One-click Deployment of SmolLM3-3B-Model
1. Tutorial Introduction

SmolLM3-3B was open-sourced and released by the Hugging Face TB (Transformer Big) team in July 2025, positioned as the "ceiling of edge performance." Related research papers include...SmolLM3: smol, multilingual, long-context reasonerIt is a revolutionary open-source language model with 3 billion parameters, designed to break through the performance limits of small models in a compact 3B size.
This tutorial uses a single RTX 5090 (32 GB) graphics card and a PyTorch 2.8 + CUDA 12.8 installation environment. The estimated loading time for the Gradio application is 2-3 minutes.
2. Project Examples
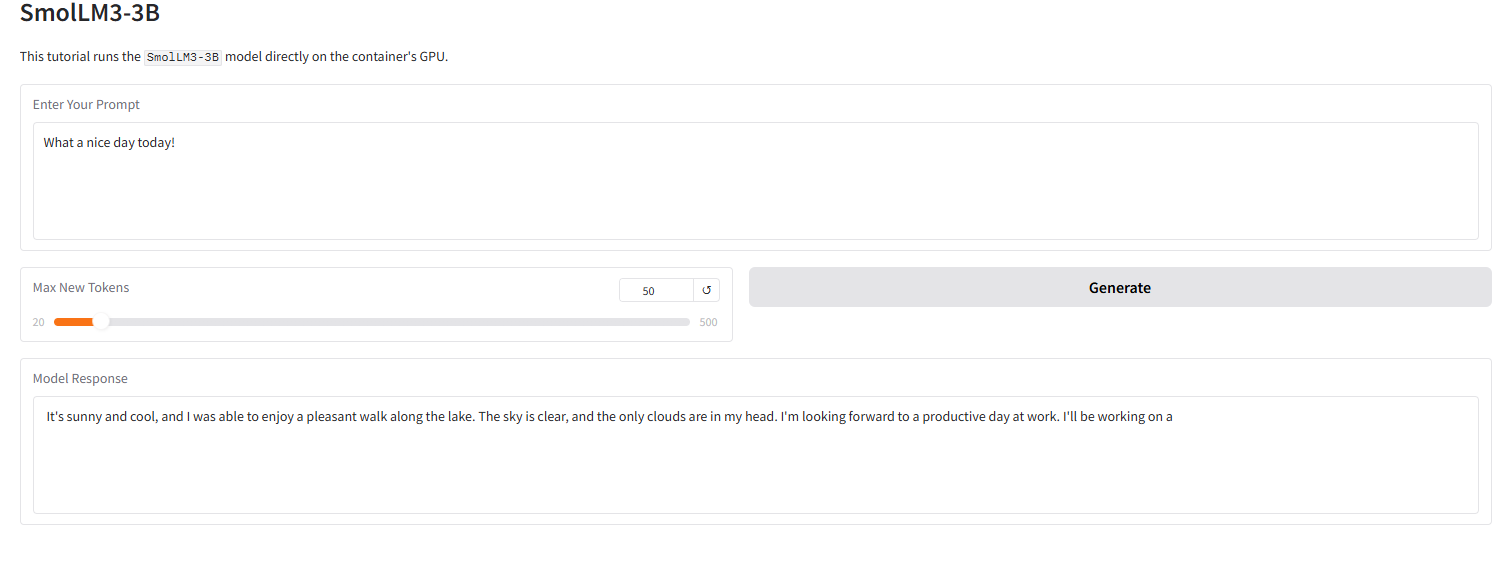
The image below shows the effect of the Grado interface in this tutorial. We entered a prompt word, and the model successfully provided a 4-bit quantized response.
3. Operation steps
This section includes instructions for one-click startup, the code directory structure, and frequently asked questions.
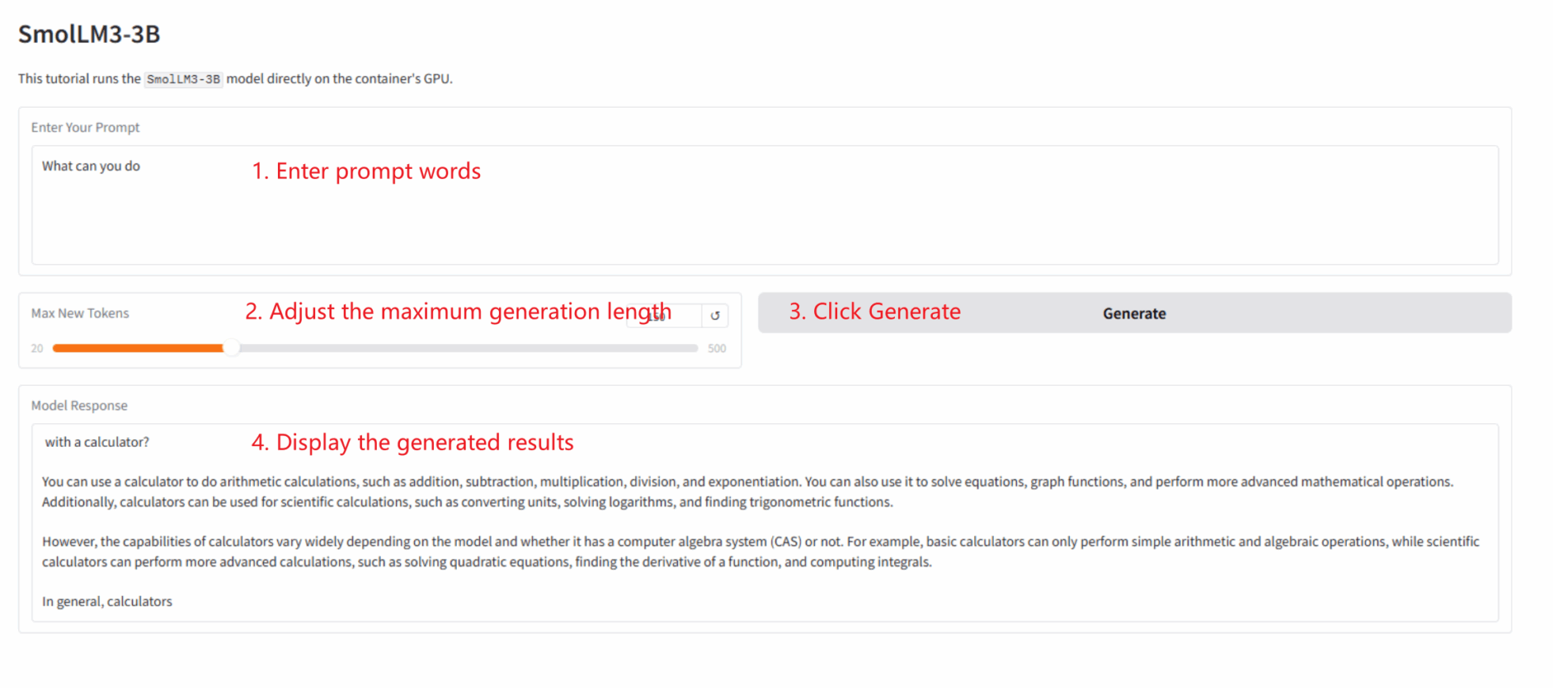
This tutorial demonstrates how to deploy a Gradio app with a single click. Users do not need to execute any code; simply follow these steps:
1. Cloning tutorial: Click "Clone" in the upper right corner of this page to create your personal container.
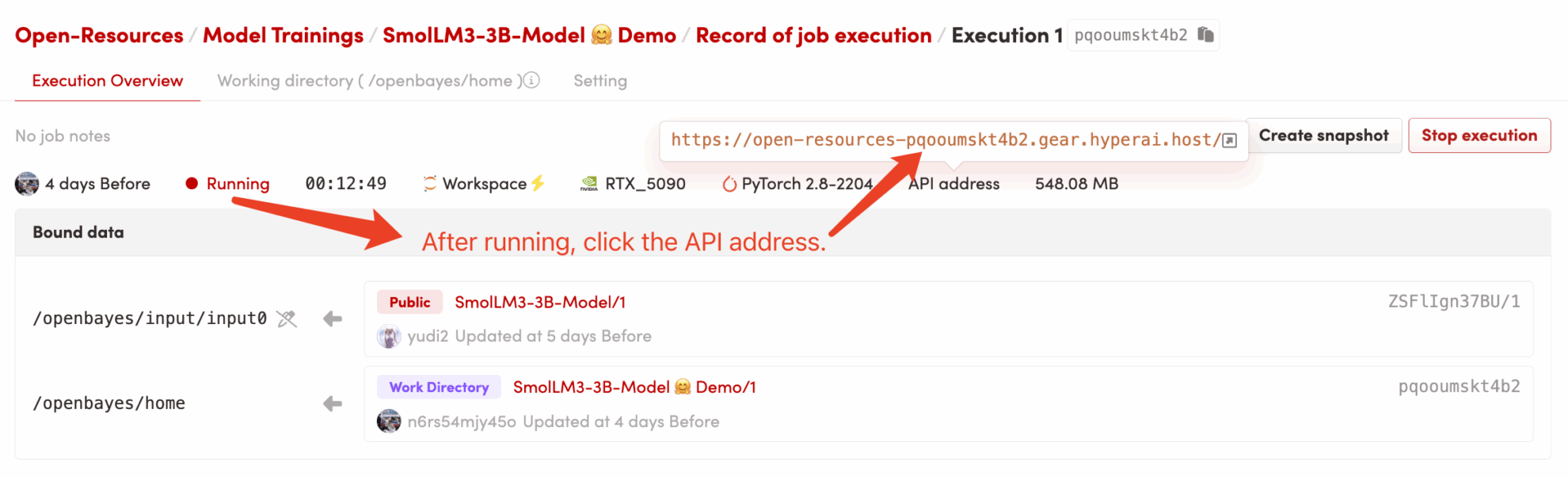
2. Start the container and wait: The system will automatically start the container for you (recommended). RTX 5090). dependencies.sh The script will run automatically in the background, loading the 4-bit quantization model.This process takes about 2-3 minutes.
3. Access the application: Once the container status changes to "Running", click "API Address" on the container details page to open the Grado interface.
Code directory structure
/openbayes/home |-- app.py \# Gradio 应用的启动脚本 |-- requirements.txt \# 锁定的 Python 依赖包 (已预装) |-- dependencies.sh \# 平台自动化执行脚本 (仅启动 app) |-- README\_cn.md \# 本教程说明文档 (中文) \`-- README\_en.md \# 本教程说明文档 (英文) /openbayes/input/input0 # 只读绑定的 SmolLM3-3B 模型文件
Frequently asked questions
- Q: After clicking "API Address", the page fails to load or displays "502"? A: This is because the model is loading.
SmolLM3-3BIt's a large model; even the 4-bit quantized version takes 2-3 minutes to fully load onto the GPU. Please wait a few minutes before refreshing the page. - Q: The log shows
OSError: Cannot find empty port 8080? A: This is because you (or your system) have tried to start the application multiple times, causing port 8080 to be occupied by a "zombie process". You only need to run it in a container terminal.pkill -f "python /openbayes/home/app.py"Clean up old processes and then rerun them.bash /openbayes/home/dependencies.shThat's all.
Citation Information
@misc{bakouch2025smollm3,
title={{SmolLM3: smol, multilingual, long-context reasoner}},
author={Bakouch, Elie and Ben Allal, Loubna and Lozhkov, Anton and Tazi, Nouamane and Tunstall, Lewis and Patiño, Carlos Miguel and Beeching, Edward and Roucher, Aymeric and Reedi, Aksel Joonas and Gallouédec, Quentin and Rasul, Kashif and Habib, Nathan and Fourrier, Clémentine and Kydlicek, Hynek and Penedo, Guilherme and Larcher, Hugo and Morlon, Mathieu and Srivastav, Vaibhav and Lochner, Joshua and Nguyen, Xuan-Son and Raffel, Colin and von Werra, Leandro and Wolf, Thomas},
year={2025},
howpublished={\url{[https://huggingface.co/blog/smollm3](https://huggingface.co/blog/smollm3)}}
}Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.