
Abstract
Reinforcement learning (RL) has recently achieved remarkable success in eliciting visual reasoning within Multimodal Large Language Models (MLLMs). However, existing approaches typically train separate models for different tasks and treat image and video reasoning as disjoint domains. This results in limited scalability toward a multimodal reasoning generalist, which restricts practical versatility and hinders potential knowledge sharing across tasks and modalities. To this end, we propose OneThinker, an all-in-one reasoning model that unifies image and video understanding across diverse fundamental visual tasks, including question answering, captioning, spatial and temporal grounding, tracking, and segmentation. To achieve this, we construct the OneThinker-600k training corpus covering all these tasks and employ commercial models for CoT annotation, resulting in OneThinker-SFT-340k for SFT cold start. Furthermore, we propose EMA-GRPO to handle reward heterogeneity in multi-task RL by tracking task-wise moving averages of reward standard deviations for balanced optimization. Extensive experiments on diverse visual benchmarks show that OneThinker delivers strong performance on 31 benchmarks, across 10 fundamental visual understanding tasks. Moreover, it exhibits effective knowledge transfer between certain tasks and preliminary zero-shot generalization ability, marking a step toward a unified multimodal reasoning generalist. All code, model, and data are released.
Summarization
Researchers from MMLab, CUHK and Meituan introduce OneThinker, an all-in-one multimodal reasoning model that unifies image and video understanding across ten fundamental tasks by employing a novel EMA-GRPO strategy to handle reward heterogeneity in multi-task reinforcement learning, thereby achieving superior scalability and knowledge transfer compared to disjoint domain-specific models.
Introduction
Reasoning capabilities are becoming essential for advancing Multimodal Large Language Models (MLLMs) toward general intelligence, with recent approaches successfully applying reinforcement learning (RL) to enhance step-by-step inference. While models like Vision-R1 and Video-R1 have demonstrated success in specific domains, current research remains fragmented, typically isolating image processing from video understanding and restricting models to single tasks.
This separation limits the practical versatility of AI agents, as real-world scenarios require unified reasoning across both static and dynamic visual inputs. Furthermore, existing optimization algorithms struggle to handle the diverse reward characteristics found in heterogeneous tasks simultaneously. To address this, the authors present OneThinker, a unified multimodal generalist capable of executing a wide range of visual reasoning tasks, from question answering and captioning to spatial tracking and segmentation, within a single framework.
Key innovations include:
- Unified Data Strategy: The curation of the OneThinker-600k dataset and a high-quality Chain-of-Thought annotated subset, allowing the model to jointly learn spatial and temporal cues across both image and video modalities.
- EMA-GRPO Algorithm: A novel reinforcement learning method that employs task-wise exponential moving averages for reward normalization. This resolves optimization imbalances between tasks with sparse rewards (e.g., math) and those with dense rewards (e.g., detection).
- Cross-Task Generalization: By training on diverse fundamental tasks simultaneously, the model facilitates knowledge sharing, achieving superior performance on 31 benchmarks and exhibiting zero-shot generalization capabilities in unseen scenarios.
Dataset
Dataset Overview: OneThinker-600k and OneThinker-SFT-340k
The authors construct a specialized corpus designed to develop a unified multimodal reasoning generalist. The dataset construction process involves the following key components and strategies:
- Composition and Sources: The foundation of the training data is the OneThinker-600k corpus. This dataset aggregates samples from a broad range of public training datasets, carefully curated to ensure diversity across domains and difficulty levels. It covers both image and video modalities to support static and dynamic visual contexts.
- Task Coverage: The data spans a series of fundamental visual reasoning tasks, including rule-based and open-ended QA, captioning, tracking, segmentation, and various forms of grounding (spatial, temporal, and spatio-temporal).
- Formatting and Processing: For perception-oriented tasks like grounding and segmentation, the authors require the model to output responses in a predefined JSON schema. This standardization ensures consistent formatting and enables automatic, verifiable reward computation.
- Chain-of-Thought (CoT) Annotation: To enable effective Supervised Fine-Tuning (SFT) initialization, the authors employed the proprietary Seed1.5-VL model to generate CoT annotations on the OneThinker-600k corpus.
- Filtering and Final Subset: The generated annotations underwent task-specific filtering thresholds, rule-based checking, and quality validation to ensure accuracy. This process resulted in the OneThinker-SFT-340k subset, which serves as the high-quality, CoT-annotated foundation for training the model's reasoning capabilities.
Method
The authors leverage a unified text interface for all tasks, where the model generates an internal reasoning trace within <think> tags and produces a task-specific output within <answer> tags. This framework enables consistent processing across diverse modalities and tasks, with structured outputs for perception-oriented tasks allowing automatic parsing and verification. The overall reward is composed of an accuracy component Racc and a format reward Rformat, where the latter ensures adherence to a predefined schema for structured outputs.
For rule-based tasks such as multiple-choice, numerical, regression, math, and OCR, correctness is determined by direct equivalence or standard metrics. Multiple-choice, numerical, and math problems are evaluated based on answer equivalence, while regression tasks use Mean Relative Accuracy (MRA) to assess relative closeness across tolerance levels. OCR tasks employ Word Error Rate for evaluation. These deterministic rewards provide interpretable feedback suitable for reinforcement learning.
Open-ended question answering and captioning tasks utilize an external reward model to compute a similarity score between the predicted and reference answers. The authors adopt POLAR-7B as the reward model, which evaluates the semantic quality of the generated response. Temporal grounding tasks require the model to predict a continuous time segment, with accuracy measured by temporal intersection-over-union (tIoU) between the predicted and ground-truth intervals. Spatial grounding involves predicting a bounding box, with accuracy assessed using spatial IoU (sIoU). The combined task of spatial-temporal grounding computes accuracy as the sum of tIoU and the mean sIoU across frames. Tracking tasks measure accuracy as the mean IoU over the predicted trajectory of bounding boxes.
For segmentation, the model predicts a bounding box and a set of positive and negative points to guide object identification. These predictions are processed by SAM2 to generate the final segmentation mask. In video segmentation, a keyframe time is also predicted to determine when the annotations should be applied. The accuracy reward combines bounding box overlap with Gaussian kernel-based similarities over the point sets, where distances are normalized using a Gaussian function with task-specific parameters. A temporal Gaussian kernel is applied to the keyframe prediction in video segmentation.
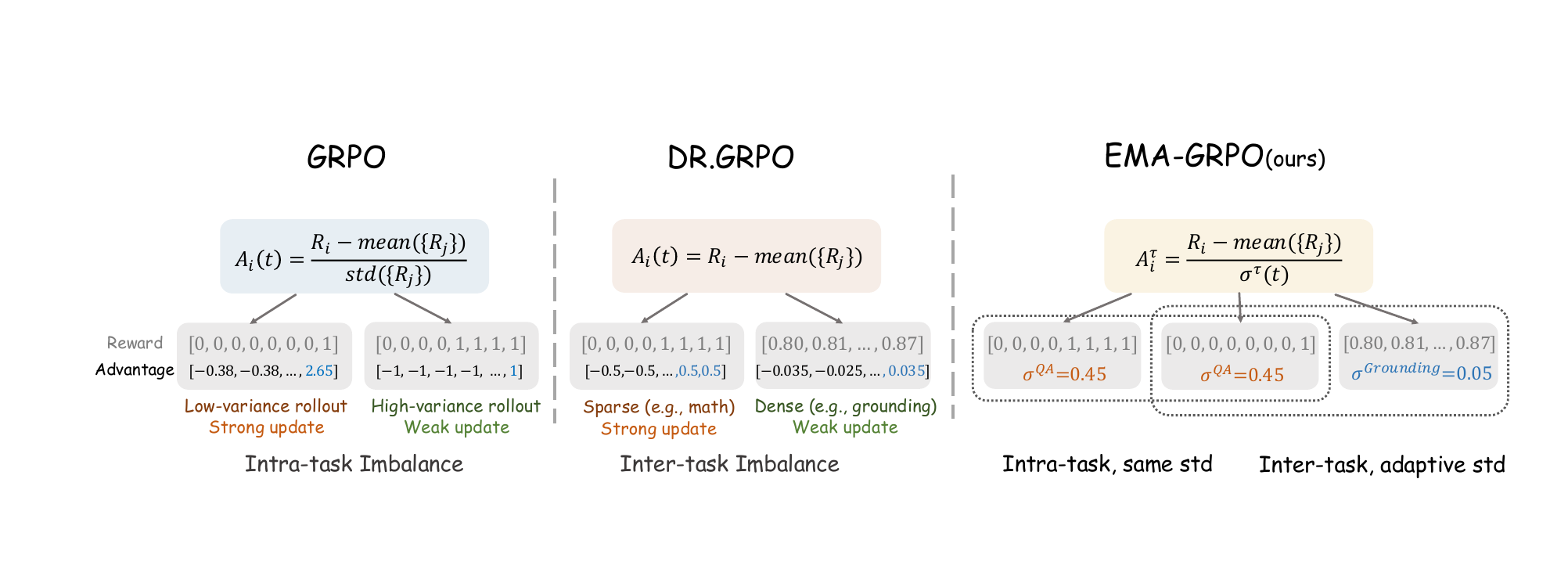
The reinforcement learning framework addresses two key imbalances in multi-task training. Standard GRPO normalizes rewards within each prompt group by the group standard deviation, which introduces intra-task imbalance by overemphasizing samples with extreme variance and under-optimizing medium-difficulty ones. Removing this normalization, as in Dr.GRPO, eliminates intra-task bias but creates inter-task imbalance, where sparse rewards dominate optimization and dense rewards are down-weighted. To resolve both issues, the authors propose EMA-GRPO, which uses exponential moving averages to maintain task-wise estimates of the first and second moments of reward distributions. These estimates are used to compute a task-specific standard deviation, which normalizes the advantage for each task. This adaptive normalization ensures fair learning across tasks with varying reward scales and densities while maintaining balanced optimization within each task.
The training objective follows the standard GRPO formulation, incorporating the EMA-normalized advantage. The policy update maximizes a clipped objective function that balances the ratio of new and old policy probabilities with the advantage, while also including a KL divergence term to prevent large policy updates. This approach promotes stable and effective optimization across the diverse set of visual reasoning tasks.



Experiment
- Comprehensive Evaluation: The OneThinker-8B model, trained via SFT and RL with EMA-GRPO, was assessed across diverse visual reasoning tasks including QA, captioning, grounding, tracking, and segmentation.
- QA Dominance: In Image QA, the model achieved 70.6% on MMMU and 77.6% on MathVista, surpassing Vision-R1-7B; in Video QA, it reached 79.2% on LongVideo-Reason, significantly outperforming Video-R1-7B (67.2%).
- Localization and Tracking: The model demonstrated superior grounding capabilities, attaining 65.0 [email protected] on ActivityNet (temporal) and 93.7 on RefCOCO testA (spatial), while achieving 73.0 AO on the GOT-10k tracking benchmark.
- Segmentation Results: OneThinker secured top performance in segmentation tasks, recording 75.8 cIoU on RefCOCO val and 52.7 J&F on MeViS, outperforming baselines like PixelLM-7B and Seg-R1-7B.
- Ablation and Analysis: Experiments validated the EMA-GRPO algorithm over standard GRPO and SFT-only baselines, while data exclusion tests confirmed that joint training on diverse tasks facilitates cross-modal knowledge transfer (e.g., ImageQA improving Video QA).
- Generalization: The model exhibited strong zero-shot capabilities on unseen MMT-Bench tasks, such as point tracking and GUI navigation, surpassing the Qwen3-VL-Instruct-8B base model.
The authors use a unified training framework to evaluate OneThinker-8B across multiple visual reasoning tasks, including image and video question answering, captioning, grounding, tracking, and segmentation. Results show that OneThinker-8B achieves state-of-the-art performance on most benchmarks, outperforming prior models such as Qwen3-VL-Instruct-8B and specialized video reasoning models, demonstrating strong generalization and transferability across tasks and modalities.

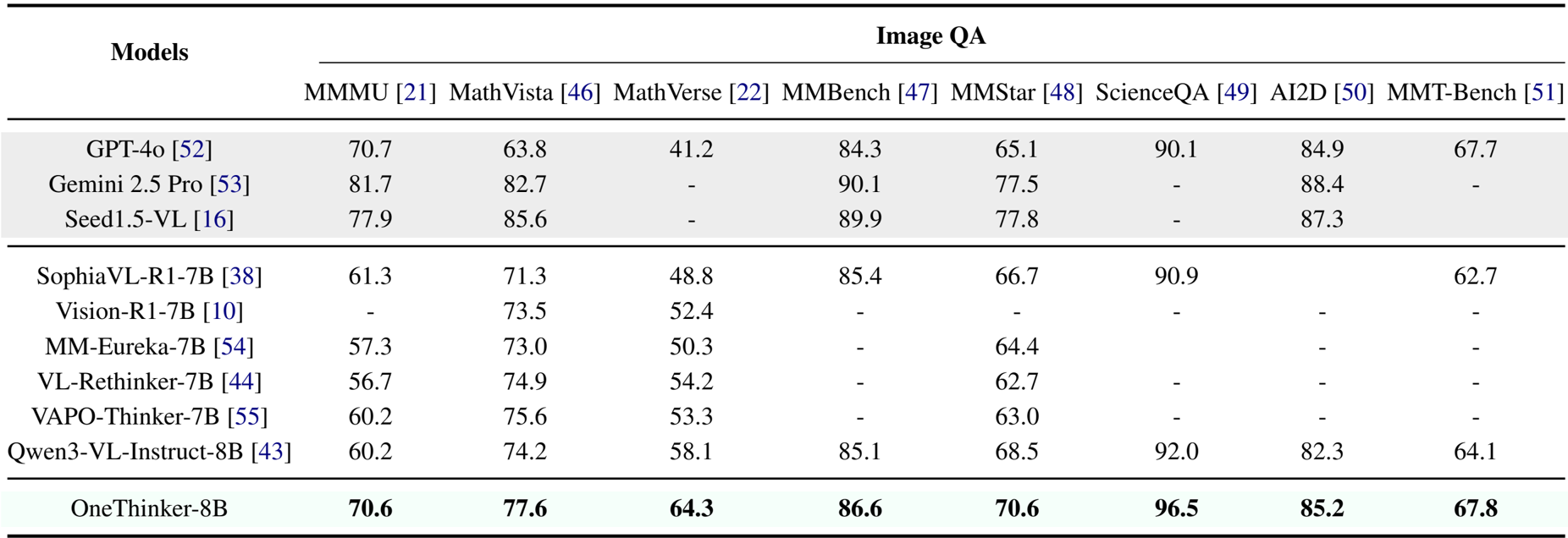
The authors use the OneThinker-8B model to evaluate performance on image question answering across multiple benchmarks. Results show that OneThinker-8B achieves top-tier results, outperforming prior open-source models such as Qwen3-VL-Instruct-8B and Vision-R1-7B on all tested tasks, including MMMU, MathVista, MathVerse, and ScienceQA.
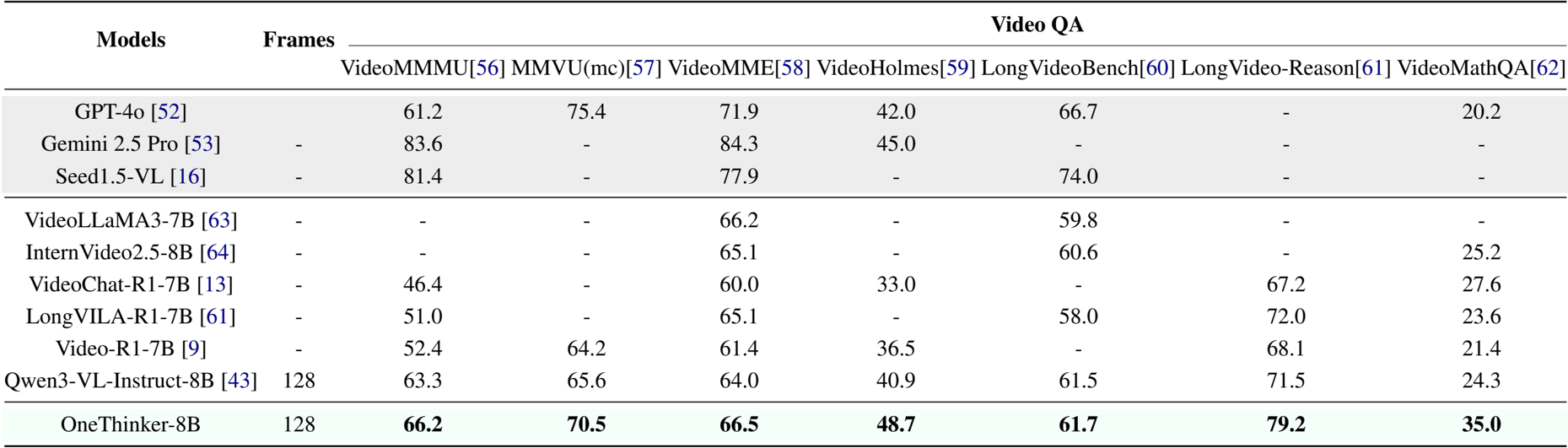
The authors use OneThinker-8B to evaluate performance on video question answering across multiple benchmarks. Results show that OneThinker-8B achieves the highest scores on VideoMMMU, MMVU(mc), VideoMME, and LongVideo-Reason, outperforming models such as GPT-4o, Gemini 2.5 Pro, and Qwen3-VL-Instruct-8B. It also leads on VideoMathQA with a score of 35.0, demonstrating strong reasoning capabilities in complex video understanding tasks.
The authors use the table to compare the performance of OneThinker-8B with other models on image and video captioning tasks. Results show that OneThinker-8B achieves the highest scores on both MMT-Caption and VideoMMLU-Caption, outperforming Qwen3-VL-Instruct-8B and LLaVA-1.5-7B, while GPT-4o leads on MMSsci-Caption and VideoMMLU-Caption.

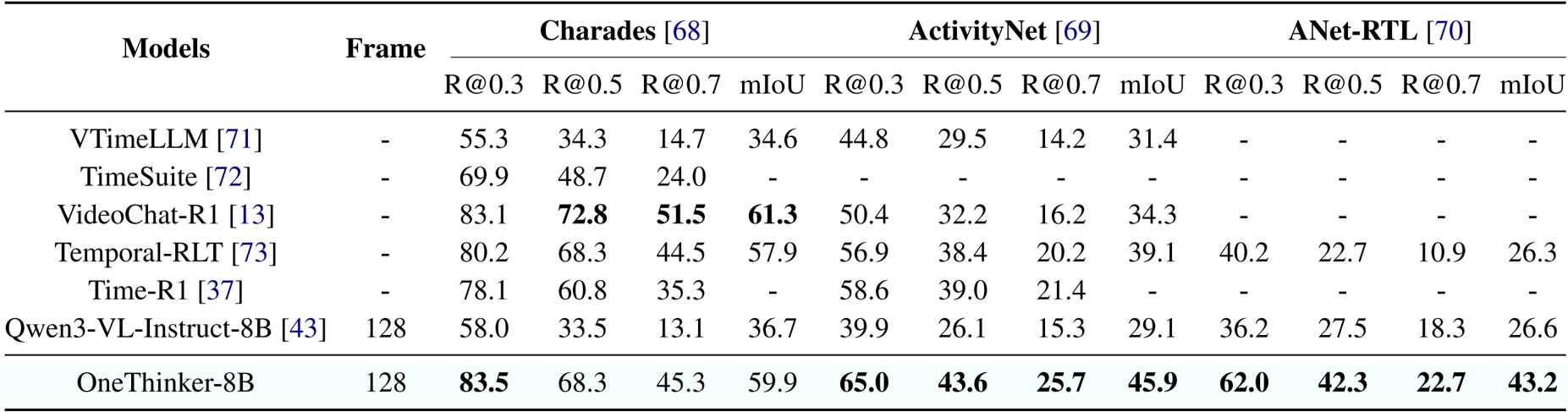
The authors use the table to compare OneThinker-8B against several existing models on temporal grounding tasks across Charades, ActivityNet, and ANet-RTL benchmarks. Results show that OneThinker-8B achieves the highest performance on Charades, with 83.5 [email protected] and 68.3 [email protected], and leads on ActivityNet with 65.0 [email protected] and 43.6 [email protected], while also attaining the best mIoU of 43.2 on ANet-RTL.
Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.