HyperAI
Command Palette
Search for a command to run...
Nemotron-CC-Math 数学预训练数据集
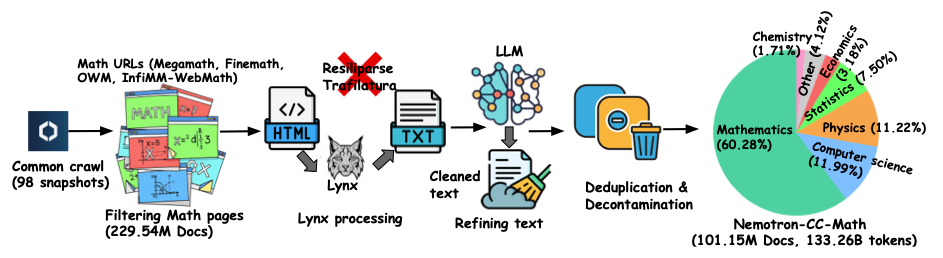
Nemotron-CC-Math 是由英伟达和波士顿大学于 2025 年发布的一个以数学为重点的高质量大规模预训练数据集,相关论文成果为「Nemotron-CC-Math: A 133 Billion-Token-Scale High Quality Math Pretraining Dataset」,旨在保存和展示高价值的数学和代码内容,从而推动下一波智能的、具有全球能力的语言模型。
该数据集包含 1,330 亿 Token,基于 NVIDIA Lynx 与轻量 LLM 的抽取与规范化管线自 Common Crawl 构建。在保留方程与代码版式结构的同时,将数学内容统一为可编辑的 LaTeX 格式,首次在 Web 规模上可靠覆盖多种(含长尾)数学格式;其优势已在多项基准中得到验证。
该数据集由社区用户贡献,仅供交流学习使用。如内容涉及侵权,请联系邮箱 [email protected] 以便及时审查和下架。