HyperAI
HyperAI
主区域
首页
GPU
控制台
文档
价格
Pulse
报道
资源
论文
教程
数据集
百科
基准测试
SOTA
大语言模型(LLM)
GPU 排行榜
社区
活动
开源
实用工具
搜索
关于
服务条款
隐私政策
中文
HyperAI
HyperAI
Toggle Sidebar
⌘
K
Command Palette
Search for a command to run...
登录
HyperAI
论文
论文
每日更新的前沿人工智能研究论文,帮助您紧跟最新的人工智能趋势
HyperAI
HyperAI
主区域
首页
GPU
控制台
文档
价格
Pulse
报道
资源
论文
教程
数据集
百科
基准测试
SOTA
大语言模型(LLM)
GPU 排行榜
社区
活动
开源
实用工具
搜索
关于
服务条款
隐私政策
中文
HyperAI
HyperAI
Toggle Sidebar
⌘
K
Command Palette
Search for a command to run...
登录
HyperAI
论文
论文
每日更新的前沿人工智能研究论文,帮助您紧跟最新的人工智能趋势
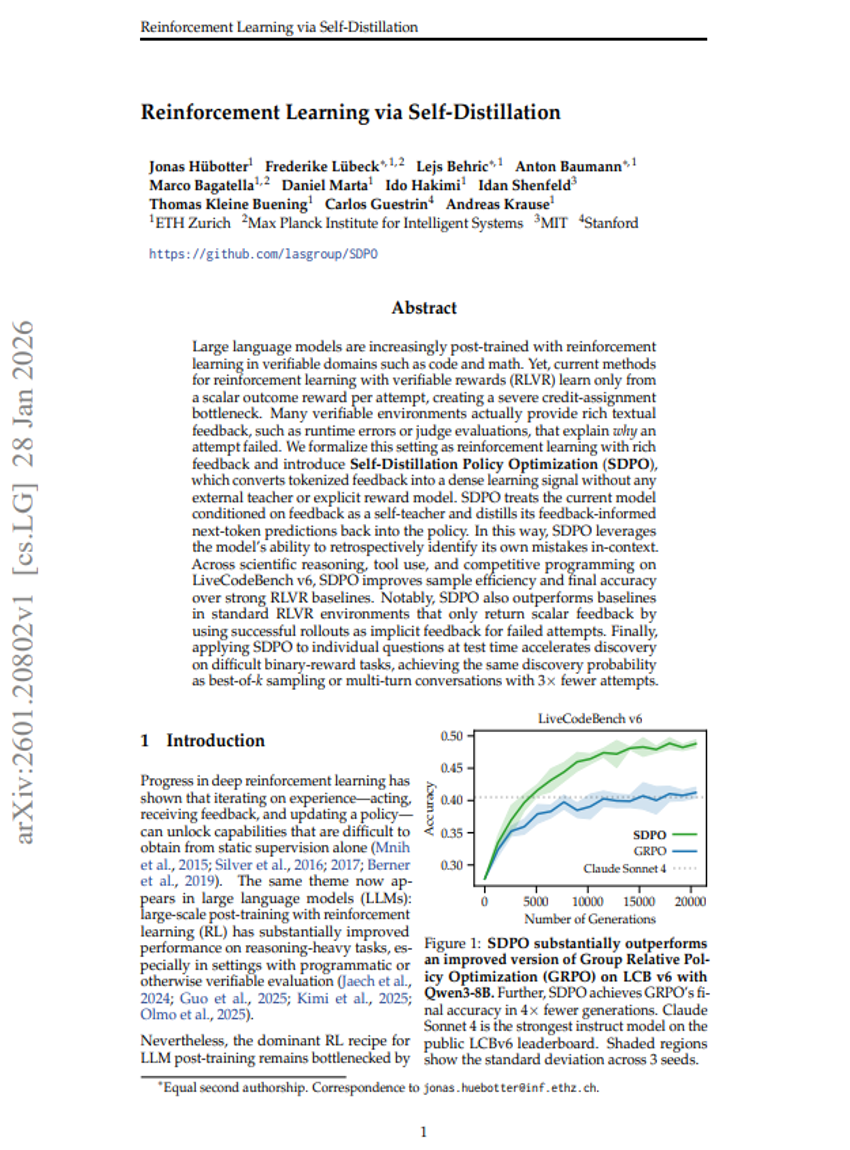
基于自蒸馏的强化学习
强化学习
检索增强生成
Jonas Hübotter, Frederike Lübeck, Lejs Behric, et al.
聊天机器人作为社交伴侣:人们如何感知机器的意识、类人程度以及社交健康益处
人机交互
心理
Rose E. Guingrich, Michael S. A. Graziano
POPE:通过特权在策略探索学习在难题上进行推理
强化学习
推理
Yuxiao Qu, Amrith Setlur, Virginia Smith, et al.
UniReason 1.0:面向世界知识对齐的图像生成与编辑的统一推理框架
文生图
多模态
Dianyi Wang, Chaofan Ma, Feng Han, et al.
闭环闭环:基于RPG-Encoder的通用仓库表示
代码生成
多模态表征
Jane Luo, Chengyu Yin, Xin Zhang, et al.
视觉-DeepResearch基准:重新思考多模态大语言模型中的视觉与文本搜索
视觉问答
多模态
Yu Zeng, Wenxuan Huang, Zhen Fang, et al.
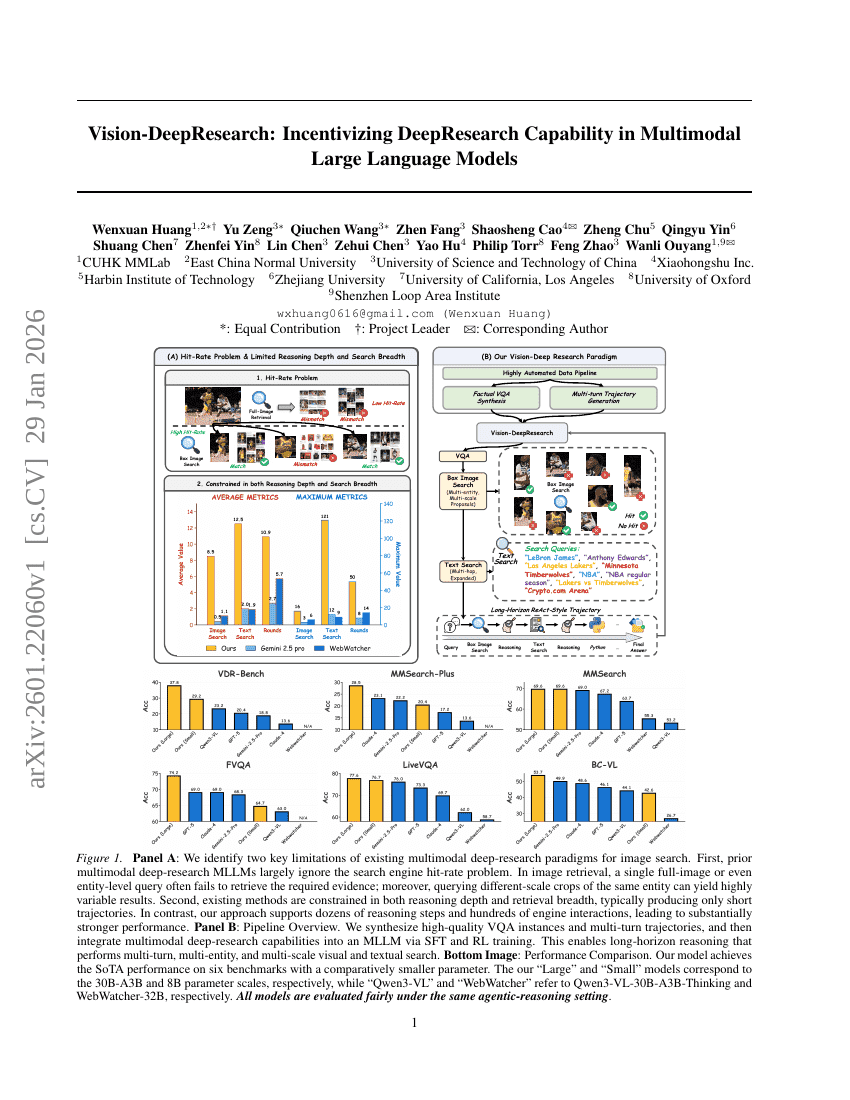
Vision-DeepResearch:在多模态大语言模型中激励深度研究能力
检索增强生成
视觉问答
Wenxuan Huang, Yu Zeng, Qiuchen Wang, et al.
Kimi K2.5:视觉智能体智能
多模态
多模态表征
Kimi Team, Tongtong Bai, Yifan Bai, et al.
Green-VLA:面向通用机器人的分阶段视觉-语言-动作模型
多模态
统一多模态
I. Apanasevich, M. Artemyev, R. Babakyan, et al.
PaperBanana:为AI科学家自动化学术插图
文生图
AI for Science
Dawei Zhu, Rui Meng, Yale Song, et al.
使用Gemini的半自主数学发现:Erdős问题案例研究
AI for Science
数学
Tony Feng, Trieu Trinh, Garrett Bingham, et al.
潜在思维链作为规划:将推理与语言化分离
LLM
推理
Jiecong Wang, Hao Peng, Chunyang Liu
实时对齐的奖励模型:超越语义
强化学习
LLM
Zixuan Huang, Xin Xia, Yuxi Ren, et al.
DenseGRPO:从稀疏到密集奖励用于流匹配模型对齐
扩散模型
监督式微调
Haoyou Deng, Keyu Yan, Chaojie Mao, et al.
DreamActor-M2:通过时空上下文学习实现通用角色图像动画
视频生成
图生视频
Mingshuang Luo, Shuang Liang, Zhengkun Rong, et al.
TTCS:用于自演化系统的测试时课程合成
LLM
推理
Chengyi Yang, Zhishang Xiang, Yunbo Tang, et al.
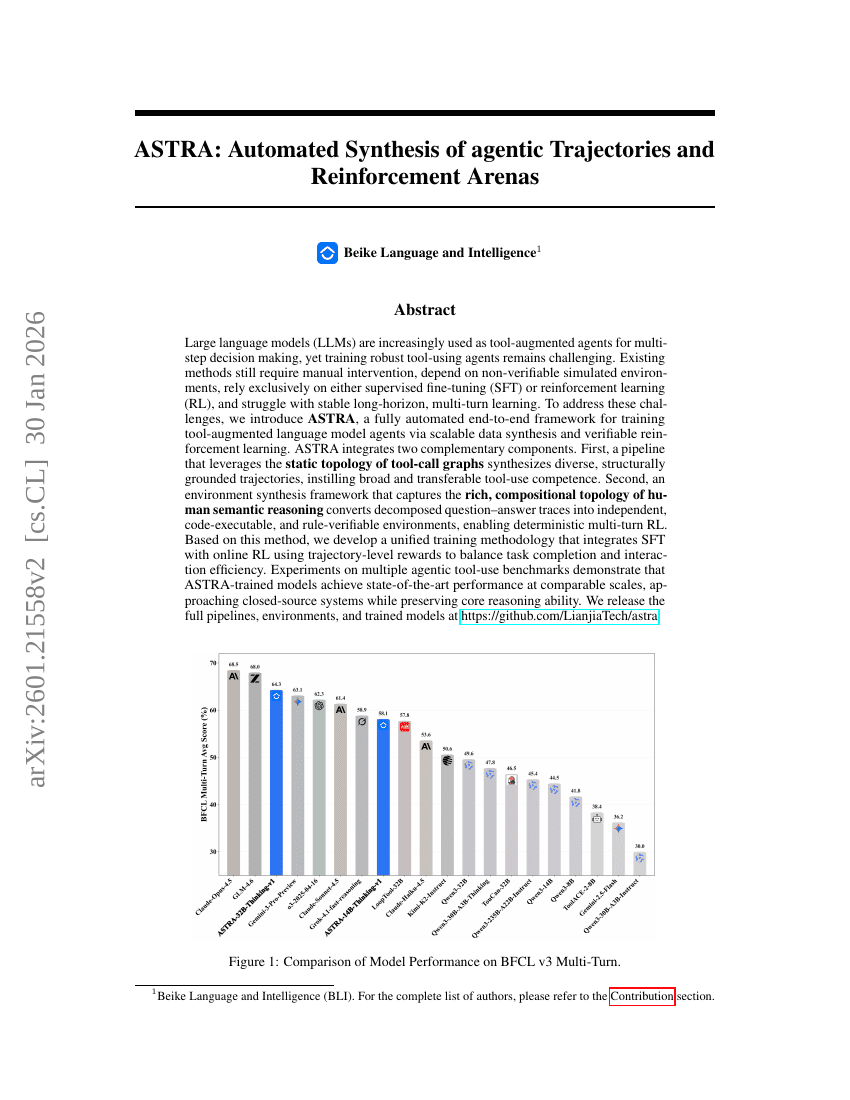
ASTRA:智能体轨迹与强化环境的自动化合成
强化学习
LLM
Xiaoyu Tian, Haotian Wang, Shuaiting Chen, et al.
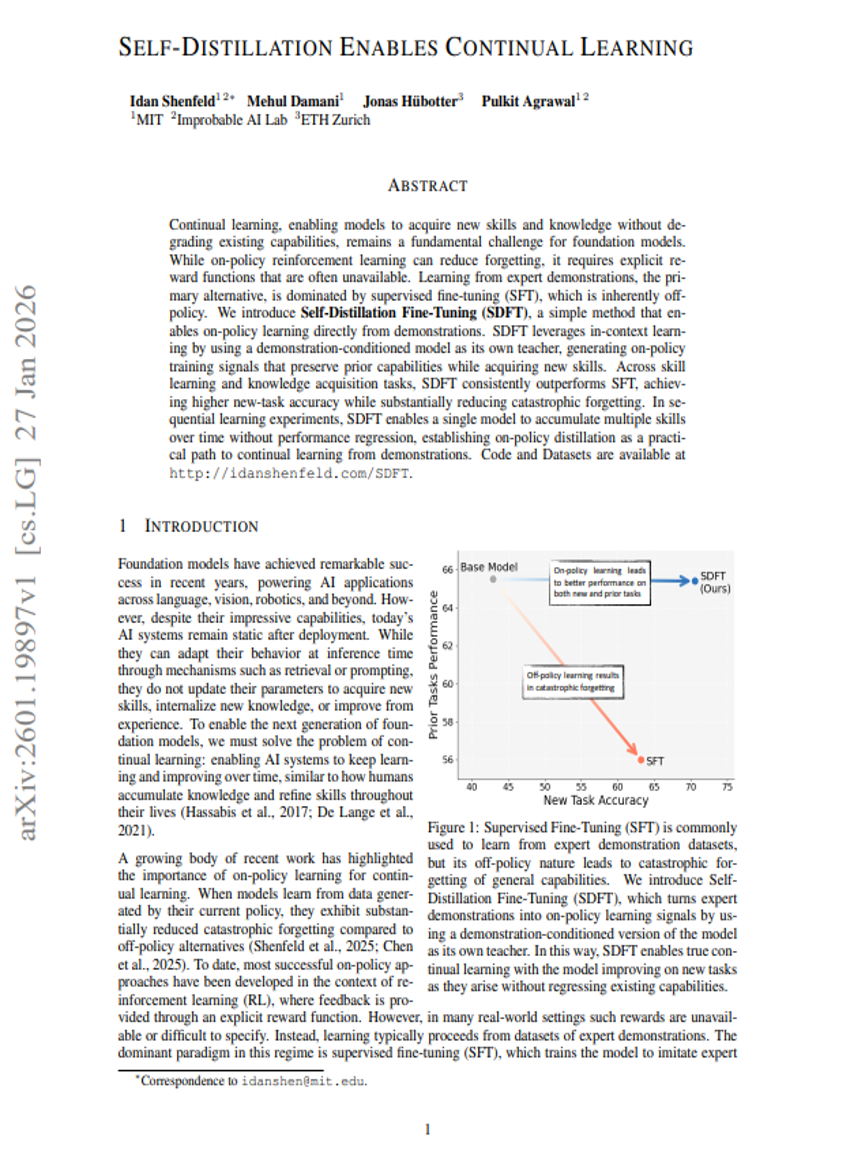
自蒸馏实现持续学习
强化学习
监督式微调
Idan Shenfeld, Mehul Damani, Jonas Hübotter, et al.
面向执行基础的自动化AI研究
LLM
算法
Chenglei Si, Zitong Yang, Yejin Choi, et al.
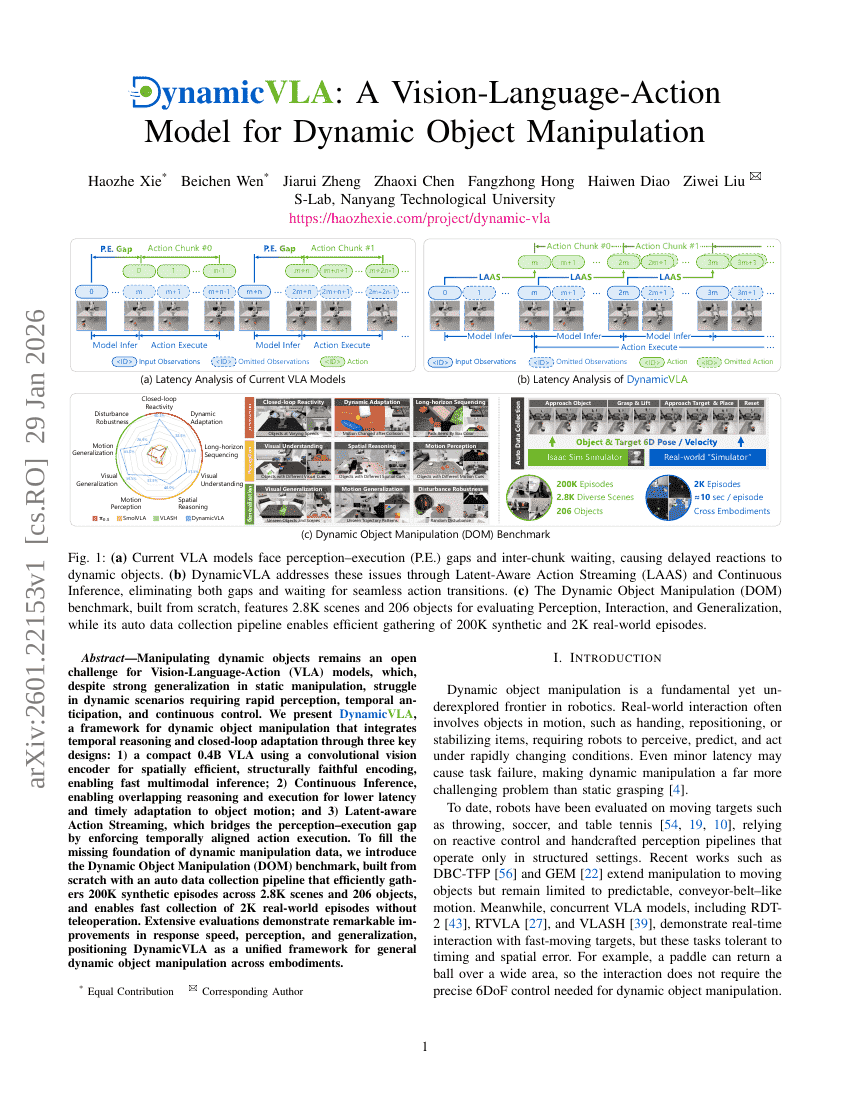
DynamicVLA:一种用于动态物体操作的视觉-语言-动作模型
机器人技术
具身智能
Haozhe Xie, Beichen Wen, Jiarui Zheng, et al.
MMFineReason:通过开放数据驱动方法弥合多模态推理差距
推理
数据集
Honglin Lin, Zheng Liu, Yun Zhu, et al.
OCRVerse:迈向端到端视觉-语言模型中的全面OCR
OCR
文档理解
Yufeng Zhong, Lei Chen, Xuanle Zhao, et al.
扩展嵌入空间在语言模型中的表现优于扩展专家模型
检索增强生成
Transformer
Hong Liu, Jiaqi Zhang, Chao Wang, et al.
Idea2Story:一种将研究概念自动转化为完整科学叙事的流水线
Agent
LLM
Tengyue Xu, Zhuoyang Qian, Gaoge Liu, et al.
各归其位:文本到图像模型空间智能的基准测试
文生图
扩散模型
Zengbin Wang, Xuecai Hu, Yong Wang, et al.
Qwen3-ASR 技术报告
音频和语音处理
LLM
Xian Shi, Xiong Wang, Zhifang Guo, et al.
Insight Agents:一种基于LLM的多代理数据洞察系统
Agent
智能问答
Jincheng Bai, Zhenyu Zhang, Jennifer Zhang, et al.
通过简单点预测实现像素级VLM感知
图像分割
多模态表征
Tianhui Song, Haoyu Lu, Hao Yang, et al.
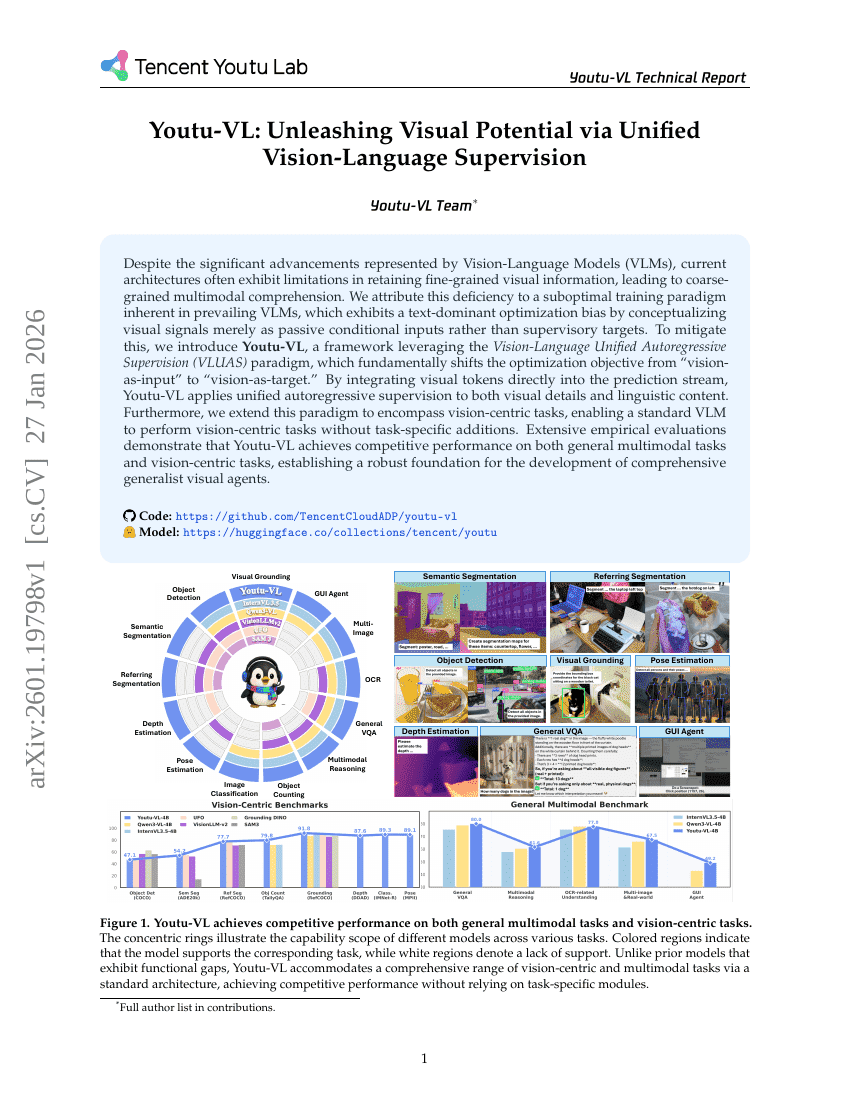
Youtu-VL:通过统一的视觉-语言监督释放视觉潜能
多模态表征
统一多模态
Zhixiang Wei, Yi Li, Zhehan Kan, et al.
Innovator-VL:面向科学发现的多模态大语言模型
多模态表征
智能问答
Zichen Wen, Boxue Yang, Shuang Chen, et al.
推进开源世界模型
视频生成
开源
Robbyant Team, Zelin Gao, Qiuyu Wang, et al.
更难才更好:通过感知难度的GRPO与多维度问题重表述提升数学推理能力
强化学习
推理
Yanqi Dai, Yuxiang Ji, Xiao Zhang, et al.
1
2
3
4
48
基于自蒸馏的强化学习
强化学习
检索增强生成
Jonas Hübotter, Frederike Lübeck, Lejs Behric, et al.
聊天机器人作为社交伴侣:人们如何感知机器的意识、类人程度以及社交健康益处
人机交互
心理
Rose E. Guingrich, Michael S. A. Graziano
POPE:通过特权在策略探索学习在难题上进行推理
强化学习
推理
Yuxiao Qu, Amrith Setlur, Virginia Smith, et al.
UniReason 1.0:面向世界知识对齐的图像生成与编辑的统一推理框架
文生图
多模态
Dianyi Wang, Chaofan Ma, Feng Han, et al.
闭环闭环:基于RPG-Encoder的通用仓库表示
代码生成
多模态表征
Jane Luo, Chengyu Yin, Xin Zhang, et al.
视觉-DeepResearch基准:重新思考多模态大语言模型中的视觉与文本搜索
视觉问答
多模态
Yu Zeng, Wenxuan Huang, Zhen Fang, et al.
Vision-DeepResearch:在多模态大语言模型中激励深度研究能力
检索增强生成
视觉问答
Wenxuan Huang, Yu Zeng, Qiuchen Wang, et al.
Kimi K2.5:视觉智能体智能
多模态
多模态表征
Kimi Team, Tongtong Bai, Yifan Bai, et al.
Green-VLA:面向通用机器人的分阶段视觉-语言-动作模型
多模态
统一多模态
I. Apanasevich, M. Artemyev, R. Babakyan, et al.
PaperBanana:为AI科学家自动化学术插图
文生图
AI for Science
Dawei Zhu, Rui Meng, Yale Song, et al.
使用Gemini的半自主数学发现:Erdős问题案例研究
AI for Science
数学
Tony Feng, Trieu Trinh, Garrett Bingham, et al.
潜在思维链作为规划:将推理与语言化分离
LLM
推理
Jiecong Wang, Hao Peng, Chunyang Liu
实时对齐的奖励模型:超越语义
强化学习
LLM
Zixuan Huang, Xin Xia, Yuxi Ren, et al.
DenseGRPO:从稀疏到密集奖励用于流匹配模型对齐
扩散模型
监督式微调
Haoyou Deng, Keyu Yan, Chaojie Mao, et al.
DreamActor-M2:通过时空上下文学习实现通用角色图像动画
视频生成
图生视频
Mingshuang Luo, Shuang Liang, Zhengkun Rong, et al.
TTCS:用于自演化系统的测试时课程合成
LLM
推理
Chengyi Yang, Zhishang Xiang, Yunbo Tang, et al.
ASTRA:智能体轨迹与强化环境的自动化合成
强化学习
LLM
Xiaoyu Tian, Haotian Wang, Shuaiting Chen, et al.
自蒸馏实现持续学习
强化学习
监督式微调
Idan Shenfeld, Mehul Damani, Jonas Hübotter, et al.
面向执行基础的自动化AI研究
LLM
算法
Chenglei Si, Zitong Yang, Yejin Choi, et al.
DynamicVLA:一种用于动态物体操作的视觉-语言-动作模型
机器人技术
具身智能
Haozhe Xie, Beichen Wen, Jiarui Zheng, et al.
MMFineReason:通过开放数据驱动方法弥合多模态推理差距
推理
数据集
Honglin Lin, Zheng Liu, Yun Zhu, et al.
OCRVerse:迈向端到端视觉-语言模型中的全面OCR
OCR
文档理解
Yufeng Zhong, Lei Chen, Xuanle Zhao, et al.
扩展嵌入空间在语言模型中的表现优于扩展专家模型
检索增强生成
Transformer
Hong Liu, Jiaqi Zhang, Chao Wang, et al.
Idea2Story:一种将研究概念自动转化为完整科学叙事的流水线
Agent
LLM
Tengyue Xu, Zhuoyang Qian, Gaoge Liu, et al.
各归其位:文本到图像模型空间智能的基准测试
文生图
扩散模型
Zengbin Wang, Xuecai Hu, Yong Wang, et al.
Qwen3-ASR 技术报告
音频和语音处理
LLM
Xian Shi, Xiong Wang, Zhifang Guo, et al.
Insight Agents:一种基于LLM的多代理数据洞察系统
Agent
智能问答
Jincheng Bai, Zhenyu Zhang, Jennifer Zhang, et al.
通过简单点预测实现像素级VLM感知
图像分割
多模态表征
Tianhui Song, Haoyu Lu, Hao Yang, et al.
Youtu-VL:通过统一的视觉-语言监督释放视觉潜能
多模态表征
统一多模态
Zhixiang Wei, Yi Li, Zhehan Kan, et al.
Innovator-VL:面向科学发现的多模态大语言模型
多模态表征
智能问答
Zichen Wen, Boxue Yang, Shuang Chen, et al.
推进开源世界模型
视频生成
开源
Robbyant Team, Zelin Gao, Qiuyu Wang, et al.
更难才更好:通过感知难度的GRPO与多维度问题重表述提升数学推理能力
强化学习
推理
Yanqi Dai, Yuxiang Ji, Xiao Zhang, et al.
1
2
3
4
48