Command Palette
Search for a command to run...
Shuming Liu Chen-Lin Zhang Chen Zhao Bernard Ghanem
摘要
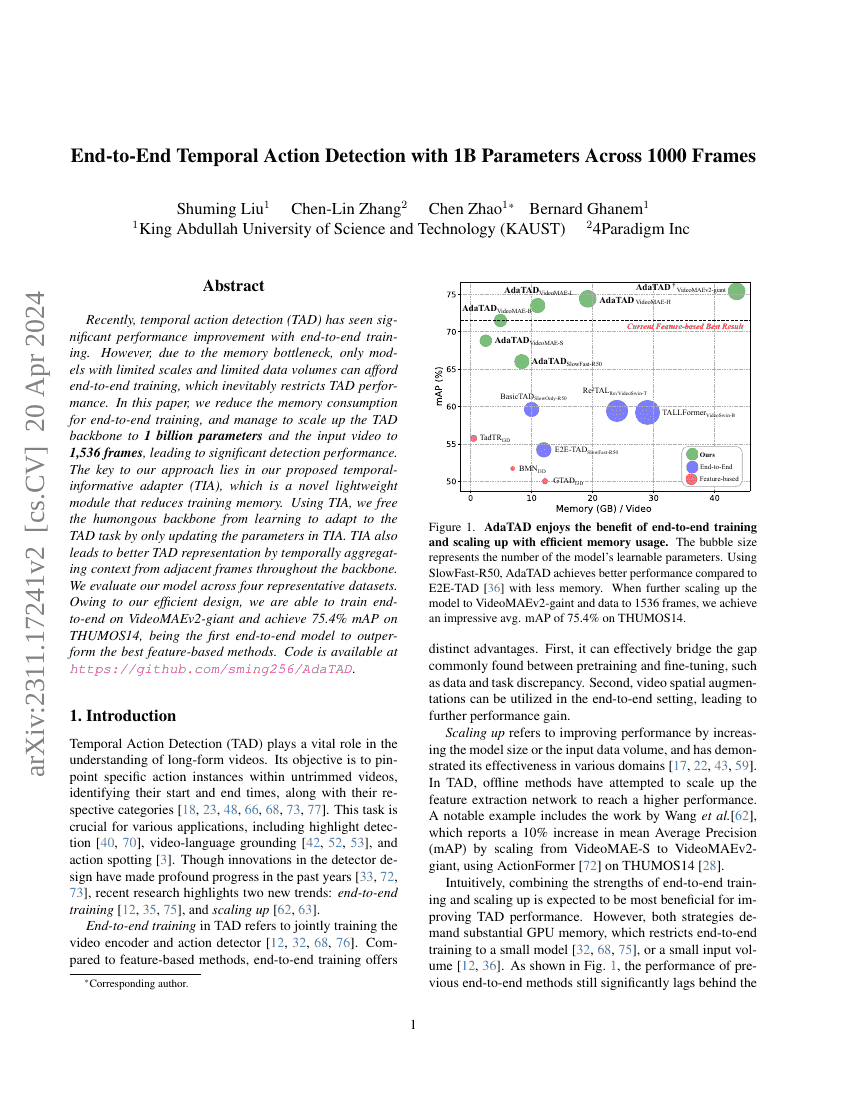
近年来,基于端到端训练的时序动作检测(Temporal Action Detection, TAD)取得了显著的性能提升。然而,由于内存瓶颈的限制,仅有参数量有限且输入视频数据量较小的模型能够支持端到端训练,这不可避免地制约了TAD性能的进一步突破。本文提出了一种有效降低端到端训练内存消耗的方法,成功将TAD主干网络扩展至10亿参数规模,并支持长达1,536帧的输入视频,显著提升了检测性能。本方法的核心在于我们提出的时序信息适配器(Temporal-Informative Adapter, TIA),这是一种新颖的轻量级模块,能够显著减少训练过程中的内存占用。通过TIA,我们仅需更新其自身参数,即可使庞大的主干网络无需重新学习适配TAD任务,从而大幅降低训练负担。此外,TIA通过在主干网络中对相邻帧的时序上下文进行聚合,进一步增强了TAD的表征能力。我们在四个具有代表性的数据集上对模型进行了全面评估。得益于高效的设计,我们首次在VideoMAEv2-giant数据集上实现了端到端训练,并在THUMOS14数据集上取得了75.4%的mAP,成为首个超越最优基于特征的方法的端到端模型。相关代码已开源,地址为:https://github.com/sming256/AdaTAD。
代码仓库
sming256/OpenTAD
官方
pytorch
sming256/AdaTAD
pytorch
GitHub 中提及
基准测试
| 基准 | 方法 | 指标 |
|---|---|---|
| temporal-action-localization-on-activitynet | AdaTAD (VideoMAEv2-giant) | |
| temporal-action-localization-on-epic-kitchens | AdaTAD (verb, VideoMAE-L) | Avg mAP (0.1-0.5): 29.3 mAP [email protected]: 33.1 mAP [email protected]: 32.2 mAP [email protected]: 30.4 mAP [email protected]: 27.5 mAP [email protected]: 23.1 |
| temporal-action-localization-on-thumos14 | AdaTAD (VideoMAEv2-giant) | Avg mAP (0.3:0.7): 76.9 mAP [email protected]: 89.7 mAP [email protected]: 86.7 mAP [email protected]: 80.9 mAP [email protected]: 71.0 mAP [email protected]: 56.1 |