Lucas Georges Gabriel Charpentier; David Samuel
Abstract
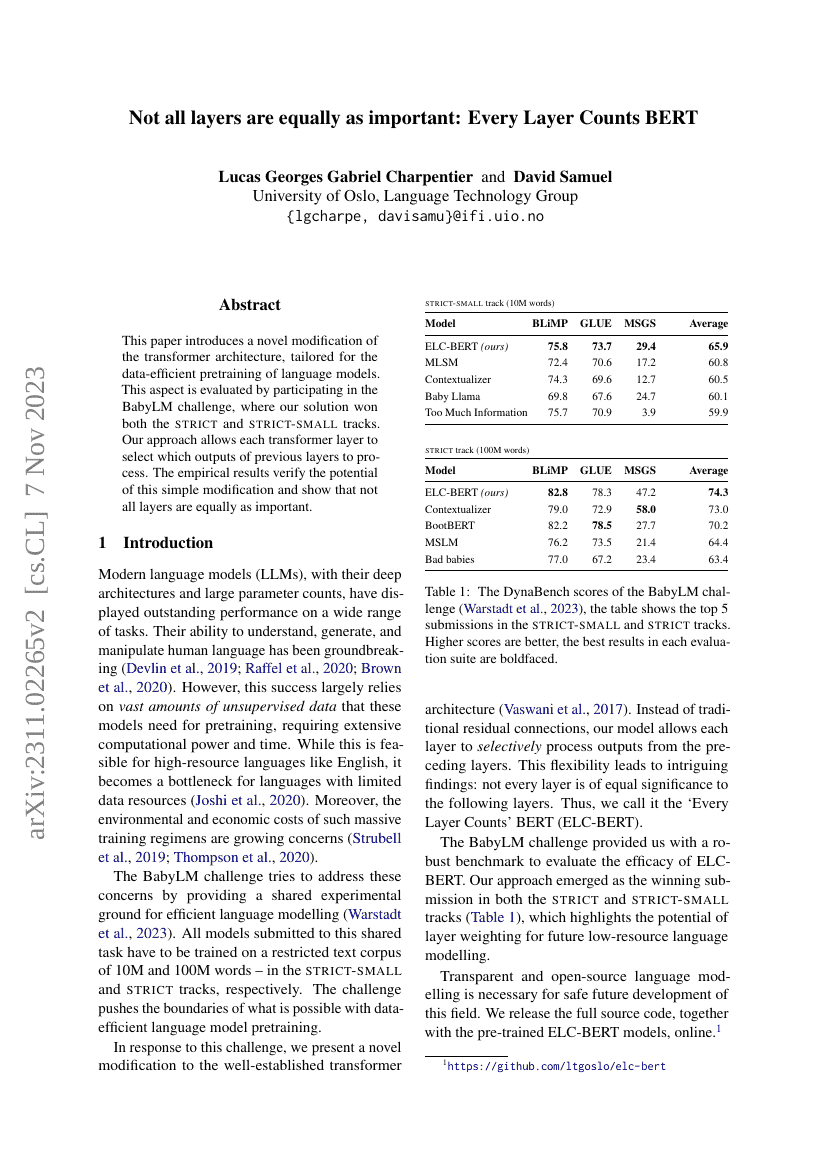
This paper introduces a novel modification of the transformer architecture, tailored for the data-efficient pretraining of language models. This aspect is evaluated by participating in the BabyLM challenge, where our solution won both the strict and strict-small tracks. Our approach allows each transformer layer to select which outputs of previous layers to process. The empirical results verify the potential of this simple modification and show that not all layers are equally as important.
Benchmarks
| Benchmark | Methodology | Metrics |
|---|---|---|
| linguistic-acceptability-on-cola | LTG-BERT-base 98M | Accuracy: 82.7 |
| linguistic-acceptability-on-cola | ELC-BERT-base 98M | Accuracy: 82.6 |
| linguistic-acceptability-on-cola | LTG-BERT-small 24M | Accuracy: 77.6 |
| linguistic-acceptability-on-cola | ELC-BERT-small 24M | Accuracy: 76.1 |
| natural-language-inference-on-multinli | ELC-BERT-base 98M (zero init) | Matched: 84.4 Mismatched: 84.5 |
| natural-language-inference-on-multinli | ELC-BERT-small 24M | Matched: 79.2 Mismatched: 79.9 |
| natural-language-inference-on-multinli | LTG-BERT-small 24M | Matched: 78 Mismatched: 78.8 |
| natural-language-inference-on-multinli | LTG-BERT-base 98M | Matched: 83 Mismatched: 83.4 |
| natural-language-inference-on-rte | LTG-BERT-small 24M | Accuracy: 53.7 |
| natural-language-inference-on-rte | ELC-BERT-small 24M | Accuracy: 55.4 |
| natural-language-inference-on-rte | ELC-BERT-base 98M (zero init) | Accuracy: 63 |
| natural-language-inference-on-rte | LTG-BERT-base 98M | Accuracy: 54.7 |
Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.
AI Co-coding
Ready-to-use GPUs
Best Pricing
Hyper Newsletters
Subscribe to our latest updates
We will deliver the latest updates of the week to your inbox at nine o'clock every Monday morning
Powered by MailChimp