6 months ago
Naver at ActivityNet Challenge 2019 -- Task B Active Speaker Detection
(AVA)
Naver at ActivityNet Challenge 2019 -- Task B Active Speaker Detection (AVA)
Chung Joon Son
Abstract
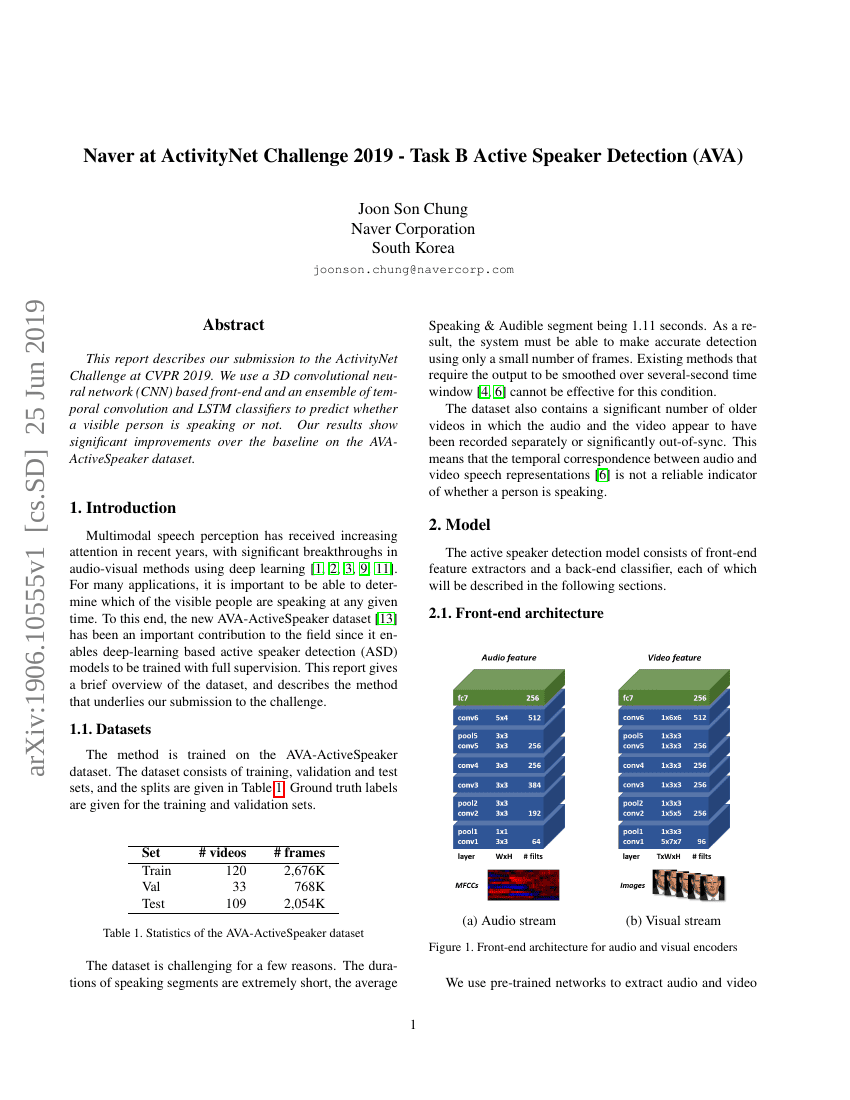
This report describes our submission to the ActivityNet Challenge at CVPR2019. We use a 3D convolutional neural network (CNN) based front-end and anensemble of temporal convolution and LSTM classifiers to predict whether avisible person is speaking or not. Our results show significant improvementsover the baseline on the AVA-ActiveSpeaker dataset.
Benchmarks
| Benchmark | Methodology | Metrics |
|---|---|---|
| audio-visual-active-speaker-detection-on-ava | VGG-{LSTM+TCN} (ensemble) | validation mean average precision: 87.8% |
Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.
AI Co-coding
Ready-to-use GPUs
Best Pricing
Hyper Newsletters
Subscribe to our latest updates
We will deliver the latest updates of the week to your inbox at nine o'clock every Monday morning
Powered by MailChimp