Command Palette
Search for a command to run...
WildSpeech-Bench 语音理解生成基准数据集
WildSpeech-Bench 是由腾讯于 2025 年发布的首个用于评估 SpeechLLM 语音转语音能力的基准,相关论文成果为「WildSpeech-Bench: Benchmarking End-to-End SpeechLLMs in the Wild」,旨在衡量模型在真实语音交互场景中完整语音输入到语音输出(Speech-to-Speech, S2S)的理解与生成能力。
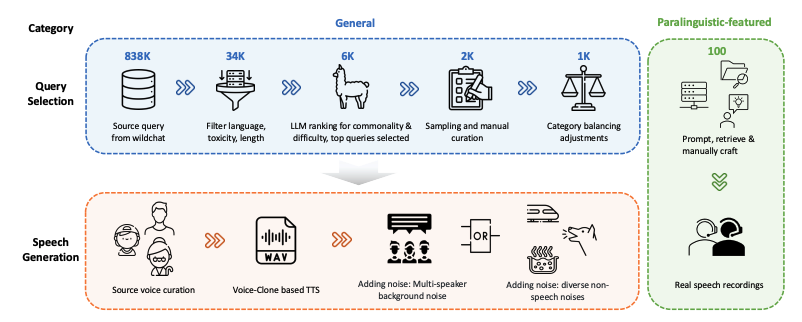
该数据集共包含 1,100 条查询(query),覆盖信息查询、解决方案请求、观点交流、文本创作、副语言特征表达五大主要类别,每个类别对应一种常见的用户意图。其中 1,000 条来自一般语音交互场景(包括信息查询、解决方案请求、观点交流和文本创作),另有 100 条具有副语言特征(Paralinguistic-Featured),例如停顿、语气、口吃、近音词识别等。每条查询均配有多样化的语音输出样例,涵盖丰富的说话者属性(性别、年龄、音色变体)、声学条件及噪声环境设置,以更真实地模拟自然语音交互中的多样性与挑战性。
WildSpeech-Bench.torrent
做种 1正在下载 0已完成 0总下载次数 3