Command Palette
Search for a command to run...
A Neural Representation of Sketch Drawings
A Neural Representation of Sketch Drawings
David Ha Douglas Eck
Sketch-RNN: A Generative Model for Vector Drawings
Abstract
We present sketch-rnn, a recurrent neural network (RNN) able to construct stroke-based drawings of common objects. The model is trained on a dataset of human-drawn images representing many different classes. We outline a framework for conditional and unconditional sketch generation, and describe new robust training methods for generating coherent sketch drawings in a vector format.
One-sentence Summary
The authors present sketch-rnn, a recurrent neural network trained on a dataset of human-drawn images to construct stroke-based drawings of common objects, outlining a framework for conditional and unconditional sketch generation and describing new robust training methods for generating coherent sketch drawings in a vector format.
Key Contributions
- The paper introduces sketch-rnn, a recurrent neural network able to construct stroke-based drawings of common objects in a vector format. This model is trained on a dataset of human-drawn images representing many different classes.
- A framework for conditional and unconditional sketch generation is presented alongside new robust training methods for generating coherent vector drawings. This approach develops a training procedure unique to vector images and explores the latent space to represent vector images within the conditional generation model.
- A large dataset of hand-drawn vector images is made publicly available to encourage further development of generative modelling for vector images. An implementation of the model is also released as an open source project.
Introduction
While recent advancements in generative modeling have primarily focused on pixel-based images, humans typically represent visual concepts through sequential vector strokes. Enabling machines to generate vector drawings facilitates abstract conceptual understanding and creative applications such as assisting artists or teaching drawing techniques. Prior work largely attempted to mimic digitized photographs or lacked robust neural network approaches for vector data, often hindered by a scarcity of public datasets. To address this, the authors propose a recurrent neural network-based framework capable of unconditional and conditional generation of vector images, introducing a unique training procedure alongside a large dataset and open-source implementation.
Dataset
- Dataset Composition and Sources
- The authors constructed QuickDraw using vector drawings from the Quick, Draw! online game.
- Players in the game draw common objects within a 20-second time limit.
- The dataset spans hundreds of classes, beginning with an initial set of 75 categories.
- Subset Details and Splits
- Each class contains 70,000 training samples along with 2,500 validation and 2,500 test samples.
- Data is stored as vector drawings representing a sequence of pen stroke actions.
- Data Representation and Processing
- Sketches are encoded as lists of points where each point is a 5-element vector.
- The vector includes x and y offsets plus a 3-state one-hot vector indicating pen status.
- Pen states specify if the pen is down to draw, lifted after the point, or if the drawing has ended.
- Stroke simplification was applied using the Ramer Douglas Peucker algorithm with a parameter of 2.0.
- Offsets were normalized to a standard deviation of 1 using a scaling factor derived from the training set.
- Zero mean normalization was omitted because the original offset means were already small.
Method
The authors present Sketch-RNN, a Sequence-to-Sequence Variational Autoencoder (VAE) designed to construct stroke-based drawings of common objects. The model is trained on a dataset of human-drawn images representing many different classes. The overall architecture consists of an encoder that compresses an input sketch into a latent vector and a decoder that generates a new sketch conditioned on this vector.
Refer to the framework diagram below to visualize the complete pipeline, which includes the bidirectional encoder, the latent variable sampling, and the autoregressive decoder.
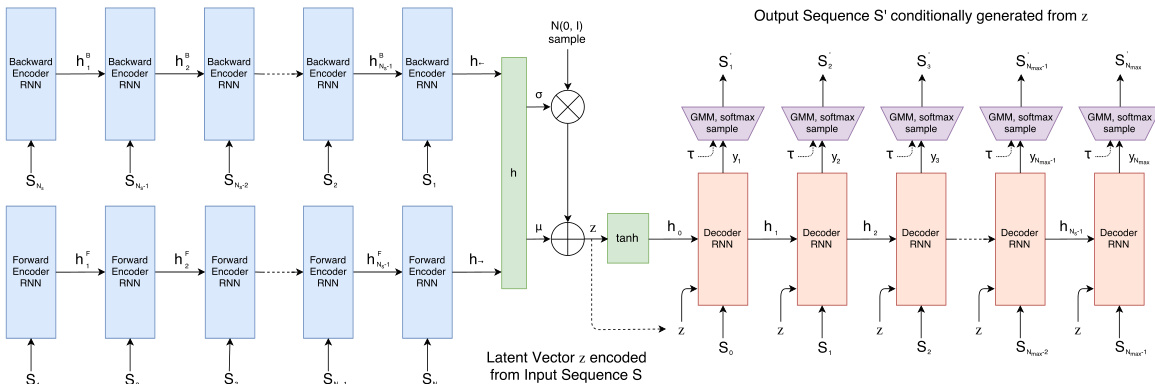
The encoder utilizes a bidirectional Recurrent Neural Network (RNN) to process the input sketch sequence S. It feeds the sequence in its original order into a forward RNN and in reverse order into a backward RNN. The final hidden states from both directions are concatenated to form a comprehensive representation h. This representation is then projected into two vectors, μ and σ^, which define the mean and log-variance of the latent distribution. Using the reparameterization trick, a random latent vector z is sampled as z=μ+σ⊙N(0,I), ensuring the model remains differentiable during training.
The input data is represented as a sequence of vectors containing (Δx,Δy) coordinates and pen state flags.

The decoder is an autoregressive RNN that generates the output sequence S′ step by step. At each time step i, the decoder takes the previous point Si−1 and the latent vector z as input. The output at each step consists of parameters for a probability distribution over the next point. Specifically, the spatial offsets (Δx,Δy) are modeled using a Gaussian Mixture Model (GMM) with M components, while the pen state (start, continue, end) is modeled using a categorical distribution. This probabilistic output allows the model to generate diverse and coherent sketches rather than a single deterministic path.
To train the model, the authors optimize a loss function composed of two terms: the Reconstruction Loss (LR) and the Kullback-Leibler Divergence Loss (LKL). The reconstruction loss maximizes the log-likelihood of the generated probability distribution matching the training data. The KL loss ensures that the distribution of the latent vector z remains close to a standard Gaussian prior. To balance these objectives and prevent the model from ignoring the latent code, they employ an annealing strategy where the weight of the KL term is gradually increased during training.
During the sampling process, the level of randomness can be controlled using a temperature parameter τ. This parameter scales the logits of the categorical distribution and the variances of the Gaussian components. Lower values of τ make the model more deterministic, while higher values increase diversity. The latent space also supports semantic arithmetic and interpolation.
As shown in the figure below, interpolating between latent vectors of different sketches results in smooth transitions between shapes, and vector arithmetic can be performed to manipulate attributes of the generated drawings.

Experiment
Experiments evaluate Sketch-RNN on various QuickDraw classes for both conditional and unconditional generation while varying KL loss weights and temperature parameters. Qualitative assessments demonstrate that the model preserves input sketch properties during reconstruction and enables smooth concept morphing through latent space interpolation and vector arithmetic. Results indicate that higher KL loss weights produce more coherent images and meaningful latent features, although performance degrades with highly complex sketches or large multi-class datasets.
The authors evaluate the sketch-rnn model on various single and multi-class datasets by varying the weight parameter wKL. Results indicate a tradeoff where lowering the wKL weight reduces the reconstruction loss (LR) but increases the KL loss (LKL). The conditional models consistently achieve lower reconstruction loss compared to the standalone decoder-only baseline. Relaxing the wKL parameter leads to a decrease in reconstruction loss (LR) while simultaneously causing the KL loss (LKL) to increase across all datasets. Conditional models consistently demonstrate lower reconstruction loss values than the unconditional decoder-only model across all tested classes. The trend of decreasing reconstruction loss and increasing KL loss remains consistent whether training on single classes or multi-class combinations.
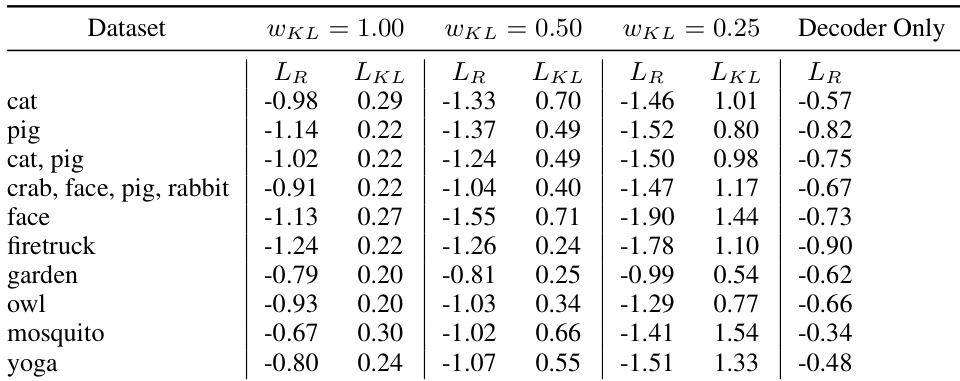
The study evaluates the sketch-rnn model across single and multi-class datasets by varying the wKL weight parameter. Experiments reveal a consistent tradeoff where lowering the weight reduces reconstruction loss while increasing KL loss, regardless of the training configuration. Furthermore, conditional models consistently achieve lower reconstruction loss compared to the unconditional decoder-only baseline.