Michał Pietruszka Łukasz Borchmann Łukasz Garncarek
Abstract
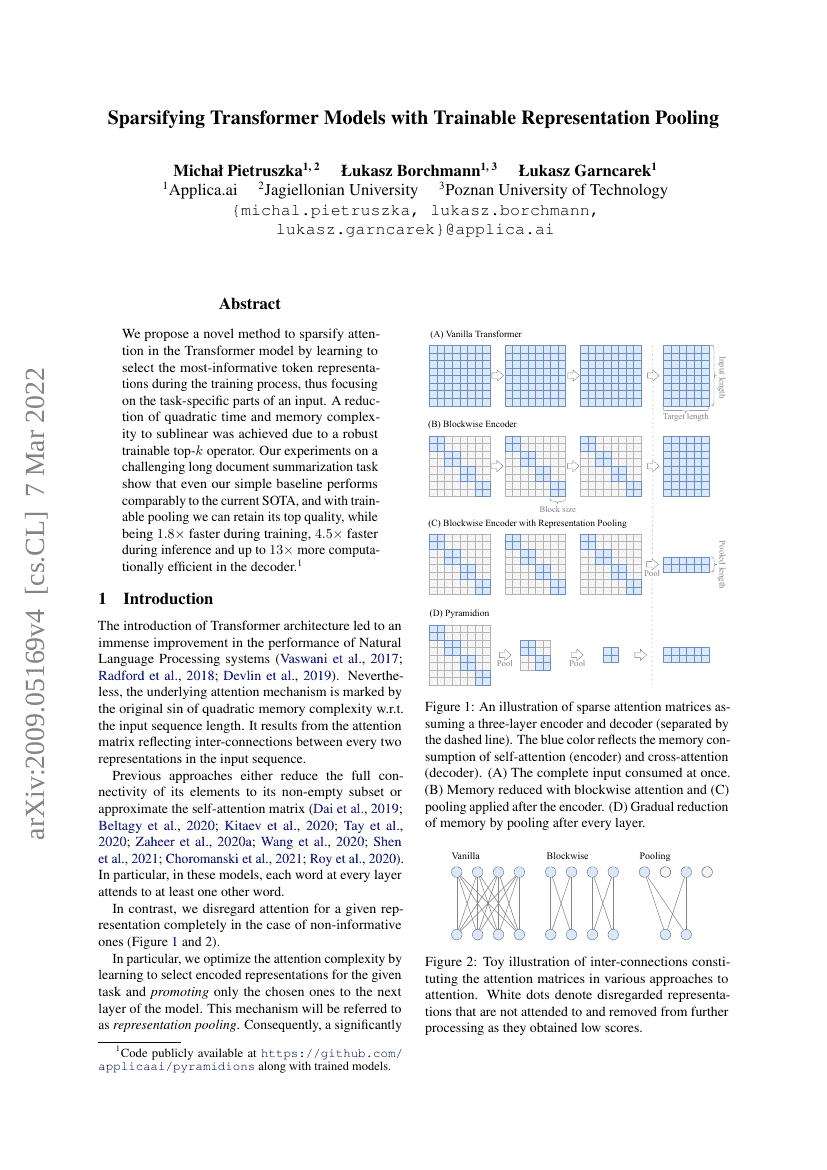
We propose a novel method to sparsify attention in the Transformer model by learning to select the most-informative token representations during the training process, thus focusing on the task-specific parts of an input. A reduction of quadratic time and memory complexity to sublinear was achieved due to a robust trainable top-k operator. Our experiments on a challenging long document summarization task show that even our simple baseline performs comparably to the current SOTA, and with trainable pooling, we can retain its top quality, while being 1.8× faster during training, 4.5× faster during inference, and up to 13× more computationally efficient in the decoder.
Code Repositories
Benchmarks
| Benchmark | Methodology | Metrics |
|---|---|---|
| text-summarization-on-arxiv-summarization | DeepPyramidion | ROUGE-1: 47.15 ROUGE-2: 19.99 |
| text-summarization-on-arxiv-summarization | Blockwise (baseline) | ROUGE-1: 46.85 ROUGE-2: 19.39 |
| text-summarization-on-pubmed-1 | DeepPyramidion | ROUGE-1: 47.81 ROUGE-2: 21.14 |
Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.