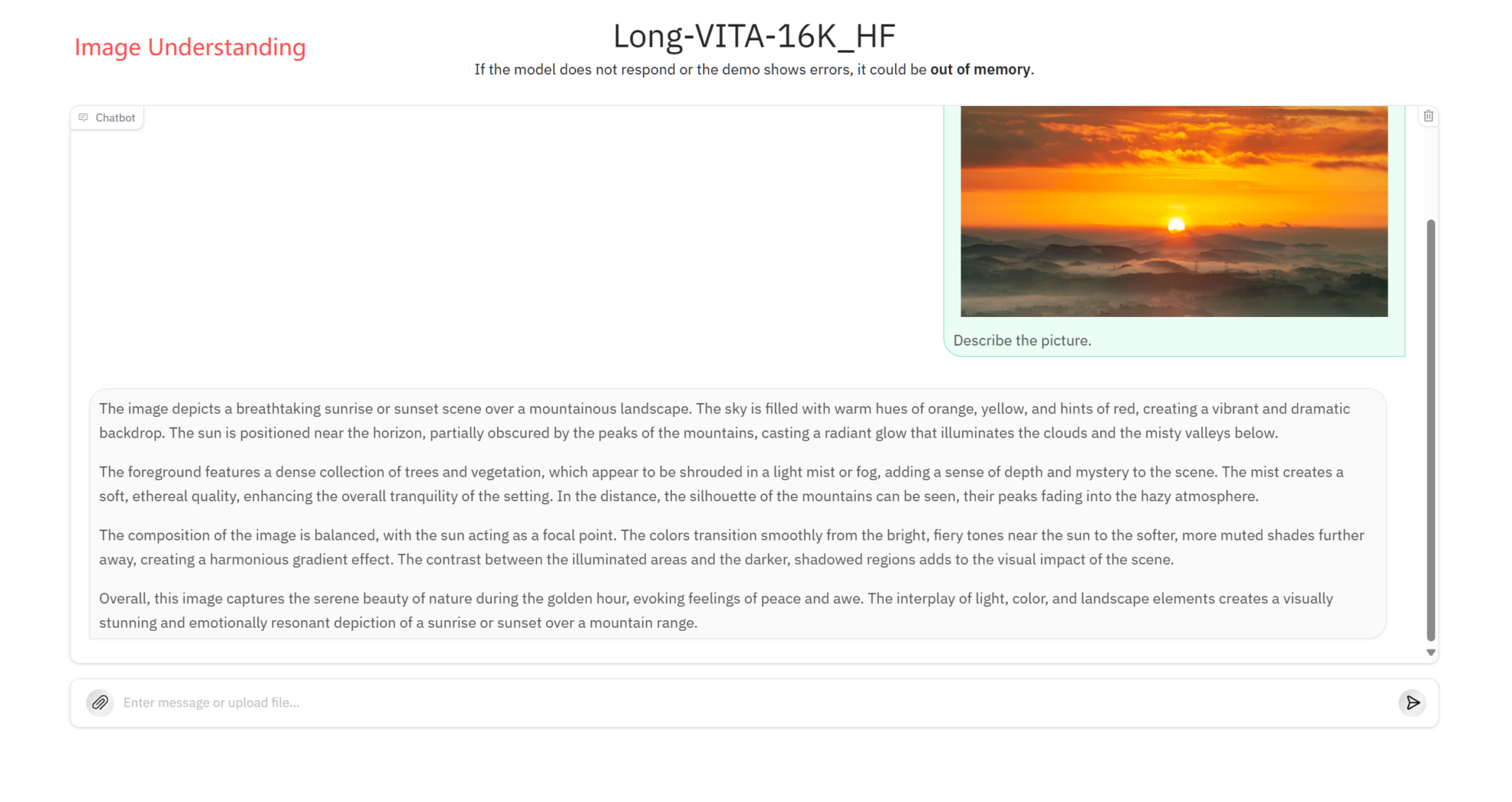
Image understanding
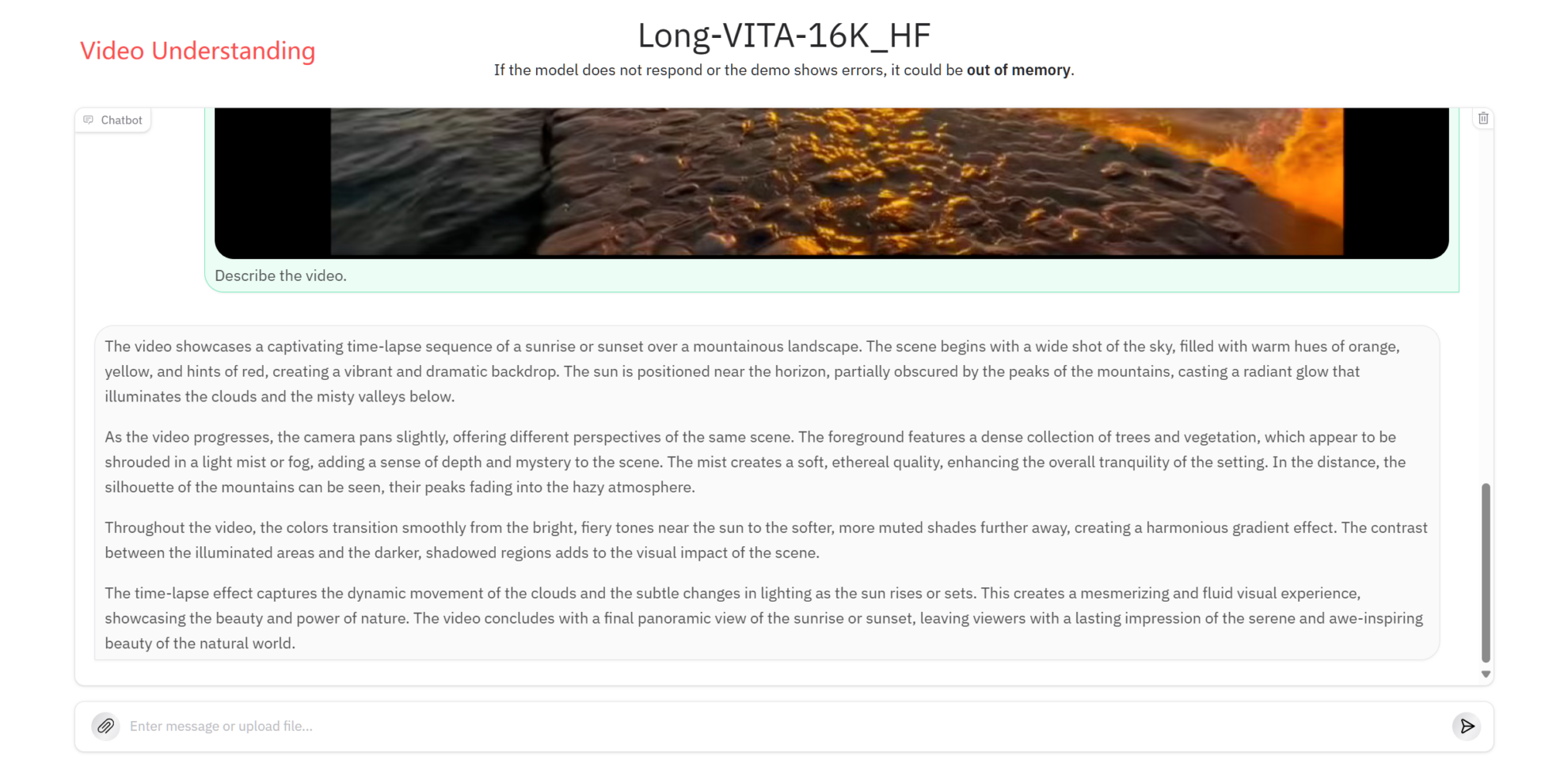
Video Understanding
3. Operation steps
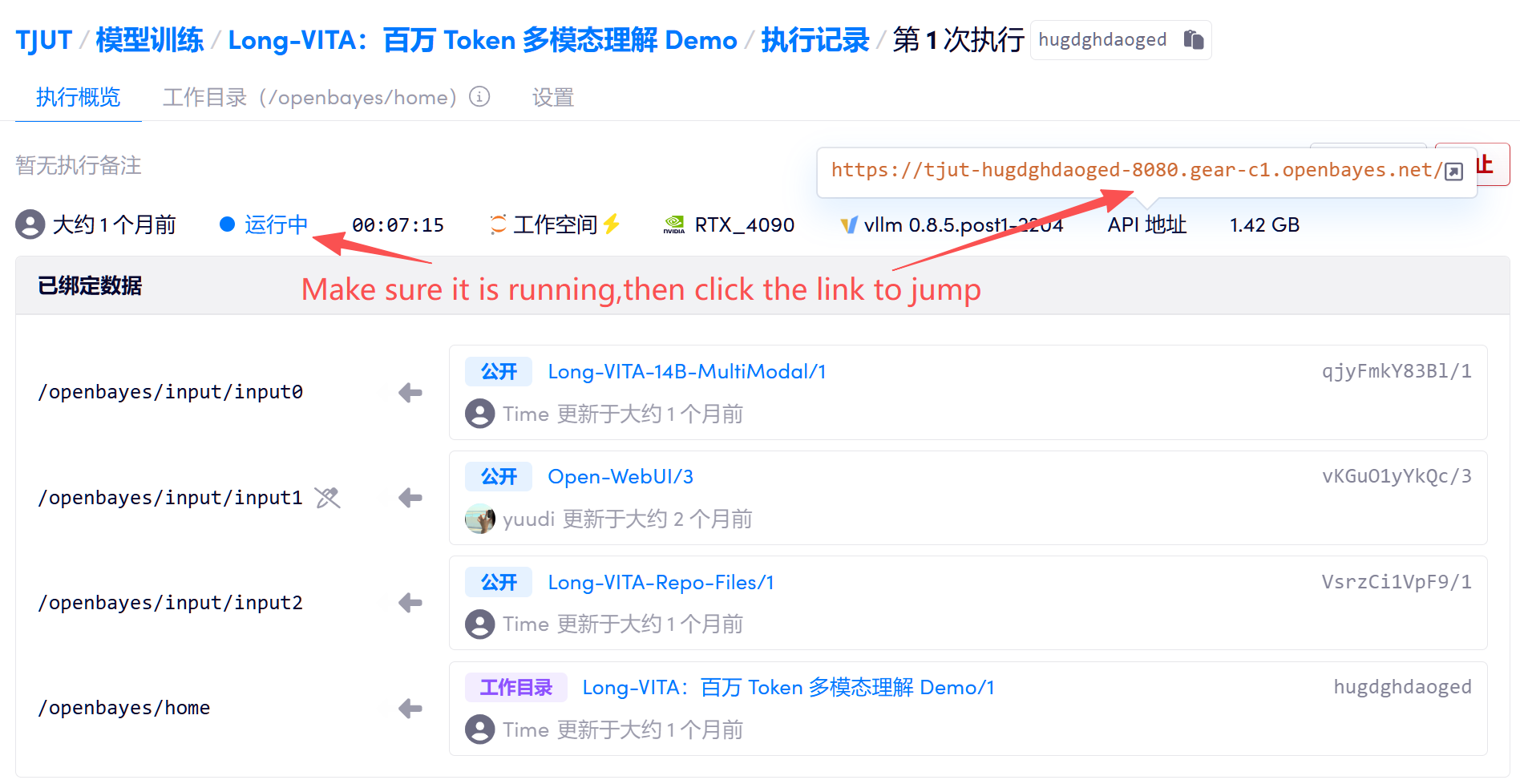
1. After starting the container, click the API address to enter the Gradio interactive interface
2. Once you enter the webpage, you can use the model
If "Bad Gateway" is displayed, it means the model is initializing. Since the model is large, please wait about 2-3 minutes and refresh the page.
Precautions
- For long context inputs, ensure sufficient video memory; it is recommended to load very large texts in batches.
- Image input is recommended to have a side length of ≤ 2048 pixels to reduce inference latency.
- If the inference fails, please check the input format or shorten the input length and try again.
Citation Information
The citation information for this project is as follows:
@misc{shen2025longvitascalinglargemultimodal,
title={Long-VITA: Scaling Large Multi-modal Models to 1 Million Tokens with Leading Short-Context Accuracy},
author={Yunhang Shen and Chaoyou Fu and Shaoqi Dong and Xiong Wang and Yi-Fan Zhang and Peixian Chen and Mengdan Zhang and Haoyu Cao and Ke Li and Xiawu Zheng and Yan Zhang and Yiyi Zhou and Ran He and Caifeng Shan and Rongrong Ji and Xing Sun},
year={2025},
eprint={2502.05177},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2502.05177},
}Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.