Command Palette
Search for a command to run...
实战经验丨基于 HyperAI 云算力平台的 Elementwise 算子优化实践
HyperAI 算力平台已经正式上线,通过开箱即用的环境、高性价比的 GPU 定价以及丰富的站内资源,为开发者提供高稳定性的算力服务,加速创意落地。
以下为 HyperAI 用户基于平台进行 Elementwise 算子优化的经验分享 ⬇️
插播一则活动!
目前,HyperAI 内测活动仍在招募中,最高可得 $200 激励,点击了解活动详情:最高可得 $200!HyperAI 内测招募正式开启!
核心目标:将一个简单的逐元素加法算子 (C = A + B ) 从基础实现优化到逼近 PyTorch 原生性能(即逼近硬件的显存带宽极限)。
核心难点:Elementwise 是典型的 Memory Bound(显存受限)算子。
- 算力不是瓶颈(GPU 算加法快得离谱)。
- 瓶颈在于「指令发射端」和「显存搬运端」的供需平衡。
- 优化的本质:用最少的指令(Instruction),搬运最多的数据(Bytes)。
实验环境与算力准备
Elementwise 算子的优化本质是在挑战显存带宽的物理极限。为了获得最准确的 Benchmark 数据,本次实战是在 HyperAI (hyper.ai) 的云端算力平台上完成的。我特意选用了一台配置豪华的实例来压榨算子性能:
- GPU: NVIDIA RTX 5090 (32GB VRAM)
- RAM: 40 GB
- Environment: PyTorch 2.8 / CUDA 12.8
福利时间:如果你也想体验 RTX 5090 复现本文代码,注册 app.hyper.ai 时可以使用我的专属兑换码「EARLY_dnbyl」,即可领取 1 小时 5090 免费算力(1 个月内有效)。
快速开启 RTX 5090 实例
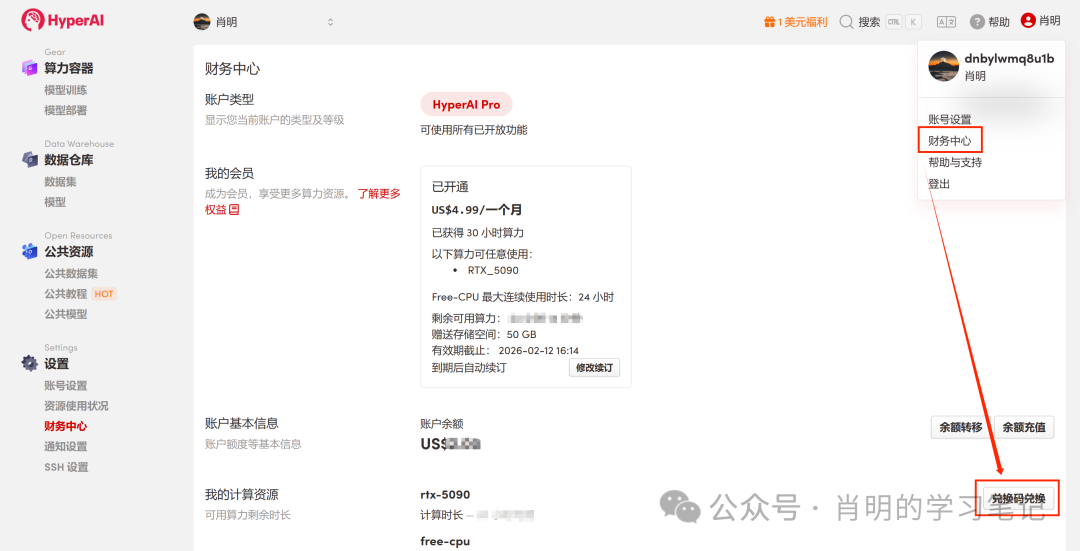
1. 注册与登录:访问 app.hyper.ai 注册账号后,点击右上方「财务中心」,进入后点击「兑换码兑换」,输入「EARLY_dnbyl」领取免费算力。
2. 创建容器:点击左侧边栏「模型训练」->「选择算力:5090」->「选择镜像:PyTorch 2.8」->「接入方式:Jupyter」->「容器名称:任意填写,例如 cuda_kernels」->「执行」。
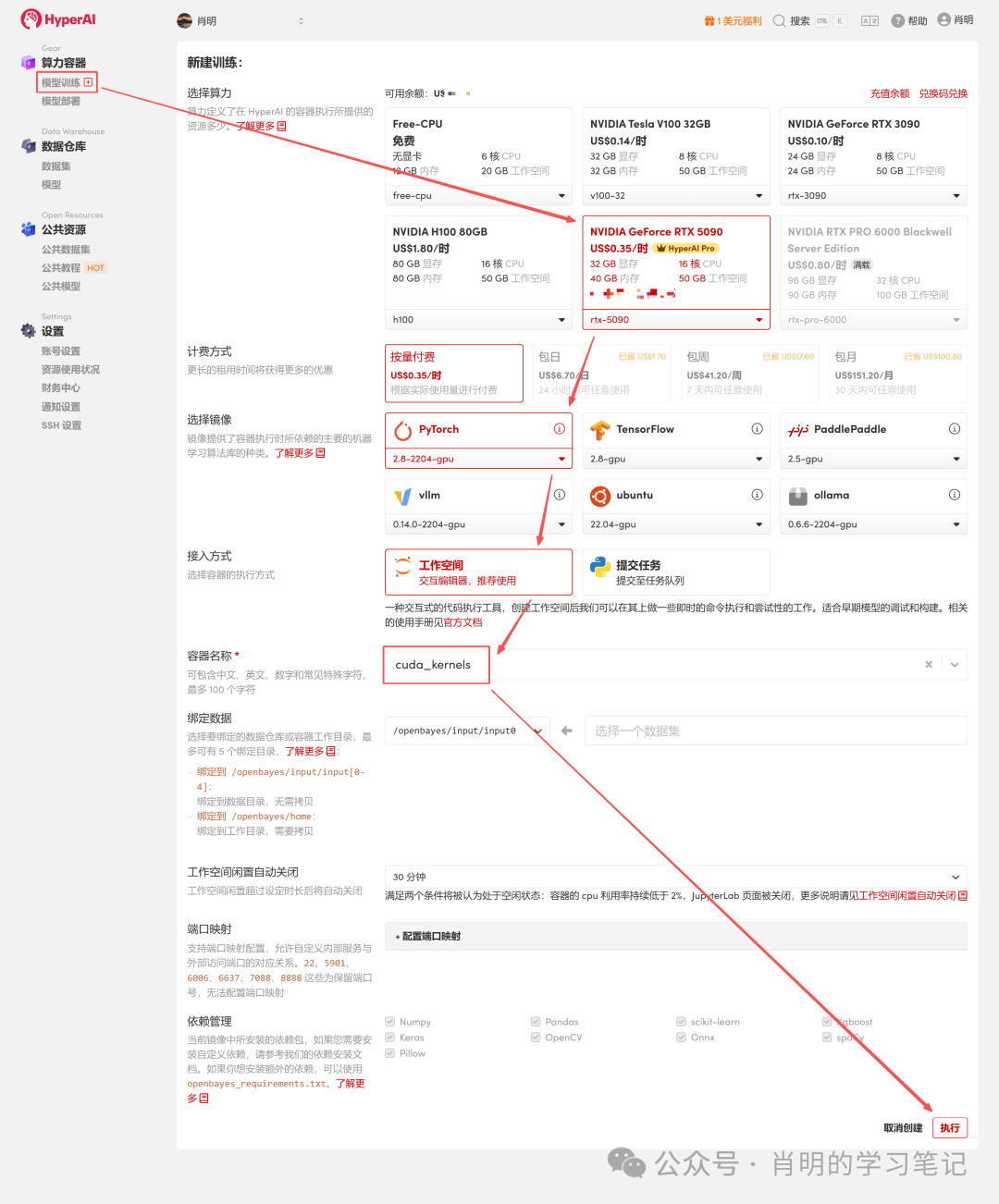
3. 打开 Jupyter:实例启动后(状态变为「运行中」),直接点击「打开工作空间」一键即用
平台支持使用 Jupyter 或 VS Code SSH Remote 进行连接。我使用的是 Jupyter,在第一个 Cell 中运行以下命令:
import os
import torch
from torch.utils.cpp_extension import load第一阶段:FP32 优化系列
1.Version 1: FP32 Baseline (标量版)
这是最符合直觉的写法,但在 GPU 看来效率平平。
原理深度解析:
- 指令层:Scheduler 发射 1 条 LD.E (32-bit Load) 指令。
- 执行层(Warp):依据 SIMT 原则,Warp 内的 32 个线程同时执行这条指令。
- 数据量:每个线程搬运 4 字节。总数据量 =32 threads × 4 Bytes = 128 Bytes 。
- 显存事务:LSU(Load Store Unit)将这 128 字节合并为 1 个显存事务。
- 瓶颈分析:虽然利用了显存合并,但指令效率低。为了搬运 128 字节数据,SM(流多处理器)必须消耗 1 个指令发射周期。对于海量数据,指令发射单元会忙死,成为瓶颈。
代码 (v1_f32.cu):
%%writefile v1_f32.cu
#include <torch/extension.h>
#include <cuda_runtime.h>
__global__ void elementwise_add_f32_kernel(float *a, float *b, float *c, int N) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < N) {
c[idx] = a[idx] + b[idx];
}
}
void elementwise_add_f32(torch::Tensor a, torch::Tensor b, torch::Tensor c) {
int N = a.numel();
int threads_per_block = 256;
int blocks_per_grid = (N + threads_per_block - 1) / threads_per_block;
elementwise_add_f32_kernel<<<blocks_per_grid, threads_per_block>>>(
a.data_ptr<float>(), b.data_ptr<float>(), c.data_ptr<float>(), N
);
}
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
m.def("add", &elementwise_add_f32, "FP32 Add");
}2.Version 2: FP32x4 Vectorized (向量化版)
优化手段:使用 float4 类型,强制生成 128-bit 加载指令。
原理深度解析(核心优化点):
- 指令层:Scheduler 发射 1 条 LD.E.128 (128-bit Load) 指令。
- 执行层(Warp):Warp 内 32 个线程同时执行,但这次每人搬运 16 字节(float4)。
- 数据量:总数据量 = 32 threads x 16 Bytes = 512 Bytes 。
- 显存事务:LSU 看到 512 字节的连续请求,会连续发起 4 个 128B 显存事务。
- 效率对比:Baseline:1 指令 = 128 字节。 Vectorized:1 指令 = 512 字节。
- 结论:指令效率提升 4 倍。 SM 只需要原来 1/4 的指令数,就能吃满同样的显存带宽。这彻底解放了指令发射单元,让瓶颈真正转移到了显存带宽上。
代码 (v2_f32x4.cu):
%%writefile v2_f32x4.cu
#include <torch/extension.h>
#include <cuda_runtime.h>
#define FLOAT4(value) (reinterpret_cast<float4 *>(&(value))[0])
__global__ void elementwise_add_f32x4_kernel(float *a, float *b, float *c, int N) {
int tid = blockIdx.x * blockDim.x + threadIdx.x;
int idx = 4 * tid;
if (idx + 3 < N) {
float4 reg_a = FLOAT4(a[idx]);
float4 reg_b = FLOAT4(b[idx]);
float4 reg_c;
reg_c.x = reg_a.x + reg_b.x;
reg_c.y = reg_a.y + reg_b.y;
reg_c.z = reg_a.z + reg_b.z;
reg_c.w = reg_a.w + reg_b.w;
FLOAT4(c[idx]) = reg_c;
}
else if (idx < N){
for (int i = 0; i < 4; i++){
if (idx + i < N) {
c[idx + i] = a[idx + i] + b[idx + i];
}
}
}
}
void elementwise_add_f32x4(torch::Tensor a, torch::Tensor b, torch::Tensor c) {
int N = a.numel();
int threads_per_block = 256 / 4;
int blocks_per_grid = (N + 256 - 1) / 256;
elementwise_add_f32x4_kernel<<<blocks_per_grid, threads_per_block>>>(
a.data_ptr<float>(), b.data_ptr<float>(), c.data_ptr<float>(), N
);
}
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
m.def("add", &elementwise_add_f32x4, "FP32x4 Add");第二阶段:FP16 优化系列
3.Version 3: FP16 Baseline (半精度标量)
使用 half (FP16) 节省显存。
原理深度解析(为何它很慢?):
- 访存模式:代码中 idx 连续,因此 32 个线程的访问是完全合并的。
- 数据量:32 个线程 × 2 Bytes = 64 Bytes(一个 Warp 的总请求量)。
- 硬件行为:显存控制器(LSU)会生成 2 个 32-byte 的显存扇区事务。注意:这里没有浪费带宽,传输的全是有效数据。
真正的瓶颈:
1. 指令发射瓶颈(Instruction Bound):
这是核心原因。为了填满显存带宽,我们需要源源不断地搬运数据。此版本中,1 条指令只能搬运 64 字节。对比 float4 版本(1 条指令搬运 512 字节),本版本的指令效率仅为 1/8 。
后果:SM 的指令发射单元(Scheduler)即使全速运转,发出的指令所携带的数据量也喂不饱巨大的显存带宽。包工头喊破喉咙(发射指令), 工人搬的砖(数据量)也不够多。
2. 显存事务粒度过小:
* 物理层:显存最小传输单位是 32B 扇区;缓存层:通常以 128B 缓存行为单位管理。
* 现状:Warp 请求的 64B 数据虽然填满了 2 个扇区,但对于 128B 的缓存行来说,只用了 一半。
* 后果:这种「零售式」的小包数据传输,相比于 float4 那种一次性搬运 4 个完整缓存行(512B)的「批发式」传输,在此吞吐量下效率极低,且无法掩盖显存的高延迟。为了填满显存带宽,我们需要源源不断地搬运数据。
代码 (v3_f16.cu):
%%writefile v3_f16.cu
#include <torch/extension.h>
#include <cuda_fp16.h>
__global__ void elementwise_add_f16_kernel(half *a, half *b, half *c, int N) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < N) {
c[idx] = __hadd(a[idx], b[idx]);
}
}
void elementwise_add_f16(torch::Tensor a, torch::Tensor b, torch::Tensor c) { int N = a.numel();
int threads_per_block = 256;
int blocks_per_grid = (N + threads_per_block - 1) / threads_per_block;
elementwise_add_f16_kernel<<<blocks_per_grid, threads_per_block>>>( reinterpret_cast<half*>(a.data_ptr<at::Half>()),
reinterpret_cast<half*>(b.data_ptr<at::Half>()),
reinterpret_cast<half*>(c.data_ptr<at::Half>()),
N
);
}
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
m.def("add", &elementwise_add_f16, "FP16 Add");
}4.Version 4: FP16 Vectorized (Half2)
引入 half2 。
原理深度解析:
- 数据:half2 (4 字节) 。
- 指令层:发射 32-bit Load 指令。
- 算力层:使用 __hadd2 (SIMD),一条指令同时算 2 对加法。
- 现状:访存效率等同于 FP32 Baseline(1 指令 = 128 字节)。虽然比 V3 快了,但依然没有达到 float4 那种 512 字节/指令 的巅峰状态。
代码 (v4_f16x2.cu):
%%writefile v3_f16.cu
#include <torch/extension.h>
#include <cuda_fp16.h>
__global__ void elementwise_add_f16_kernel(half *a, half *b, half *c, int N) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < N) {
c[idx] = __hadd(a[idx], b[idx]);
}
}
void elementwise_add_f16(torch::Tensor a, torch::Tensor b, torch::Tensor c) {
int N = a.numel();
int threads_per_block = 256;
int blocks_per_grid = (N + threads_per_block - 1) / threads_per_block;
elementwise_add_f16_kernel<<<blocks_per_grid, threads_per_block>>>(
reinterpret_cast<half*>(a.data_ptr<at::Half>()),
reinterpret_cast<half*>(b.data_ptr<at::Half>()),
reinterpret_cast<half*>(c.data_ptr<at::Half>()),
N
);
}
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
m.def("add", &elementwise_add_f16, "FP16 Add");
}hyper Jupyter 运行示例见附录
5.Version 5: FP16x8 Unroll (手动循环展开)
为了进一步挖掘性能,我们尝试让 1 个线程处理 8 个 half(即 4 个 half2)。
原理深度解析(对比 V4 的提升在哪里?):
- 做法:在代码中手动连续写 4 行 half2 读取操作。
- 效果:Scheduler 会连续发射 4 条 32-bit Load 指令。
- 收益:ILP (指令级并行) 与 延迟掩盖。 V4 (FP16x2) 的问题:发射 1 条指令 -> 傻等数据返回 (Stall) -> 计算。在等待期间,GPU 没事干。 V5 的改进:连发 4 条指令。当 GPU 还在等待第 1 条数据从显存返回时,它已经把第 2 、 3 、 4 条指令发出去了。这充分利用了指令流水线的空隙,掩盖了昂贵的显存延迟。
- 局限:指令密度依然很高。虽然利用了 ILP,但本质上还是发起了 4 次 32-bit 的「小车运输」。为了搬运 128 bit 的数据,SM 依然消耗了 4 个指令发射周期。指令发射端依然非常忙碌,没有达到「一条指令搬一座山」的效果。
代码 (v5_f16x8.cu):
%%writefile v5_f16x8.cu
#include <torch/extension.h>
#include <cuda_fp16.h>
#define HALF2(value) (reinterpret_cast<half2 *>(&(value))[0])
__global__ void elementwise_add_f16x8_kernel(half *a, half *b, half *c, int N) {
int idx = 8 * (blockIdx.x * blockDim.x + threadIdx.x);
if (idx + 7 < N) {
half2 ra0 = HALF2(a[idx + 0]);
half2 ra1 = HALF2(a[idx + 2]);
half2 ra2 = HALF2(a[idx + 4]);
half2 ra3 = HALF2(a[idx + 6]);
half2 rb0 = HALF2(b[idx + 0]);
half2 rb1 = HALF2(b[idx + 2]);
half2 rb2 = HALF2(b[idx + 4]);
half2 rb3 = HALF2(b[idx + 6]);
HALF2(c[idx + 0]) = __hadd2(ra0, rb0);
HALF2(c[idx + 2]) = __hadd2(ra1, rb1);
HALF2(c[idx + 4]) = __hadd2(ra2, rb2);
HALF2(c[idx + 6]) = __hadd2(ra3, rb3);
}
else if (idx < N) {
for(int i = 0; i < 8; i++){
if (idx + i < N) {
c[idx + i] = __hadd(a[idx + i], b[idx + i]);
}
}
}
}
void elementwise_add_f16x8(torch::Tensor a, torch::Tensor b, torch::Tensor c) {
int N = a.numel();
int threads_per_block = 256 / 8;
int blocks_per_grid = (N + 256 - 1) / 256;
elementwise_add_f16x8_kernel<<<blocks_per_grid, threads_per_block>>>(
reinterpret_cast<half*>(a.data_ptr<at::Half>()),
reinterpret_cast<half*>(b.data_ptr<at::Half>()),
reinterpret_cast<half*>(c.data_ptr<at::Half>()),
N
);
}
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
m.def("add", &elementwise_add_f16x8, "FP16x8 Add");
}hyper Jupyter 运行示例见附录
6.Version 6: FP16x8 Pack (终极优化)
这是 Elementwise 算子优化的天花板。我们结合了 V2 的「大宽带搬运」和 V5 的「指令级并行」,并引入了寄存器缓存技术。
核心魔法深度解析:
1. 地址伪装:
* 问题:我们的数据是 half 类型,GPU 并没有原生的 load_8_halfs 这种指令。
* 对策: float4 类型恰好占用 128 位(16 字节),而 8 个 half 也占用 128 位。
* 操作:我们把 half 数组的地址强行转换( reinterpret_cast )为 float4* 。
* 效果:编译器看到 float4* ,就会生成 1 条 LD.E.128 指令。显存控制器才不管你搬的是什么,它只管一次搬运 128 bit 的二进制流。
2. 寄存器数组 (Register Array):
half pack_a[8] :这个数组虽然定义在 Kernel 里,但因为是固定大小且很小,编译器会把它直接映射到 GPU 的寄存器文件 (Register File) 中,而不是慢速的 Local Memory 。这就相当于在「手边」开辟了一块极速缓存区。
3. 内存再解释 (Reinterpretation):
宏定义 LDST128BITS:这是本代码的灵魂。它把任何变量的地址强转为 float4* 并取值。
LDST128BITS(pack_a[0])=LDST128BITS(a[idx]);
* 右边:去 Global Memory a[idx] 处,抓取 128 bit 数据。
* 左边:把这 128 bit 数据直接覆盖写入到 pack_a 数组(从第 0 个元素开始填,瞬间填满 8 个)。
* 结果:1 条指令,瞬间完成 8 个数据的搬运。
代码 (v6_f16x8_pack.cu):
%%writefile v6_f16x8_pack.cu
#include <torch/extension.h>
#include <cuda_fp16.h>
#define LDST128BITS(value) (reinterpret_cast<float4 *>(&(value))[0])
#define HALF2(value) (reinterpret_cast<half2 *>(&(value))[0])
__global__ void elementwise_add_f16x8_pack_kernel(half *a, half *b, half *c, int N) {
int idx = 8 * (blockIdx.x * blockDim.x + threadIdx.x);
half pack_a[8], pack_b[8], pack_c[8];
if ((idx + 7) < N) {
LDST128BITS(pack_a[0]) = LDST128BITS(a[idx]);
LDST128BITS(pack_b[0]) = LDST128BITS(b[idx]);
#pragma unroll
for (int i = 0; i < 8; i += 2) {
HALF2(pack_c[i]) = __hadd2(HALF2(pack_a[i]), HALF2(pack_b[i]));
}
LDST128BITS(c[idx]) = LDST128BITS(pack_c[0]);
}
else if (idx < N) {
for (int i = 0; i < 8; i++) {
if (idx + i < N) {
c[idx + i] = __hadd(a[idx + i], b[idx + i]);
}
}
}
}
void elementwise_add_f16x8_pack(torch::Tensor a, torch::Tensor b, torch::Tensor c) {
int N = a.numel();
int threads_per_block = 256 / 8;
int blocks_per_grid = (N + 256 - 1) / 256;
elementwise_add_f16x8_pack_kernel<<<blocks_per_grid, threads_per_block>>>(
reinterpret_cast<half*>(a.data_ptr<at::Half>()),
reinterpret_cast<half*>(b.data_ptr<at::Half>()),
reinterpret_cast<half*>(c.data_ptr<at::Half>()),
N
);
}
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
m.def("add", &elementwise_add_f16x8_pack, "FP16x8 Pack Add");
}第三阶段:综合 Benchmark 与可视化分析
为了全方位评估优化效果,我们设计了一个覆盖延迟敏感型(小数据)到带宽敏感型(大数据)的全场景测试方案。
1. 测试策略设计
我们选取了三组具有代表性的数据规模,分别对应 GPU 内存层级的不同瓶颈:
- Cache Latency (1M 元素):数据量极小(4MB),完全命中 L2 Cache 。测试核心在于 Kernel 启动延迟 (Launch Overhead) 和指令发射效率。
- L2 Throughput (16M 元素):数据量中等(64MB),接近 L2 Cache 容量上限。测试核心在于 L2 Cache 的读写吞吐能力。
- VRAM Bandwidth (256M 元素):数据量巨大(1GB),远超 L2 Cache 。数据必须从显存(VRAM)搬运。这是大模型算子的真实战场,测试核心在于是否跑满了物理显存带宽
2.Benchmark 脚本 (Python)
该脚本直接加载上述定义的 .cu 文件,并自动计算带宽(GB/s)与耗时(ms)。
import torch
from torch.utils.cpp_extension import load
import time
import os
# ==========================================
# 0. 准备工作
# ==========================================
# 确保你的文件路径和笔记里写的一致
kernel_dir = "."
flags = ["-O3", "--use_fast_math", "-U__CUDA_NO_HALF_OPERATORS__"]
print(f"Loading kernels from {kernel_dir}...")
# ==========================================
# 1. 分别加载 6 个模块
# ==========================================
# 我们分别编译加载,确保每个模块有独立的命名空间,避免符号冲突
try:
mod_v1 = load(name="v1_lib", sources=[os.path.join(kernel_dir, "v1_f32.cu")], extra_cuda_cflags=flags, verbose=False)
mod_v2 = load(name="v2_lib", sources=[os.path.join(kernel_dir, "v2_f32x4.cu")], extra_cuda_cflags=flags, verbose=False)
mod_v3 = load(name="v3_lib", sources=[os.path.join(kernel_dir, "v3_f16.cu")], extra_cuda_cflags=flags, verbose=False)
mod_v4 = load(name="v4_lib", sources=[os.path.join(kernel_dir, "v4_f16x2.cu")], extra_cuda_cflags=flags, verbose=False)
mod_v5 = load(name="v5_lib", sources=[os.path.join(kernel_dir, "v5_f16x8.cu")], extra_cuda_cflags=flags, verbose=False)
mod_v6 = load(name="v6_lib", sources=[os.path.join(kernel_dir, "v6_f16x8_pack.cu")], extra_cuda_cflags=flags, verbose=False)
print("All Kernels Loaded Successfully!\n")
except Exception as e:
print("\n[Error] 加载失败!请检查目录下是否有这 6 个 .cu 文件,且代码已修正语法错误。")
print(f"详细报错: {e}")
raise e
# ==========================================
# 2. Benchmark 工具函数
# ==========================================
def run_benchmark(func, a, b, tag, out, warmup=10, iters=1000):
# 重置输出
out.fill_(0)
# Warmup (预热,让 GPU 进入高性能状态)
for _ in range(warmup):
func(a, b, out)
torch.cuda.synchronize()
# Timing (计时)
start = time.time()
for _ in range(iters):
func(a, b, out)
torch.cuda.synchronize()
end = time.time()
# Metrics (指标计算)
avg_time_ms = (end - start) * 1000 / iters
# Bandwidth Calculation: (Read A + Read B + Write C)
element_size = a.element_size() # float=4, half=2
total_bytes = 3 * a.numel() * element_size
bandwidth_gbs = total_bytes / (avg_time_ms / 1000) / 1e9
# Check Result (打印前 2 个元素用于验证正确性)
# 取数据回 CPU 检查
out_val = out.flatten()[:2].cpu().float().tolist()
out_val = [round(v, 4) for v in out_val]
print(f"{tag:<20} | Time: {avg_time_ms:.4f} ms | BW: {bandwidth_gbs:>7.1f} GB/s | Check: {out_val}")
# ==========================================
# 3. 运行测试 (从小到大)
# ==========================================
# 1M = 2^20
shapes = [
(1024, 1024), # 1M elems (Cache Latency)
(4096, 4096), # 16M elems (L2 Cache 吞吐)
(16384, 16384), # 256M elems (显存带宽压测)
]
print(f"{'='*90}")
print(f"Running Benchmark on {torch.cuda.get_device_name(0)}")
print(f"{'='*90}\n")
for S, K in shapes:
N = S * K
print(f"--- Data Size: {N/1e6:.1f} M Elements ({N*4/1024/1024:.0f} MB FP32) ---")
# --- FP32 测试 ---
a_f32 = torch.randn((S, K), device="cuda", dtype=torch.float32)
b_f32 = torch.randn((S, K), device="cuda", dtype=torch.float32)
c_f32 = torch.empty_like(a_f32)
# 注意:这里调用的是 .add 方法,因为你在 PYBIND11 里面定义的名字是 "add"
run_benchmark(mod_v1.add, a_f32, b_f32, "V1 (FP32 Base)", c_f32)
run_benchmark(mod_v2.add, a_f32, b_f32, "V2 (FP32 Vec)", c_f32)
# PyTorch 原生对照
run_benchmark(lambda a,b,c: torch.add(a,b,out=c), a_f32, b_f32, "PyTorch (FP32)", c_f32)
# --- FP16 测试 ---
print("-" * 60)
a_f16 = a_f32.half()
b_f16 = b_f32.half()
c_f16 = c_f32.half()
run_benchmark(mod_v3.add, a_f16, b_f16, "V3 (FP16 Base)", c_f16)
run_benchmark(mod_v4.add, a_f16, b_f16, "V4 (FP16 Half2)", c_f16)
run_benchmark(mod_v5.add, a_f16, b_f16, "V5 (FP16 Unroll)", c_f16)
run_benchmark(mod_v6.add, a_f16, b_f16, "V6 (FP16 Pack)", c_f16)
# PyTorch 原生对照
run_benchmark(lambda a,b,c: torch.add(a,b,out=c), a_f16, b_f16, "PyTorch (FP16)", c_f16)
print("\n")
3. 实战数据:RTX 5090 真实表现
以下是在 NVIDIA GeForce RTX 5090 上运行上述代码获得的真实数据:
==========================================================================================
Running Benchmark on NVIDIA GeForce RTX 5090
==========================================================================================---
Data Size: 1.0 M Elements (4 MB FP32) ---
V1 (FP32 Base) | Time: 0.0041 ms | BW: 3063.1 GB/s | Check: [0.8656, 1.9516]
V2 (FP32 Vec) | Time: 0.0041 ms | BW: 3066.1 GB/s | Check: [0.8656, 1.9516]
PyTorch (FP32) | Time: 0.0044 ms | BW: 2868.9 GB/s | Check: [0.8656, 1.9516]
------------------------------------------------------------
V3 (FP16 Base) | Time: 0.0041 ms | BW: 1531.9 GB/s | Check: [0.8657, 1.9512]
V4 (FP16 Half2) | Time: 0.0041 ms | BW: 1531.9 GB/s | Check: [0.8657, 1.9512]
V5 (FP16 Unroll) | Time: 0.0041 ms | BW: 1533.5 GB/s | Check: [0.8657, 1.9512]
V6 (FP16 Pack) | Time: 0.0041 ms | BW: 1533.6 GB/s | Check: [0.8657, 1.9512]
PyTorch (FP16) | Time: 0.0044 ms | BW: 1431.6 GB/s | Check: [0.8657, 1.9512]
--- Data Size: 16.8 M Elements (64 MB FP32) ---
V1 (FP32 Base) | Time: 0.1183 ms | BW: 1702.2 GB/s | Check: [-3.2359, -0.1663]
V2 (FP32 Vec) | Time: 0.1186 ms | BW: 1698.1 GB/s | Check: [-3.2359, -0.1663]
PyTorch (FP32) | Time: 0.1176 ms | BW: 1711.8 GB/s | Check: [-3.2359, -0.1663]
------------------------------------------------------------
V3 (FP16 Base) | Time: 0.0348 ms | BW: 2891.3 GB/s | Check: [-3.2363, -0.1664]
V4 (FP16 Half2) | Time: 0.0348 ms | BW: 2891.3 GB/s | Check: [-3.2363, -0.1664]
V5 (FP16 Unroll) | Time: 0.0348 ms | BW: 2892.8 GB/s | Check: [-3.2363, -0.1664]
V6 (FP16 Pack) | Time: 0.0348 ms | BW: 2892.6 GB/s | Check: [-3.2363, -0.1664]
PyTorch (FP16) | Time: 0.0148 ms | BW: 6815.7 GB/s | Check: [-3.2363, -0.1664]
--- Data Size: 268.4 M Elements (1024 MB FP32) ---
V1 (FP32 Base) | Time: 2.0432 ms | BW: 1576.5 GB/s | Check: [0.4839, -2.6795]
V2 (FP32 Vec) | Time: 2.0450 ms | BW: 1575.2 GB/s | Check: [0.4839, -2.6795]
PyTorch (FP32) | Time: 2.0462 ms | BW: 1574.3 GB/s | Check: [0.4839, -2.6795]
------------------------------------------------------------
V3 (FP16 Base) | Time: 1.0173 ms | BW: 1583.2 GB/s | Check: [0.4839, -2.6797]
V4 (FP16 Half2) | Time: 1.0249 ms | BW: 1571.5 GB/s | Check: [0.4839, -2.6797]
V5 (FP16 Unroll) | Time: 1.0235 ms | BW: 1573.6 GB/s | Check: [0.4839, -2.6797]
V6 (FP16 Pack) | Time: 1.0236 ms | BW: 1573.4 GB/s | Check: [0.4839, -2.6797]
PyTorch (FP16) | Time: 1.0251 ms | BW: 1571.2 GB/s | Check: [0.4839, -2.6797]
4. 数据解读
这份数据清晰地展示了 RTX 5090 在不同负载下的物理特性:
阶段一:极小规模 (1M Elements / 4MB)
- 现象:所有版本的耗时惊人一致,均为 0.0041 ms 。
- 真相:此时是 Latency Bound (延迟受限) 。不管数据多小,GPU 启动一个 Kernel 的固定开销(Launch Overhead)就是约 4 微秒。因为耗时锁死,FP16 数据量只有 FP32 的一半,所以算出来的带宽自然只有一半。这里测的不是传输速度,而是「点火速度」。
阶段二:中等规模 (16M Elements / 64MB vs 32MB)
这是最能体现 L2 Cache 作用的区域:
- FP32 (64MB):总数据量 A+B+C≈192MB 。这超过了 RTX 5090 的 L2 Cache 容量(约 128MB)。数据溢出,被迫去读写 VRAM,所以带宽掉到了 1700 GB/s(接近显存物理带宽)。
- FP16 (32MB):总数据量 。刚好能塞进 L2 Cache! 数据在高速缓存内循环,所以带宽飙升至 2890 GB/s 。
- PyTorch 的黑魔法:注意 PyTorch 在 FP16 下跑出了 6815 GB/s 。这说明在纯 Cache 场景下,JIT 编译器的指令流水线优化依然强于简单的手写 Kernel 。
阶段三:大规模 (268M Elements / 1024MB)
这是大模型训练/推理的真实场景(Memory Bound):
- 众生平等:无论是 FP32 还是 FP16,无论是 Baseline 还是 Optimized,带宽全部死死锁定在 1570 – 1580 GB/s 。
- 物理墙:我们成功触碰到了 RTX 5090 的 GDDR7 显存带宽物理极限。水管就这么粗,谁也别想运得更快。
- 优化的价值:虽然带宽没变,但发现 FP16 的耗时 (1.02ms) 只有 FP32 (2.04ms) 的一半。在跑满带宽的前提下,将数据量减半,有 2x 的端到端加速。 V6 vs V3:虽然看起来 V3 也跑满了,这是因为 NVCC 编译器自动优化 和 GPU 硬件延迟掩盖 帮了忙。但在更复杂的算子(如 FlashAttention)中,V6 的写法才是性能的保障。
核心 FAQ:参数设计的硬核推演
在本次实验的所有 Kernel 中,我们不约而同地设置了一个参数:threads_per_block = 256 。这个数字并非随手一填,而是在硬件限制与调度效率之间做出的数学最优解。
Q: 为什么 threads_per_block 总是设为 128 或 256?
A: 这是一个通过四层筛选得出的「黄金区间」。
我们将 block_size 的选值过程看作一个漏斗,层层过滤:
1.Warp 对齐 (Warp Alignment) -> 必须是 32 的倍数
GPU 的最小执行单元是 Warp (线程束),由 32 个连续线程组成(SIMT 架构,单指令多线程)。
- 硬限制:如果你申请 31 个线程,硬件依然会调度 1 个完整的 Warp,剩下的 1 个线程位置虽然闲置,但依然占用相同的硬件资源。
- 结论: block_size 最好是 32 的整数倍,以避免算力浪费。
2.Occupancy 下限 (Occupancy Floor) -> 必须 >= 96
Occupancy (占用率) = 当前 SM 上并发执行的线程数 / SM 支持的最大线程数。
- 背景:为了掩盖显存延迟,我们需要足够多的 Active Warps 。如果 Block 太小,SM 的 “Max Blocks” 限制会先于 “Max Threads” 限制被触顶。
- 推算:主流架构(如 Turing/Ampere/Ada)通常要求: block_size > (SM 最大线程数 / SM 最大 Block 数) 。常见的比值有 64 或 96 。
- 结论:为了理论上能达到 100% Occupancy, block_size 不应小于 96 。
3. 调度原子性 (Scheduling Atomicity) -> 锁定 128, 256, 512
Block 是调度给 SM 的最小原子单位。 SM 必须能完整吃下整数个 Block 。
- 整除性:为了不浪费 SM 的容量, block_size 最好能被 SM 的最大线程容量整除。
- 筛选:主流架构 SM 最大容量通常为 1024, 1536, 2048 等。它们的公约数通常是 512 。结合前两步(>=96 且是 32 倍数),我们的候选名单缩小为:128, 192, 256, 384, 512 。
4. 寄存器压力 (Register Pressure) -> 排除 512+
这是最后的「天花板」。
- 硬限制:每个 Block 能用的寄存器总数有限(SM 总寄存器通常为 64K 个 32bit)。
- 风险:如果 block_size 很大(如 512),而 Kernel 又稍微复杂一点(每个线程多用几个寄存器),就会出现 512 * Regs/Thread > Max_Regs_Per_Block 的情况。
- 后果:启动失败:直接报错。 Register Spill:寄存器溢出到慢速的 Local Memory,性能雪崩。
- 结论:为了安全(Safe Bet),我们通常避免使用 512 或 1024 。 128 和 256 是最安全的「甜点区」。
总结
经过四层漏斗筛选,只剩下两位选手:
- 128:通用性最强。即使 Kernel 很复杂(寄存器用得多),也能保证成功启动且 Occupancy 不错。
- 256:elementwise 算子首选。对于逐元素这类逻辑简单的算子,寄存器压力极小。 256 能提供比 128 更好的访存合并潜力(Coalescing),且减少了 Block 的调度开销。
这也解释了为什么在朴素实现中,我们一旦确定了 threads_per_block = 256,grid_size 也就随之确定了(只要保证总量覆盖 N 即可)。
附录: Jupyter 运行示例