Command Palette
Search for a command to run...
Streaming Sequence-to-Sequence Learning with Delayed Streams Modeling
Streaming Sequence-to-Sequence Learning with Delayed Streams Modeling
Neil Zeghidour Eugene Kharitonov Manu Orsini Václav Volhejn Gabriel de Marmiesse Edouard Grave Patrick Pérez Laurent Mazaré Alexandre Défossez
Abstract
We introduce Delayed Streams Modeling (DSM), a flexible formulation for streaming, multimodal sequence-to-sequence learning. Sequence-to-sequence generation is often cast in an offline manner, where the model consumes the complete input sequence before generating the first output timestep. Alternatively, streaming sequence-to-sequence rely on learning a policy for choosing when to advance on the input stream, or write to the output stream. DSM instead models already time-aligned streams with a decoder-only language model. By moving the alignment to a pre-processing step, and introducing appropriate delays between streams, DSM provides streaming inference of arbitrary output sequences, from any input combination, making it applicable to many sequence-to-sequence problems. In particular, given a text and audio stream, automatic speech recognition (ASR) corresponds to the text stream being delayed, while the opposite gives a text-to-speech (TTS) model. We perform extensive experiments for these two major sequence-to-sequence tasks, showing that DSM provides state-of-the-art performance and latency while supporting arbitrary long sequences, being even competitive with offline baselines.
One-sentence Summary
The authors propose Delayed Streams Modeling (DSM), a flexible framework for streaming multimodal sequence-to-sequence learning that utilizes a decoder-only language model with pre-aligned, delayed streams to achieve state-of-the-art performance and low latency in automatic speech recognition (ASR) and text-to-speech (TTS) tasks.
Key Contributions
- The paper introduces Delayed Streams Modeling (DSM), a flexible framework for streaming multimodal sequence-to-sequence learning that uses a decoder-only language model to process time-aligned streams.
- The method employs a pre-processing alignment step and controlled delays between streams to enable streaming inference for arbitrary input and output combinations, such as both automatic speech recognition and text-to-speech.
- Experiments on ASR and TTS tasks demonstrate that DSM achieves state-of-the-art performance and latency, provides support for long-form sequences, and enables batching through constant framerate operation.
Introduction
Real-time sequence-to-sequence learning is essential for applications like continuous speech recognition and text-to-speech synthesis. While decoder-only Transformers have enabled unified multimodal processing, they typically require the entire input sequence before generating any output, which prevents real-time inference. Existing streaming alternatives often rely on complex alignment policies that are difficult to batch or require costly training-time exploration. The authors leverage a new framework called Delayed Streams Modeling (DSM) to address these issues. By aligning multiple token streams to a shared framerate during pre-processing and introducing controlled delays between them, DSM enables efficient, batchable, and streaming inference using standard decoder-only architectures.
Dataset
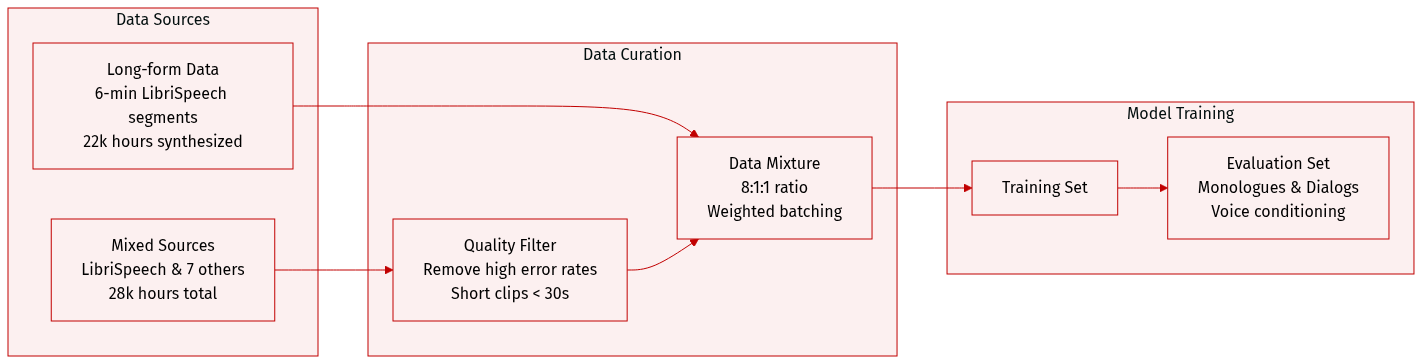
The authors utilize several distinct datasets for training and evaluating their models, categorized as follows:
- Short-form Finetuning Data: This 28k hour mixture comprises LibriSpeech, VoxPopuli, GigaSpeech, AMI, Renals et al., SPGISpeech, TED-LIUM, and Earnings22. The authors filter out examples with high character error rates from Whisper. Most examples are short, with only 0.5% exceeding 30.5 seconds. For LibriSpeech, timestamps are sourced from the Montreal Forced Aligner, while Whisper provides timestamps for all other datasets.
- Long-form Finetuning Data: To support longer sequences, the authors concatenate LibriSpeech utterances into 6 minute segments (approximately 1k hours) and include 22k hours of synthesized dialogs generated by a preliminary version of DSM-TTS.
- Training Mixture Strategy: The model is trained using a weighted mixture of LibriSpeech, the short-form data, and the long-form data in an 8:1:1 ratio. This ensures that a sample from LibriSpeech is eight times more likely to be included in a batch than a sample from the short-form mixture.
- Evaluation Datasets:
- Monologues: Evaluated using news articles from the NTREX-128 dataset, which are pre-split into sentences.
- Dialogs: Generated via the Mistral-Large-Latest API, categorized into daily life, technical, and number-heavy scripts. This includes nearly 112 dialogs per language.
- Voice Conditioning: For English, the authors use 50 voices from the VCTK test set. For French, they use 35 voices from the CML test and validation sets. Each voice is selected based on a duration between 7 and 10 seconds. Voices are randomly assigned to evaluation scripts, though the mapping remains fixed across runs.
Method
The Dual Stream Modeling (DSM) framework is designed to solve sequence-to-sequence tasks by aligning two domains, X and Y, onto a shared time grid. This alignment allows for efficient, batched streaming inference, which is a significant departure from traditional Transformer-based models that often require the entire input sequence to be known upfront.
The architecture of DSM consists of three primary components: an auto-regressive backbone, an input embedder, and a conditional sampler. The backbone, typically a Transformer architecture, processes the streaming inputs. To facilitate streaming, the authors introduce a delay τ in the output stream. This ensures that the model satisfies the necessary causality conditions, preventing future values of the input from contradicting the sampled outputs.
Refer to the framework diagram:
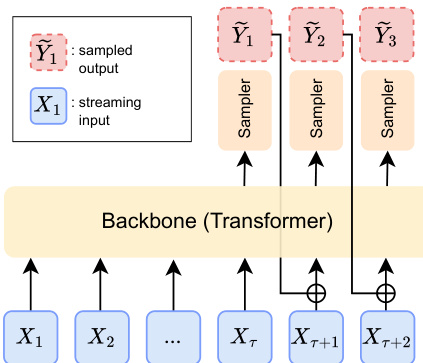
The input embedder transforms both the streaming input X and the previously sampled outputs Y into a latent space. These embeddings are then summed before being fed into the backbone. As shown in the figure below, the backbone receives the current streaming input Xt and the sampled output from the previous step Y~t−τ after the specified delay has accumulated.
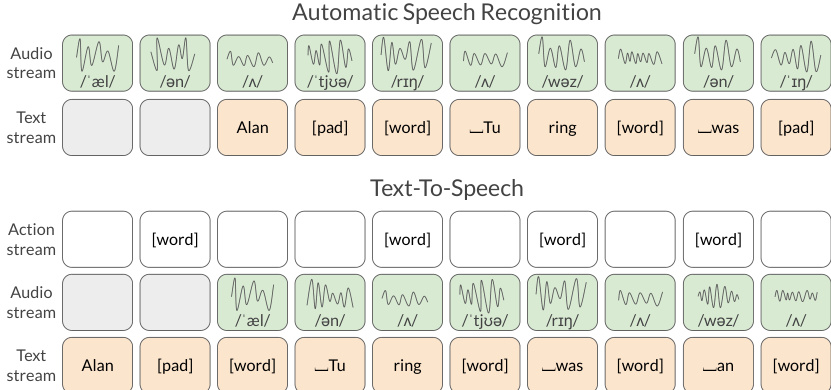
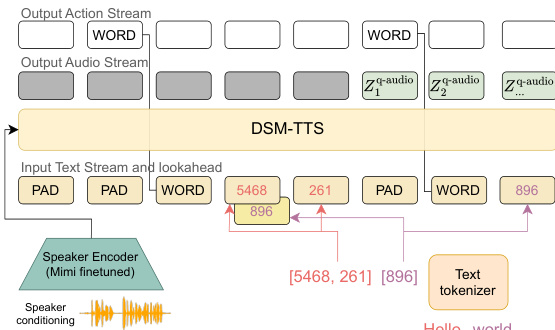
On the output side, the conditional sampler generates the next token Y~t based on the backbone's output. If the output domain is discrete, this can be a linear layer producing logits; for continuous domains, it could be a flow or diffusion model. In the specific case of DSM-TTS, the model utilizes an action output stream to predict whether the next input text token will be a "WORD" token, which signals the start of a new word. This is complemented by a lookahead text stream that provides future context to improve decision-making regarding pauses and word placement.
The entire inference process for the TTS task, including the interaction between the text stream, the action stream, and the resulting audio output, is illustrated in the following diagram:
Experiment
The evaluation compares the DSM-ASR and DSM-TTS models against various open-source and closed-source baselines across short-form and long-form tasks. DSM-ASR demonstrates high transcription quality and timestamp precision, performing competitively with top non-streaming models while offering significantly higher throughput and lower latency. Similarly, DSM-TTS excels in long-form synthesis and speaker similarity, outperforming existing methods in both monologue and dialog scenarios through efficient batchable inference.
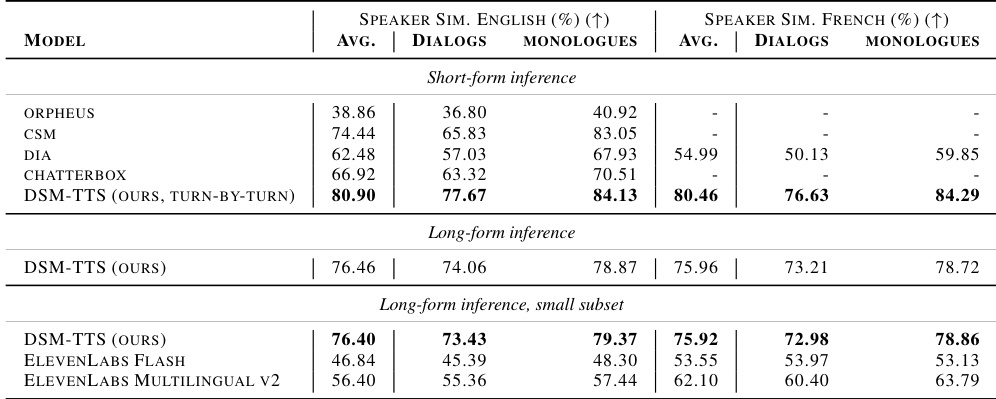
The authors compare the speaker similarity of DSM-TTS against several open-source and closed-source baselines across English and French. The results demonstrate that DSM-TTS maintains high speaker similarity in both short-form and long-form inference modes. DSM-TTS achieves higher speaker similarity than all compared baselines in both English and French across monologues and dialogs. In long-form inference, DSM-TTS outperforms commercial models like ElevenLabs in terms of speaker similarity. The model shows consistent performance between short-form turn-by-turn generation and long-form inference.
The authors evaluate different model variants for Text-To-Speech, comparing a baseline against configurations with no lookahead or various fixed padding strategies. The results assess performance across English and French using Word Error Rate and speaker similarity metrics. The baseline model achieves the lowest Word Error Rate in both English and French compared to the tested variants. Using fixed padding from the end of the sequence results in the best transcription accuracy for English. Speaker similarity remains relatively stable across most variants, though padding from the start tends to decrease similarity scores.

The authors compare the performance of DSM-TTS models trained on public datasets against existing baselines using Word Error Rate and speaker similarity metrics. Results show that the proposed models achieve competitive transcription accuracy and high speaker similarity compared to state of the art methods. The DSM-TTS model with 16 codebooks achieves a lower Word Error Rate than the 32 codebook version. Both DSM-TTS variants demonstrate speaker similarity levels comparable to the leading baselines. The DSM-TTS model with 32 codebooks achieves a high speaker similarity score matching the top performing baseline.

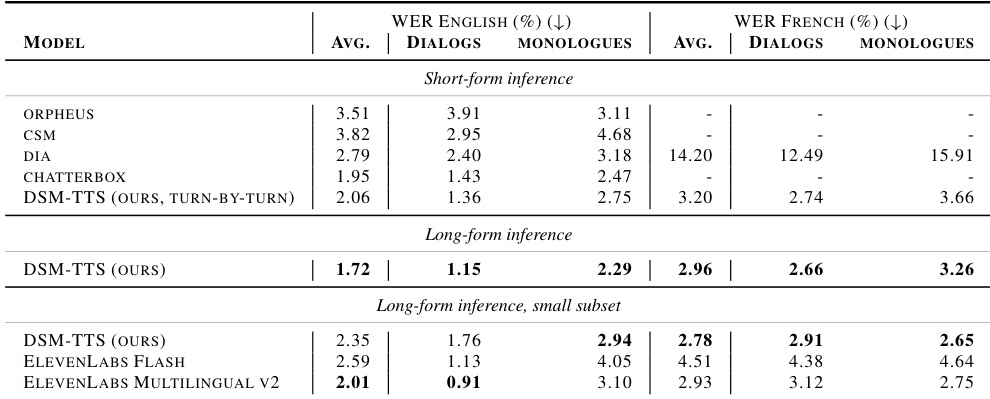
The authors compare the performance of DSM-TTS against several baselines using Word Error Rate (WER) across English and French languages. Results show that the proposed model achieves superior transcription accuracy in long-form inference scenarios compared to both short-form and subset-based evaluations. DSM-TTS achieves lower average WER in long-form English and French inference than its short-form counterpart. In long-form English dialogs, the proposed model outperforms all listed baselines including ElevenLabs. The model maintains high performance in long-form French transcription, surpassing the results of the tested subset of ElevenLabs.
The authors compare their DSM-TTS model against F5-TTS variants using different flow steps and configurations. The results demonstrate that while F5-TTS can achieve lower latency and higher real-time factors, the DSM-TTS models achieve superior word error rates and speaker similarity. DSM-TTS models achieve lower word error rates compared to the F5-TTS baselines. The DSM-TTS approach provides higher speaker similarity scores than the compared F5-TTS versions. Increasing the batch size for DSM-TTS significantly improves throughput despite a slight increase in latency.

The authors evaluate DSM-TTS through comparative studies against various open-source, closed-source, and flow-based baselines across English and French. The experiments validate the model's ability to maintain high speaker similarity and superior transcription accuracy in both short-form and long-form inference modes. Overall, DSM-TTS demonstrates competitive performance that often surpasses commercial models and existing state-of-the-art methods in terms of both linguistic precision and vocal consistency.