Every Token Counts: Generalizing 16M Ultra-Long Context in Large Language Models
Every Token Counts: Generalizing 16M Ultra-Long Context in Large Language Models
Xiang Hu Zhanchao Zhou Ruiqi Liang Zehuan Li Wei Wu Jianguo Li
Abstract
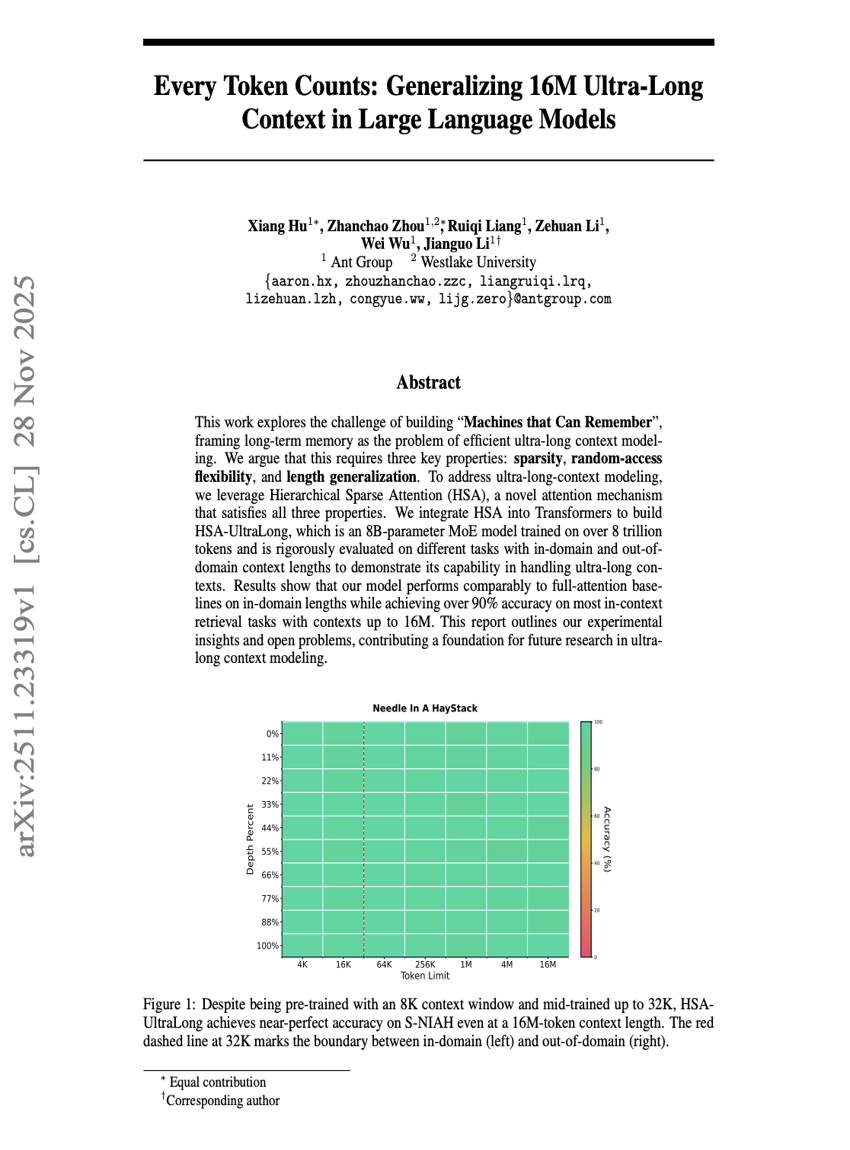
This work explores the challenge of building ``Machines that Can Remember'', framing long-term memory as the problem of efficient ultra-long context modeling. We argue that this requires three key properties: \textbf{sparsity}, \textbf{random-access flexibility}, and \textbf{length generalization}. To address ultra-long-context modeling, we leverage Hierarchical Sparse Attention (HSA), a novel attention mechanism that satisfies all three properties. We integrate HSA into Transformers to build HSA-UltraLong, which is an 8B-parameter MoE model trained on over 8 trillion tokens and is rigorously evaluated on different tasks with in-domain and out-of-domain context lengths to demonstrate its capability in handling ultra-long contexts. Results show that our model performs comparably to full-attention baselines on in-domain lengths while achieving over 90% accuracy on most in-context retrieval tasks with contexts up to 16M. This report outlines our experimental insights and open problems, contributing a foundation for future research in ultra-long context modeling.
Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.