One-click Deployment of DeepSeek-R1-70B
1. Tutorial Introduction

DeepSeek-R1-Distill-Llama-70B is an open-source large language model released by DeepSeek in 2025, boasting a parameter scale of 70 billion. Trained on Llama3.3-70B-Instruct, it employs reinforcement learning and distillation techniques to enhance inference performance. It not only inherits the advantages of the Llama series models but also further optimizes inference capabilities, particularly excelling in mathematical, code, and logical reasoning tasks. As a high-performance version of the DeepSeek series, it performs exceptionally well in multiple benchmark tests. Furthermore, this model is an inference-enhanced model provided by DeepSeek AI, supporting various application scenarios such as mobile devices and edge computing, and online inference services, to improve response speed and reduce operating costs. It possesses very powerful inference and decision-making capabilities. In fields such as advanced AI assistants and scientific research analysis, it can provide extremely professional and in-depth analytical results. For example, in medical research, version 70B can analyze large amounts of medical data, providing valuable references for disease research.
本教程使用 Ollama + Open WebUI 部署 DeepSeek-R1-Distill-Qwen-70B 作为演示,算力资源采用「单卡 A6000」。
2. Operation steps
1. After starting the container, click the API address to enter the web interface (if "Bad Gateway" is displayed, it means the model is initializing. Since the model is large, please wait about 5 minutes and try again.) 2. After entering the web page, you can start a conversation with the model!
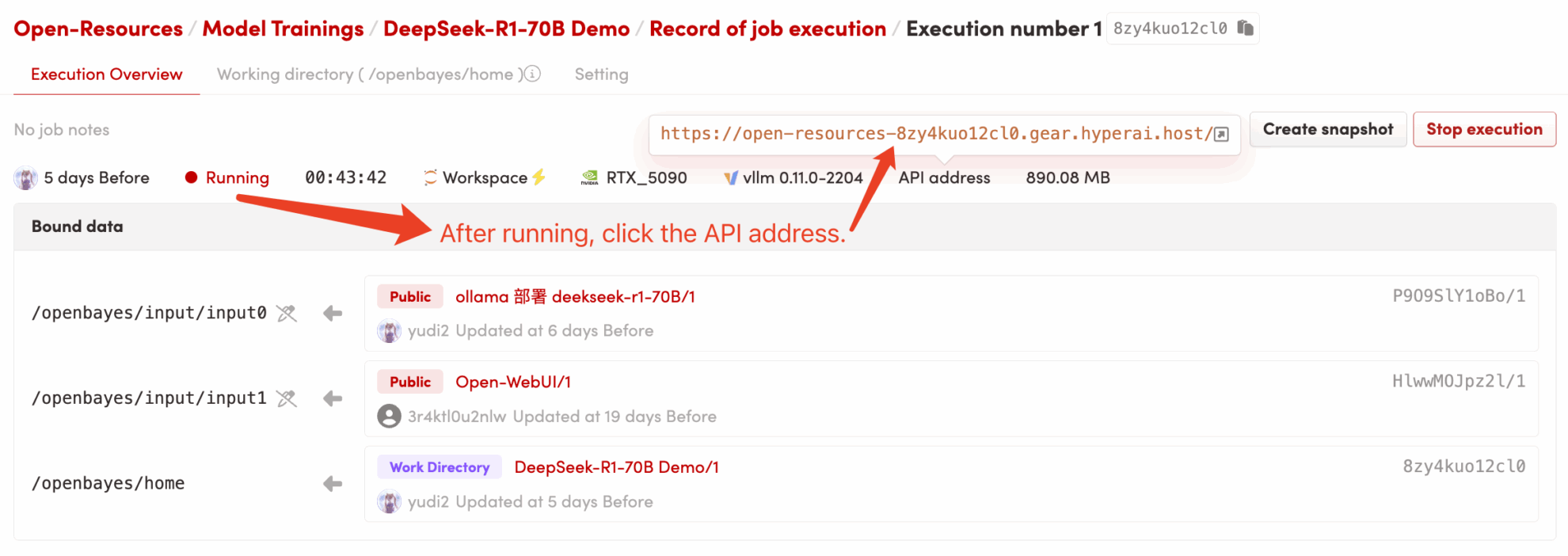
2. After entering the webpage, you can start a conversation with the model
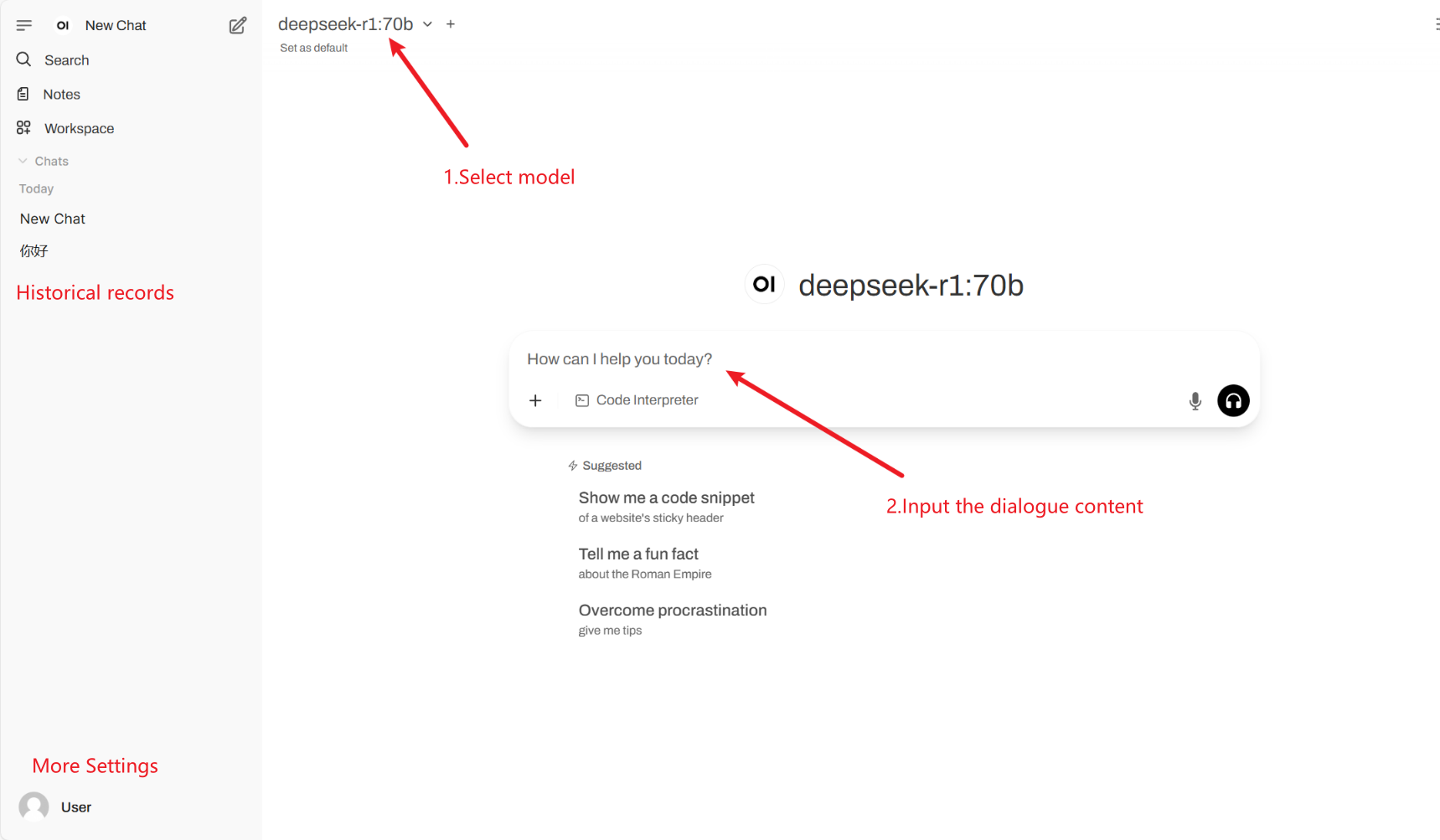
Common conversation settings
1. Temperature
- Controls the randomness of the output, typically in the range of 0.0-2.0.
- Low value (such as 0.1): More certain, biased towards common words.
- High value (such as 1.5): More random, potentially more creative but erratic content.
2. Top-k Sampling
- Sample only from the k words with the highest probability, excluding low-probability words.
- k is small (e.g. 10): More certainty, less randomness.
- k is large (e.g. 50): More diversity, more innovation.
3. Top-p Sampling (Nucleus Sampling, Top-p Sampling)
- Select the word set whose cumulative probability reaches p, and do not fix the value of k.
- Low value (such as 0.3): More certainty, less randomness.
- High value (such as 0.9): More diversity, improved fluency.
4. Repetition Penalty
- Controls the text repetition rate, usually between 1.0-2.0.
- High value (such as 1.5): Reduce repetition and improve readability.
- Low value (such as 1.0): No penalty, may cause the model to repeat words and sentences.
5. Max Tokens (maximum generation length)
- Limit the maximum number of tokens generated by the model to avoid excessively long output.
- Typical range: 50-4096 (depending on the specific model).
Quote
@misc{deepseekai2025deepseekr1incentivizingreasoningcapability,
title={DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning},
author={DeepSeek-AI},
year={2025},
eprint={2501.12948},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2501.12948},
}Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.