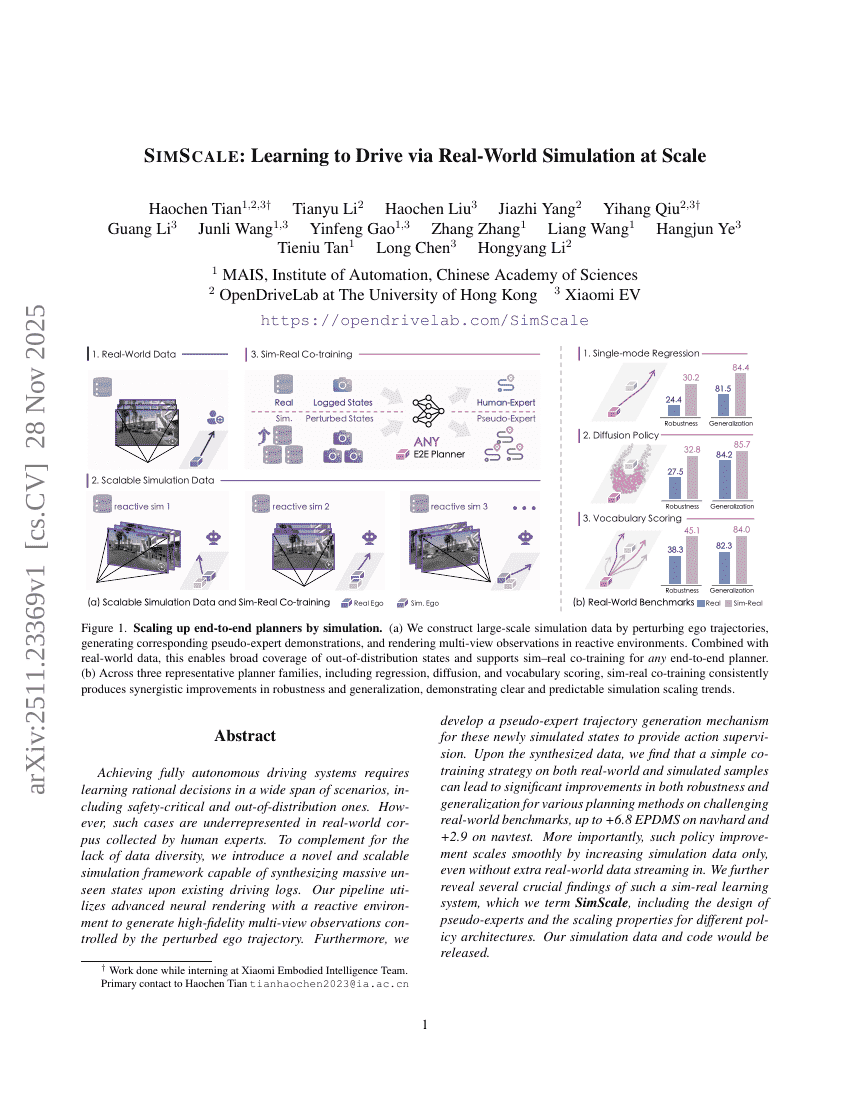
Abstract
Achieving fully autonomous driving systems requires learning rational decisions in a wide span of scenarios, including safety-critical and out-of-distribution ones. However, such cases are underrepresented in real-world corpus collected by human experts. To complement for the lack of data diversity, we introduce a novel and scalable simulation framework capable of synthesizing massive unseen states upon existing driving logs. Our pipeline utilizes advanced neural rendering with a reactive environment to generate high-fidelity multi-view observations controlled by the perturbed ego trajectory. Furthermore, we develop a pseudo-expert trajectory generation mechanism for these newly simulated states to provide action supervision. Upon the synthesized data, we find that a simple co-training strategy on both real-world and simulated samples can lead to significant improvements in both robustness and generalization for various planning methods on challenging real-world benchmarks, up to +6.8 EPDMS on navhard and +2.9 on navtest. More importantly, such policy improvement scales smoothly by increasing simulation data only, even without extra real-world data streaming in. We further reveal several crucial findings of such a sim-real learning system, which we term SimScale, including the design of pseudo-experts and the scaling properties for different policy architectures. Our simulation data and code would be released.
Summarization
Researchers from the Chinese Academy of Sciences, The University of Hong Kong, and Xiaomi EV introduce SimScale, a scalable simulation framework that leverages neural rendering and pseudo-expert trajectory generation to synthesize diverse unseen scenarios, thereby significantly enhancing the robustness and generalization of autonomous driving policies through sim-real co-training.
Introduction
End-to-end planning in autonomous driving relies heavily on data scaling to map raw observations directly to actions. While increasing dataset size typically drives performance, real-world driving logs are heavily skewed toward routine scenarios, leaving safety-critical or rare events underrepresented. Consequently, models trained solely on human demonstrations struggle to generalize to out-of-distribution (OOD) states, often leading to causal confusion during deployment. Although simulation offers a way to generate these rare scenarios, existing methods often fail to produce feasible expert demonstrations for OOD states or suffer from significant visual gaps that hinder transfer to the real world.
To address this, the authors introduce SimScale, a scalable closed-loop training framework that amplifies existing real-world datasets through high-fidelity simulation. By leveraging a 3D Gaussian Splatting (3DGS) engine, the system generates diverse, reactive driving scenarios that extend beyond the human expert distribution. The authors demonstrate that this approach allows planners to learn from synthetic data effectively, improving performance on challenging benchmarks without requiring additional real-world data collection.
Key innovations include:
- Pseudo-Expert Trajectory Generation: The system actively perturbs ego-vehicle trajectories (e.g., lane drifts) and employs recovery-based or privileged experts to generate feasible corrective actions, teaching the planner how to handle deviations.
- Photorealistic Sensor Simulation: Utilizing 3D Gaussian Splatting, the framework renders high-fidelity multi-view video from the ego perspective, bridging the visual gap between simulated logic and real-world sensory inputs.
- Scalable Sim-Real Co-training: A training strategy that progressively integrates non-overlapping simulation data with a fixed real-world corpus, yielding predictable performance gains in robustness and generalization across various planner architectures.
Dataset
The authors construct their dataset using a combination of publicly licensed real-world driving data and curated simulation scenarios designed to address out-of-distribution (OOD) challenges.
- Data Sources: Training and evaluation rely on established public datasets, specifically nuPlan, OpenScene, and NAVSIM v2.
- Simulation Composition: The simulation data focuses on four representative OOD scenarios where learned policies typically struggle: off-center lane drift, near collision, lane departure, and cutting-in cases.
- Data Structure: Each simulation sample consists of a synthetic front-view image for sensory input, a deviating Perturbed Trajectory representing history actions, and a Pseudo-Expert Trajectory used as supervision.
- Curation and Filtering: To ensure valid supervision, the authors discard infeasible candidates during the pseudo-expert trajectory generation process.
- Quality Metrics: The curation process enforces all sub-metrics of EPDMS. To prevent biased driving styles, the authors apply a specific relaxation to the EP score, requiring it to be greater than or equal to 0.5.
Method
The authors leverage a pseudo-expert scene simulation pipeline to generate diverse and feasible simulation data from real-world driving scenarios, enabling scalable sim-real co-training for end-to-end planning models. The framework operates in two main stages: trajectory perturbation and pseudo-expert trajectory generation, both relying on a photorealistic data engine for sensor rendering.
Refer to the framework diagram for an overview of the pipeline. The process begins with a real-world training clip, where the ego vehicle's state at timestep T is perturbed to generate a new terminal state at T+H. This perturbation step, illustrated in part (a) of the figure, samples from a clustered human-trajectory vocabulary to ensure diversity while enforcing physical and kinematic constraints to maintain plausibility. The perturbations are spatially sparse, using an interleaved grid to promote uniform coverage of the action space. This initial perturbation produces a set of dynamically and physically feasible states, which serve as the starting points for the next phase.
In the second stage, shown in part (b) of the figure, a pseudo-expert policy generates a corresponding trajectory from the perturbed state at T+H to T+2H. This stage employs two distinct strategies: a recovery-based expert and a planner-based expert. The recovery-based expert retrieves a human-like trajectory from a large vocabulary that best matches the ego's perturbed state, ensuring conservative and stable behavior. In contrast, the planner-based expert uses a privileged planner that leverages ground-truth states to generate optimized and reactive trajectory rollouts, offering greater diversity and exploration at the cost of occasional deviations from human-like behavior.
The simulation pipeline is decoupled into behavior simulation and sensor rendering. For each simulation step, the ego's trajectory is generated using a Linear Quadratic Regulator (LQR), while other agents are modeled using the Intelligent Driver Model (IDM) to ensure realistic interactions. The resulting future states are then rendered into multi-view videos using the data engine Φ, which takes camera intrinsics, extrinsics, and the positions and orientations of all vehicles as inputs. This decoupling allows the environment to react plausibly to the ego's actions, enhancing the realism and diversity of the generated data.

Experiment
- Evaluated three distinct planner paradigms (regression, diffusion, and scoring) on NAVSIM
navhardandnavtestbenchmarks, validating the model-agnostic effectiveness of sim-real co-training. - On the
navhardleaderboard, the GTRS-Dense (V2-99) model achieved a state-of-the-art EPDMS score of 47.2, while baseline models like LTF and DiffusionDrive saw performance gains exceeding 20%. - Data scaling analysis demonstrated that exploratory planner-based pseudo-experts outperform conservative recovery-based experts, particularly as the volume of simulation data increases.
- Comparison of architectures revealed that diffusion-based planners exhibit linear performance scaling with simulation data, whereas regression-based models saturate due to limited capabilities in handling multi-modality.
- Ablation studies confirmed that reactive traffic simulation significantly enhances training effectiveness compared to non-reactive simulation, delivering better results even with fewer generated samples.
- Multi-expert ensemble experiments showed that combining diverse pseudo-expert behaviors yields complementary benefits, improving EPDMS by up to 3.4 points on ResNet34 backbones.
- Scalability tests indicated that simulation data consistently improves performance across varying amounts of real-world training data, maintaining effectiveness from 10K up to 100K real scenarios.
The authors use simulation data with pseudo-expert supervision to enhance the performance of end-to-end driving models across three planner paradigms. Results show that incorporating simulation data significantly improves EPDMS scores, with the scoring-based GTRS-Dense model achieving a new SOTA of 47.2 on the NAVSIM-v2 navhard leaderboard, demonstrating the effectiveness of sim-real co-training.

The authors use simulation data to enhance the performance of end-to-end driving models across three planner paradigms. Results show that incorporating simulation data with pseudo-expert supervision significantly improves model performance on both the NAVSIM-v2 navhard and navtest benchmarks, with the scoring-based GTRS-Dense model achieving the highest EPDMS score of 84.6 on navtest.

The authors use simulation data generated from two types of pseudo-experts—recovery-based and planner-based—to evaluate the impact on model performance. Results show that incorporating simulation data with a planner-based expert consistently improves performance across both backbone architectures, with the V2-99 model achieving the highest EPDMS score of 47.2 when trained with both real and simulated data.

The authors compare the impact of reactive versus non-reactive traffic simulation on model performance, using EPDMS as the primary metric. Results show that reactive simulation with three rounds of sampling achieves higher EPDMS scores (44.8 and 46.6 for ResNet34 and V2-99, respectively) compared to non-reactive simulation (43.7 and 45.6), despite generating fewer simulation samples. This indicates that reactive agent dynamics enhance the realism and diversity of traffic interactions, leading to more effective simulation data.

Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.