Revolutionizing Reinforcement Learning Framework for Diffusion Large
Language Models
Revolutionizing Reinforcement Learning Framework for Diffusion Large Language Models
Yinjie Wang Ling Yang Bowen Li Ye Tian Ke Shen Mengdi Wang
Abstract
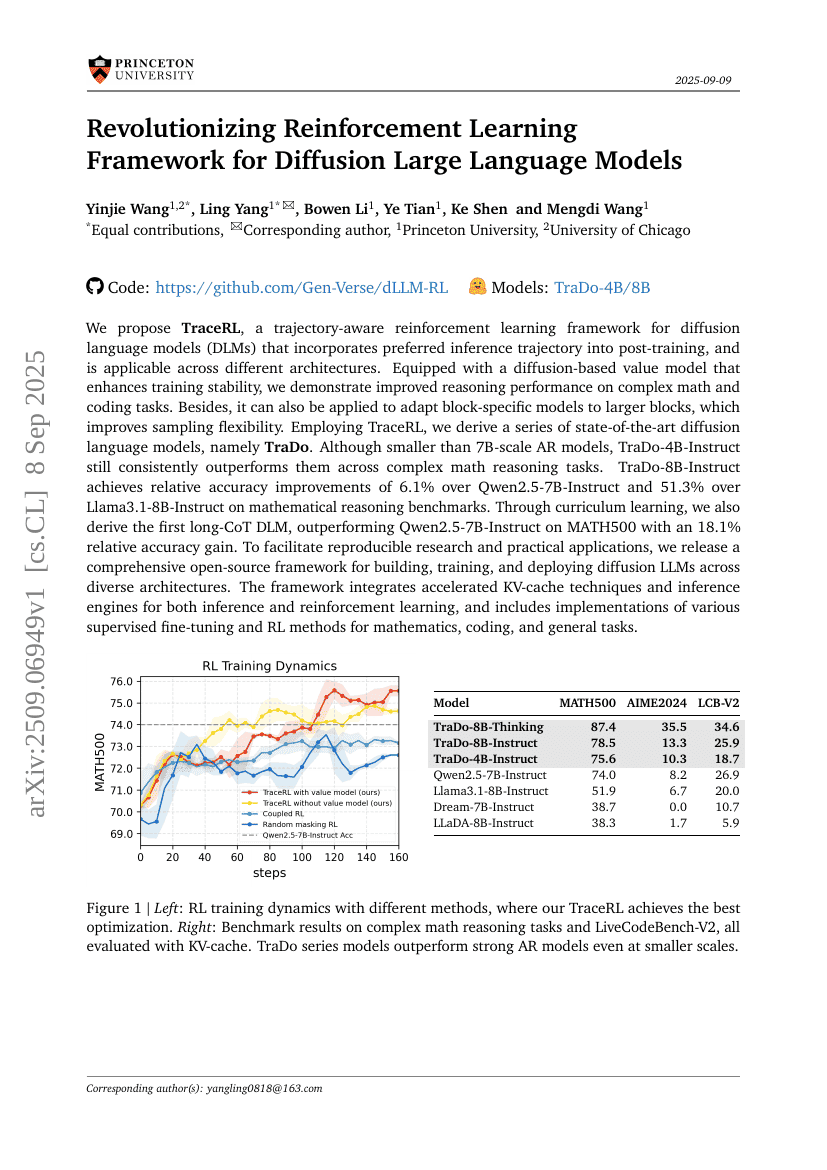
We propose TraceRL, a trajectory-aware reinforcement learning framework fordiffusion language models (DLMs) that incorporates preferred inferencetrajectory into post-training, and is applicable across differentarchitectures. Equipped with a diffusion-based value model that enhancestraining stability, we demonstrate improved reasoning performance on complexmath and coding tasks. Besides, it can also be applied to adapt block-specificmodels to larger blocks, which improves sampling flexibility. EmployingTraceRL, we derive a series of state-of-the-art diffusion language models,namely TraDo. Although smaller than 7B-scale AR models, TraDo-4B-Instruct stillconsistently outperforms them across complex math reasoning tasks.TraDo-8B-Instruct achieves relative accuracy improvements of 6.1% overQwen2.5-7B-Instruct and 51.3% over Llama3.1-8B-Instruct on mathematicalreasoning benchmarks. Through curriculum learning, we also derive the firstlong-CoT DLM, outperforming Qwen2.5-7B-Instruct on MATH500 with an 18.1%relative accuracy gain. To facilitate reproducible research and practicalapplications, we release a comprehensive open-source framework for building,training, and deploying diffusion LLMs across diverse architectures. Theframework integrates accelerated KV-cache techniques and inference engines forboth inference and reinforcement learning, and includes implementations ofvarious supervised fine-tuning and RL methods for mathematics, coding, andgeneral tasks. Code and Models: https://github.com/Gen-Verse/dLLM-RL
Code Repositories
Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.