PixelReasoner-RL: Pixel-level Visual Inference Model
1. Tutorial Introduction
PixelReasoner-RL-v1 is a groundbreaking visual language model released by TIGER AI Lab in May 2025. The related paper is titled "Pixel Reasoner: Incentivizing Pixel-Space Reasoning with Curiosity-Driven Reinforcement Learning".
This project, based on the Qwen2.5-VL architecture, breaks through the limitations of traditional visual language models that rely solely on text-based reasoning through an innovative curiosity-driven reinforcement learning training method. PixelReasoner can perform reasoning directly in pixel space, supporting visual operations such as scaling and frame selection, significantly improving its ability to understand image details, spatial relationships, and video content.
Core features:
- Pixel-level inference: The model can be analyzed and manipulated directly in the image pixel space.
- Combining global and local understanding: enabling you to grasp the overall content of an image while also zooming in to focus on specific areas.
- Curiosity-Driven Training: Introducing a curiosity reward mechanism to incentivize the model to actively explore pixel-level operations.
- Enhanced reasoning ability: Excellent performance on complex visual tasks, including small object recognition and understanding subtle spatial relationships.
This tutorial uses Grado to deploy PixelReasoner-RL-v1 as a demonstration, with computing power resources of a single RTX 5090 card.
2. Effect display
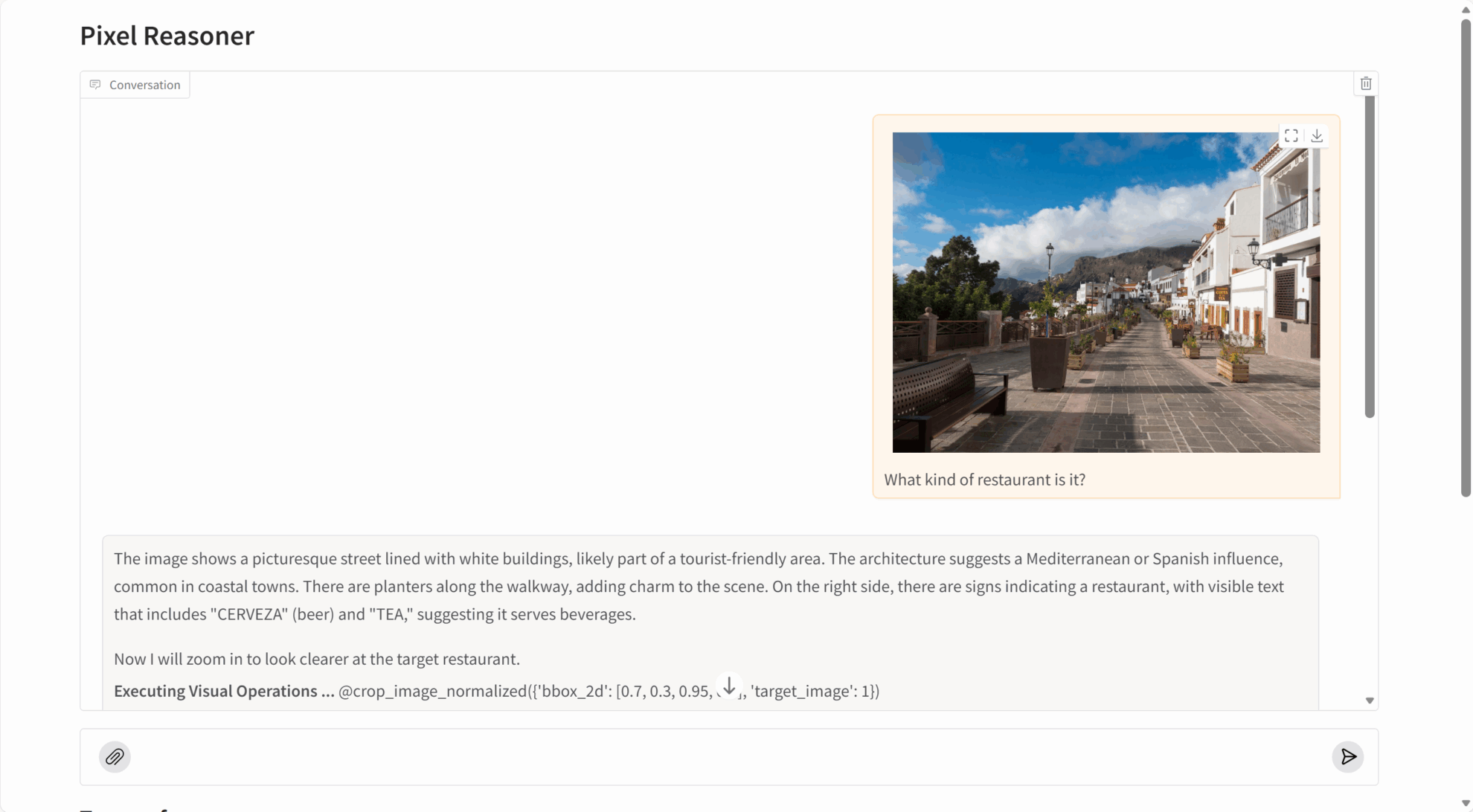
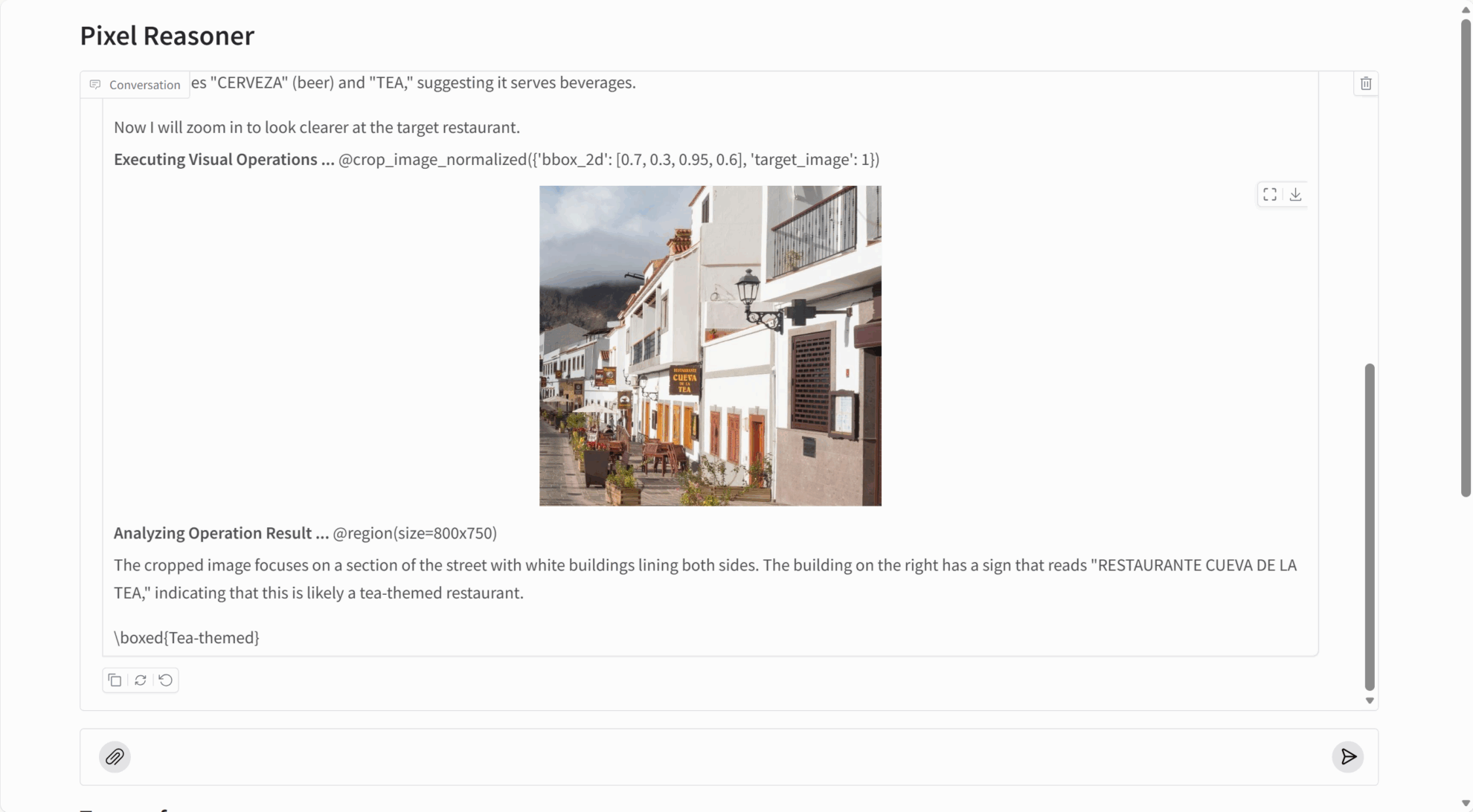
PixelReasoner-RL-v1 performs exceptionally well on multiple visual reasoning tasks:
- Image understanding: accurately identifying image content, object relationships, and scene details.
- Detail capture: Capable of discovering minute objects, embedded text, and other fine information in images.
- Video analytics: Understanding video content and action sequences by selecting keyframes.
- Spatial reasoning: accurately understanding the spatial position and relative relationships of objects.
3. Operation steps
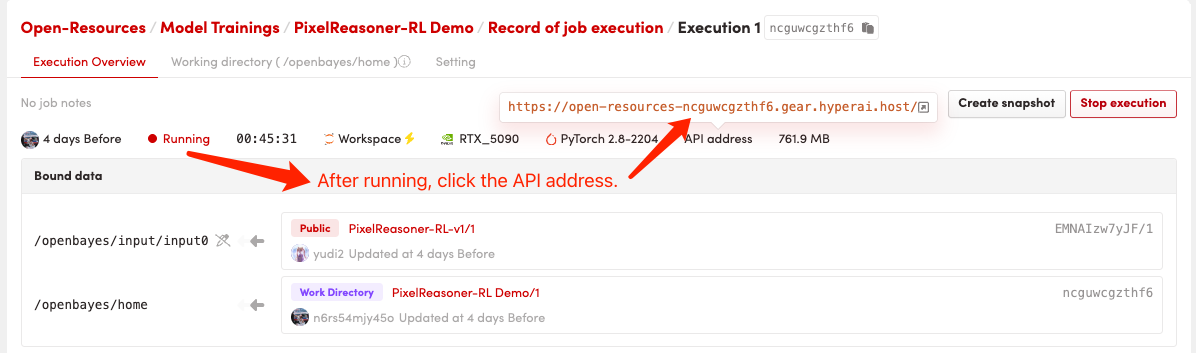
1. Start the container
After starting the container, click the API address to enter the Web interface
The initial startup will take approximately 2-3 minutes; please be patient. Once deployment is complete, click the "API Address" to directly access the Grado interface.
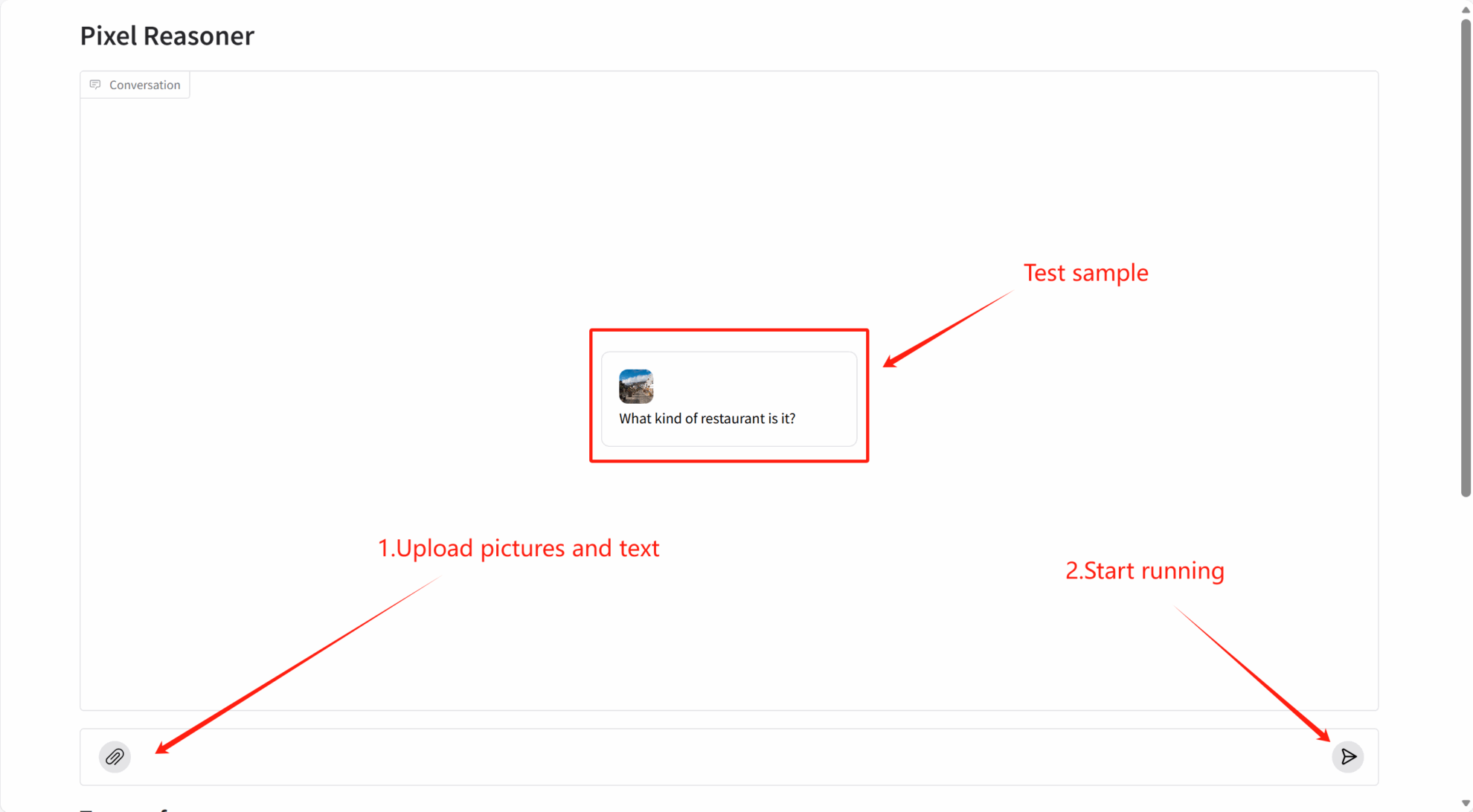
2. Getting Started
Citation Information
The citation information for this project is as follows:
@article{pixelreasoner2025,
title={Pixel Reasoner: Incentivizing Pixel-Space Reasoning with Curiosity-Driven Reinforcement Learning},
author={Su, Alex and Wang, Haozhe and Ren, Weiming and Lin, Fangzhen and Chen, Wenhu},
journal={arXiv preprint arXiv:2505.15966},
year={2025}
}Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.