Command Palette
Search for a command to run...
输入输出双侧革新!腾讯混元推出 HunyuanWorld-Mirror 刷新 3D 重建 SOTA; 解码 Netflix 内容全貌!Netflix 电影电视目录数据集助力洞察娱乐趋势

视觉几何学习是计算机视觉领域的核心课题,广泛应用于增强现实、机器人操控与自主导航等场景。传统方法如运动结构重建(SfM)与多视图立体技术通常依赖迭代优化,计算代价高昂。近年来,该领域逐渐转向基于前馈神经网络的端到端几何重建模型。
尽管成果显著,现有方法在输入与输出两个维度上仍存在明显局限。在输入侧,当前模型因仅处理原始图像而未能利用相机内参、初始位姿与传感器深度等现实可得的先验信息,导致其在应对尺度模糊、多视角不一致及纹理缺失区域等问题时表现不佳。在输出侧,现有方法多局限于单一或少数几何任务(如深度或位姿估计),高度专业化而缺乏整合。尽管 VGGT 等研究推动了任务统一,但表面法线估计与新视角合成等基础任务仍未被纳入统一框架。
上述局限引出一个关键问题:能否在一个通用的三维重建架构中,通过有效引入多样化先验信息,同时应对输入与输出两方面的挑战?
基于此,腾讯混元团队推出 HunyuanWorld-Mirror,这是一个用于多功能 3D 几何预测任务的全集成、前馈模型,旨在利用任何可用的几何先验知识执行通用 3D 重建任务。该模型的核心是一个新颖的多模态先验提示机制,灵活地集成了包括相机姿态、内参和深度图在内的多种几何先验,同时生成多个 3D 表示:密集点云、多视图深度图、相机参数、表面法线和 3D 高斯分布。这种统一的架构利用可用的先验信息来解决结构歧义,并在单次前馈过程中提供几何一致的 3D 输出。
HunyuanWorld-Mirror 利用可用先验的能力使其能够在具有挑战性的场景中进行稳健重建,其多任务设计确保了不同输出之间的几何一致性,在相机、点图、深度和表面法线估计到新视角合成等多样化基准测试中实现了最先进的性能。
目前,HyperAI 超神经官网已上线了「HunyuanWorld-Mirror:3D 世界生成模型」,快来试试吧~
在线使用:https://go.hyper.ai/Ptv69
11 月 24 日-11 月 28 日,hyper.ai 官网更新速览:
* 优质公共数据集:7 个
* 优质教程精选:6 个
* 本周论文推荐: 5 篇
* 社区文章解读:5 篇
* 热门百科词条:5 条
* 12 月截稿顶会:2 个
访问官网:hyper.ai
公共数据集精选
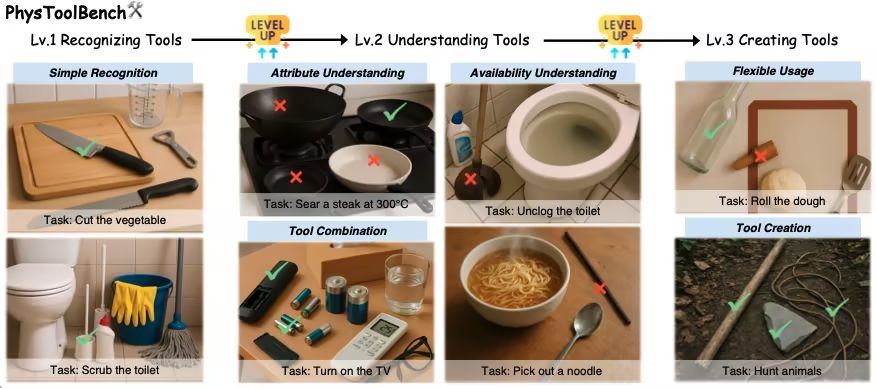
1. PhysToolBench 物理工具任务数据集
PhysToolBench 是由香港科技大学(广州)联合香港科技大学、北京航空航天大学等机构发布的一个视觉 – 语言问答(VQA)数据集,旨在评估多模态大语言模型(MLLMs)对物理工具的识别、理解与创造能力。该数据集包含超过 1,000 条图像-文本对,覆盖日常生活、工业、户外活动与专业环境等多种场景。
直接使用:https://go.hyper.ai/bP9Ad
2. CytoData 血液细胞图像数据集
CytoData 血液细胞图像数据集是由英国剑桥大学的研究团队发布的一个血液细胞匿名数据集,已刊登 Nature 。该数据集包含来自剑桥 Addenbrooke’s 医院的 2,904 张血液涂片,共计 559,808 张单细胞图像,其中 4,996 张图像标注了十类血液细胞类型,包括红细胞母细胞、嗜酸性粒细胞等。
直接使用:https://go.hyper.ai/uLXKt
3. MeshCoder 结构化 3D 物体-代码数据集
MeshCoder 是由上海人工智能实验室联合清华大学、哈尔滨工业大学(深圳)等机构发布的一个用于 3D 点云到可编辑代码生成的多模态数据集,旨在推动大语言模型在 3D 场景解析、结构理解与可编程几何重建方面的能力发展。
直接使用:https://go.hyper.ai/x3zvv
4. Netflix 电影电视目录数据集
Netflix 影片与剧集目录数据集是一个涵盖全球多国家、多类型影视内容的综合目录数据集,旨在展示 Netflix 平台的内容分布全貌,为研究娱乐趋势、观众偏好及内容布局提供数据支持。该数据集收录了 Netflix 已上线的电影与电视剧条目,每条数据代表一个标题,包含标题名称、内容类型(电影或剧集)、导演等关键信息。
直接使用:https://go.hyper.ai/8gzcZ
5. InteractMove 三维场景人-物交互数据集
InteractMove 是北京大学计算机科学技术研究所联合北京电子科技学院发布的一个面向三维场景人-物交互生成的数据集,旨在支持和推动基于文本控制的可移动物体交互建模研究。该数据集覆盖了 多类可移动物体、多个真实扫描场景,并提供了与场景严格对齐的人-物交互动作序列。
直接使用:https://go.hyper.ai/uFrPd
6. GroundCUA 界面操作训练数据集
GroundCUA 是由 Mila 魁北克人工智能研究所联合麦吉尔大学、蒙特利尔大学等机构发布的一个真实用户界面(UI)数据集,旨在支持能够与计算机进行交互的多模态智能体研究。该数据集基于专家级人类操作示范构建,并提供超过 356 万条经过人工验证的元素级注释。
直接使用:https://go.hyper.ai/5bDrX
7. Camera Clone 相机克隆多视角数据集
Camera Clone 由香港大学联合浙江大学、快手科技等机构发布,是一个基于 Unreal Engine 5 渲染的大规模合成视频数据集,旨在支持相机克隆学习(Camera Clone Learning),即在保持场景内容不变的前提下复制参考视频的相机运动,实现「内容复现 + 相机运动匹配」。
直接使用:https://go.hyper.ai/US4nY
公共教程精选
1. PyTorch 官方教程:用 PyTorch 实现深度学习
本教程的目标为理解在 PyTorch 中如何使用张量和构建神经网络,训练一个小型神经网络对图像进行分类。
在线运行:https://go.hyper.ai/Fb2c6
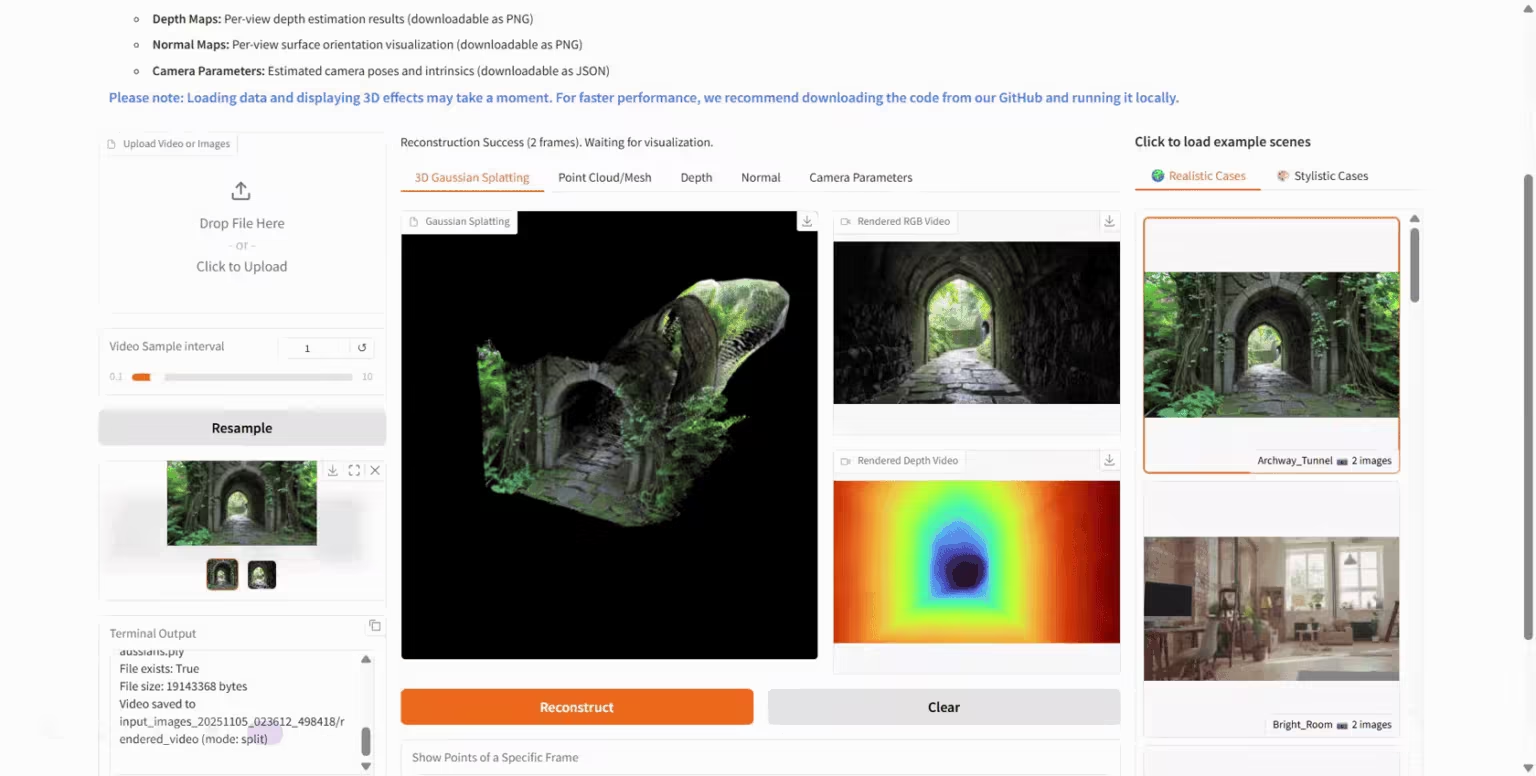
2. HunyuanWorld-Mirror:3D 世界生成模型
HunyuanWorld-Mirror 是腾讯混元团队发布的开源 3D 世界生成模型,支持多视图图像、视频等多种输入方式,可输出点云、深度图、相机参数等多种 3D 几何预测结果。该模型采用纯前馈架构,可在单张显卡上部署,处理 8-32 视图输入时,本地耗时仅 1 秒,实现秒级推理。
在线运行:https://go.hyper.ai/Ptv69
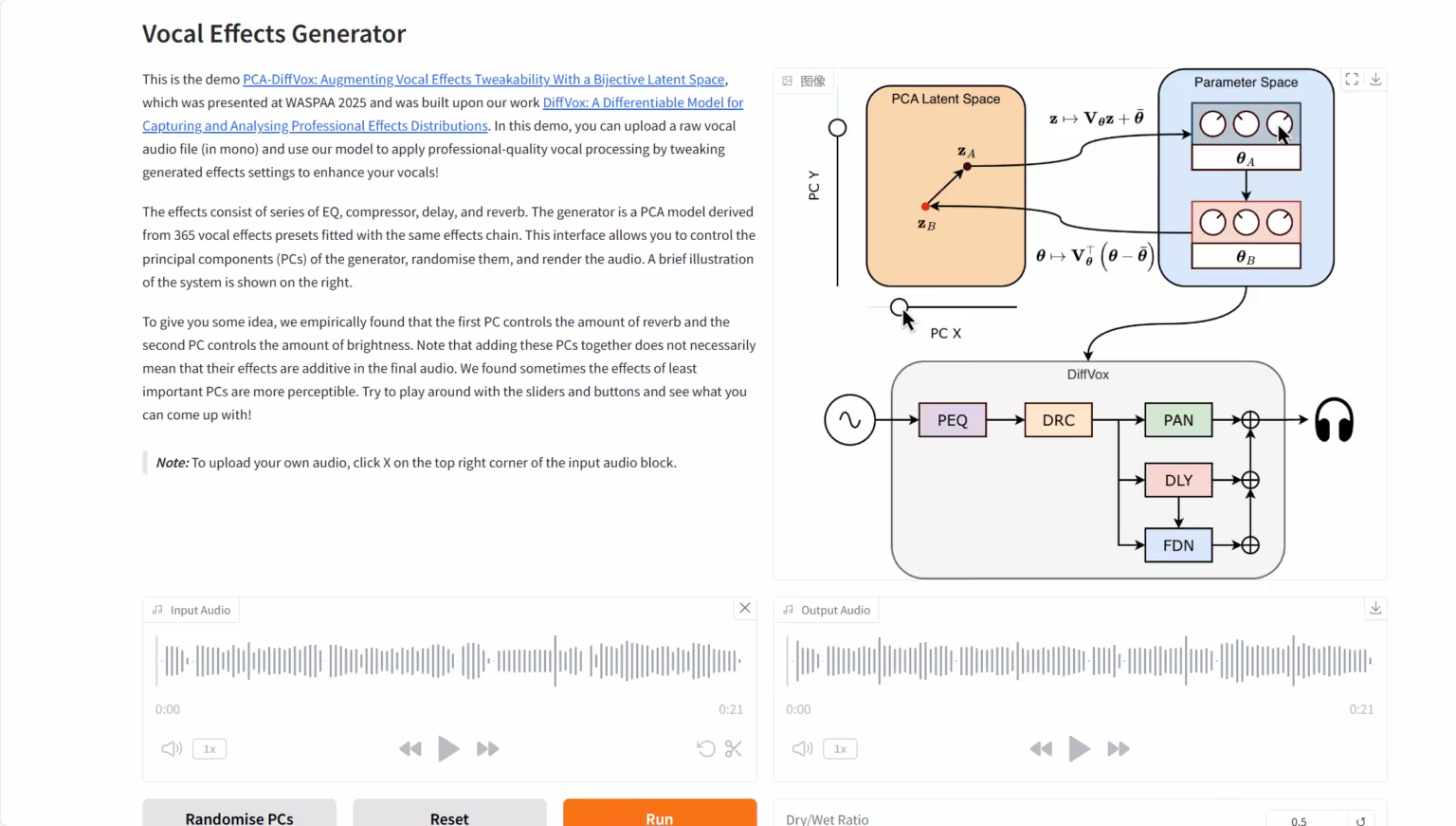
3. DiffVox:声音区分效果模型
DiffVox 项目是由索尼 AI 、索尼集团与伦敦玛丽女王大学的研究团队联合发布。该模型的核心能力在于,它采用推理时优化的先进方法,并创新性地引入高斯先验约束,从而能够将一段原始人声干声,智能地转化为在听感上逼近目标参考、且在参数上符合专业混音标准的优质音频。
在线运行:https://go.hyper.ai/Y19Wv
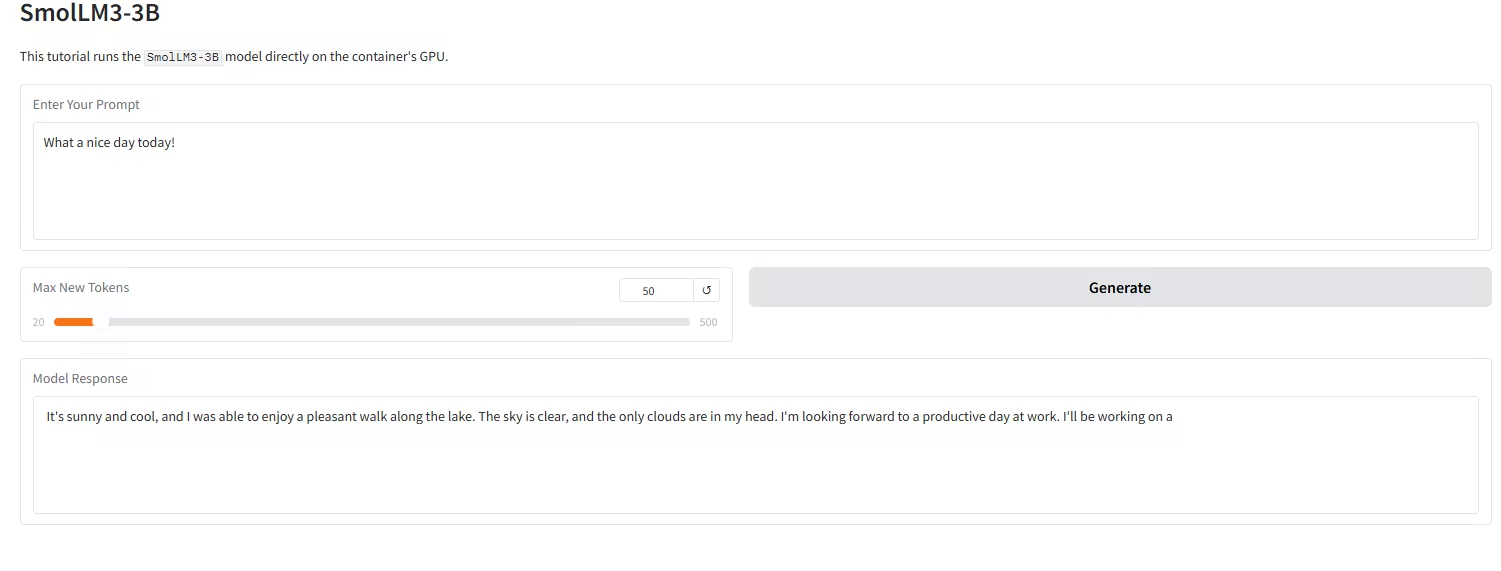
4. 一键部署 SmolLM3-3B-Model
SmolLM3-3B 由 Hugging Face TB(Transformer Big)团队开源发布,定位「端侧性能天花板」,是一款革命性的 30 亿参数开源语言模型,旨在以 3B 的紧凑规模下,突破小型模型的性能极限。
在线运行:https://go.hyper.ai/wZ48d
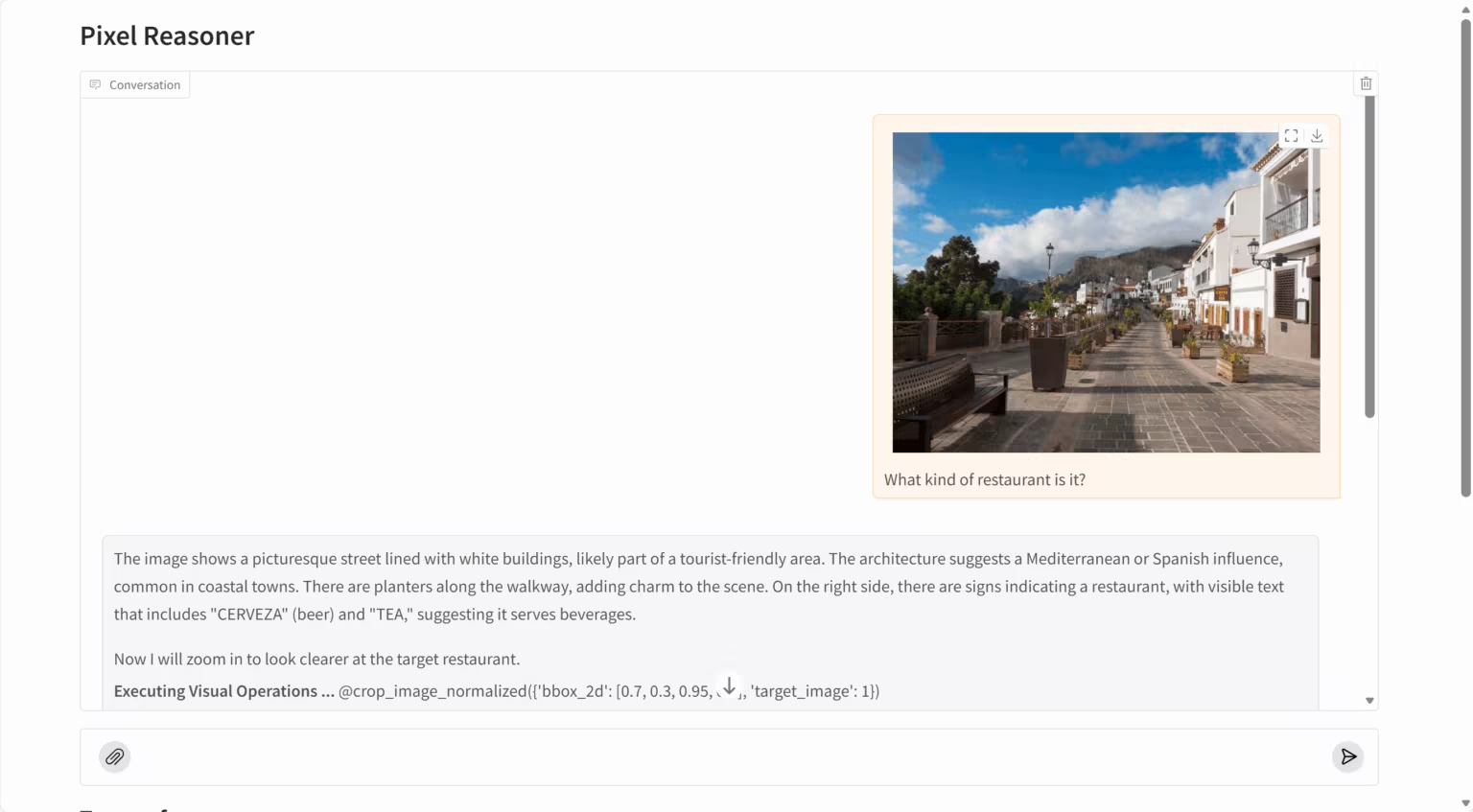
5. PixelReasoner-RL:像素级视觉推理模型
PixelReasoner-RL-v1 是由 TIGER AI Lab 发布的突破性视觉语言模型,项目基于 Qwen2.5-VL 架构,通过创新的好奇心驱动强化学习训练方法,突破了传统视觉语言模型仅依赖文本推理的局限。模型能够在像素空间中直接进行推理,支持缩放、选择帧等视觉操作,显著提升了对图像细节、空间关系和视频内容的理解能力。
在线运行:https://go.hyper.ai/t1rdr
6. Krea-realtime-video:实时视频生成模型
Krea Realtime 14B 是由 Krea 团队发布的 140 亿参数实时视频生成模型,能够实现实时长视频(Long-Form)生成,是目前已公开的最大实时视频生成模型之一。该模型基于 Wan 2.1 14B 文本到视频(Text-to-Video)模型,通过 Self-Forcing 技术蒸馏训练,将传统视频扩散模型转化为自回归(Autoregressive)结构,从而实现了真正的实时视频生成体验。
在线运行:https://go.hyper.ai/GS7oW

本周论文推荐
1. General Agentic Memory Via Deep Research
本文提出了一种名为通用智能体记忆(General Agentic Memory, GAM)的全新框架。该框架遵循「即时编译」(Just-In-Time, JIT)的原则:在离线阶段仅保留虽简单但具实用价值的记忆,而在运行时专注于为其客户端构建经过优化的上下文。实验研究表明,相较于现有的记忆系统,GAM 在各类基于记忆的任务完成场景中均取得了显著的性能提升。
论文链接:https://go.hyper.ai/sA1RN
2. ROOT: Robust Orthogonalized Optimizer for Neural Network Training
本文提出 ROOT——一种鲁棒正交化优化器(Robust Orthogonalized Optimizer),通过双重鲁棒性机制显著增强训练稳定性。大量实验结果表明,ROOT 在噪声环境与非凸优化场景下均展现出显著增强的鲁棒性,相较于 Muon 及基于 Adam 的优化器,不仅收敛速度更快,最终性能也更为优越。
论文链接:https://go.hyper.ai/gv0x2
3. GigaEvo: An Open Source Optimization Framework Powered By LLMs And Evolution Algorithms
本文提出 GigaEvo——一个可扩展的开源框架,旨在支持研究人员对受 AlphaEvolve 启发的混合式 LLM-进化计算方法进行研究与实验。 GigaEvo 系统提供了多个核心组件的模块化实现:MAP-Elites 质量-多样性算法、基于有向无环图(DAG)的异步评估流水线、具备洞察生成能力的 LLM 驱动突变算子以及双向谱系追踪机制,同时支持灵活的多岛屿进化策略。
论文链接:https://go.hyper.ai/jN3Q1
4. SAM 3: Segment Anything with Concepts
本文提出了 Segment Anything Model (SAM) 3,这是一个统一模型,能够根据概念提示(concept prompts)在图像和视频中检测、分割并跟踪物体。 SAM 3 在图像和视频 PCS 任务上的准确率达到了现有系统的两倍,并提升了前代 SAM 在视觉分割任务上的性能。目前 SAM 3 已开源,同时也发布了用于可提示概念分割的新基准测试 Segment Anything with Concepts (SA-Co) 。
论文链接:https://go.hyper.ai/KN3g7
5. OpenMMReasoner: Pushing the Frontiers for Multimodal Reasoning with an Open and General Recipe
本文推出了 OpenMMReasoner,这是一套涵盖监督微调(SFT)与强化学习(RL)的完全透明的两阶段多模态推理训练方案。在 SFT 阶段,研究人员构建了一个包含 87.4 万样本的冷启动数据集(Cold-start Dataset),并辅以严格的逐步验证(Step-by-step Validation)机制,为推理能力奠定了坚实基础。随后的 RL 阶段利用覆盖多种领域的 7.4 万样本数据集,进一步强化并稳定了这些能力,从而实现更具鲁棒性且高效的学习过程。
论文链接:https://go.hyper.ai/OfXKY
更多 AI 前沿论文:https://go.hyper.ai/iSYSZ
社区文章解读
1. 首个天文多模态基础模型 AION-1 诞生!UC 伯克利等基于 2 亿天文目标预训练,成功构建泛化性多模态天文 AI 框架
加州大学伯克利分校、剑桥大学、牛津大学等全球十余所科研机构的团队联合攻关,推出了首个面向天文学的大规模多模态基础模型家族——AION-1,通过统一的早期融合 backbone 网络,将图像、光谱和星表数据等异质观测信息进行集成建模,不仅在零样本场景下表现优异,其线性探测准确率也可媲美甚至超越针对特定任务专门训练的模型。
查看完整报道:https://go.hyper.ai/2zA0f
2. 美团开源视频生成模型 LongCat-Video,兼具文生视频/图生视频/视频续写三大能力,媲美开闭源顶尖模型
美团开源了最新视频生成模型 LongCat-Video,该模型旨在通过统一的架构处理多种视频生成任务,包括文生视频(Text-to-Video)、图生视频(Image-to-Video)以及视频续写(Video-Continuation)。凭借其在通用视频生成任务中的出色表现,LongCat-Video 被研究团队视作向构建真正「世界模型」迈出的坚实一步。
查看完整报道:https://go.hyper.ai/b6pzF
3. CPU 免费用/30 小时 GPU 额度/70GB 超大存储,HyperAI Pro 正式上线!
HyperAI 超神经已经为大家精选了数百个机器学习相关教程,并整理成 Jupyter Notebook 的形式,无论是初学者,亦或经验丰富的工程师,都能够便捷地体验优质开源项目,或是创建全新的模型部署。 HyperAI 超神经用稳定的算力助力 AI 项目从灵感迸发到快速落地。为了更好地满足广大用户的需求,提供更为灵活优惠的算力计费方式,HyperAI 正式上线了会员体系 HyperAI Pro 。
查看完整报道:https://go.hyper.ai/Oi7d3
4. 剑桥大学研发血液细胞图像分类器,扩散模型助力白血病发现,能力超越临床专家
来自英国剑桥大学的研究团队提出了 CytoDiffusion——一种基于扩散模型的血液细胞图像分类方法。它能够忠实建模血细胞形态分布,实现精准分类,同时具备强大的异常检测能力、对分布偏移的抵抗力、可解释性、高数据效率,以及超越临床专家的不确定性量化能力。
查看完整报道:https://go.hyper.ai/QSCmq
5. 靠并购起家,72 岁的博通 CEO 续约至 2030 年,欲将公司 AI 业务收入提至 1200 亿美元
翻看 Hock Tan 的履历,「并购」是绝对难以绕开的话题,但如果仅用商业投资的视角来看待他却实在是狭隘单薄,他的每一次出手,在利润营收的计算之外,也在一步步将自己的公司带入核心位置,其中隐藏的趋势预判更为重要。。
查看完整报道:https://go.hyper.ai/6lPG5
热门百科词条精选
1. DALL-E
2. 超网络 HyperNetworks
3. 帕累托前沿 Pareto Front
4. 双向长短期记忆 Bi-LSTM
5. 倒数排序融合 Reciprocal Rank Fusion
这里汇编了数百条 AI 相关词条,让你在这里读懂「人工智能」:
12 月截稿顶会

一站式追踪人工智能学术顶会:https://go.hyper.ai/event
以上就是本周编辑精选的全部内容,如果你有想要收录 hyper.ai 官方网站的资源,也欢迎留言或投稿告诉我们哦!
下周再见!
关于 HyperAI 超神经 (hyper.ai)
HyperAI 超神经 (hyper.ai) 是国内领先的人工智能及高性能计算社区,致力于成为国内数据科学领域的基础设施,为国内开发者提供丰富、优质的公共资源,截至目前已经:
* 为 1800+ 公开数据集提供国内加速下载节点
* 收录 600+ 经典及流行在线教程
* 解读 200+ AI4Science 论文案例
* 支持 600+ 相关词条查询
* 托管国内首个完整的 Apache TVM 中文文档
访问官网开启学习之旅:








