Command Palette
Search for a command to run...
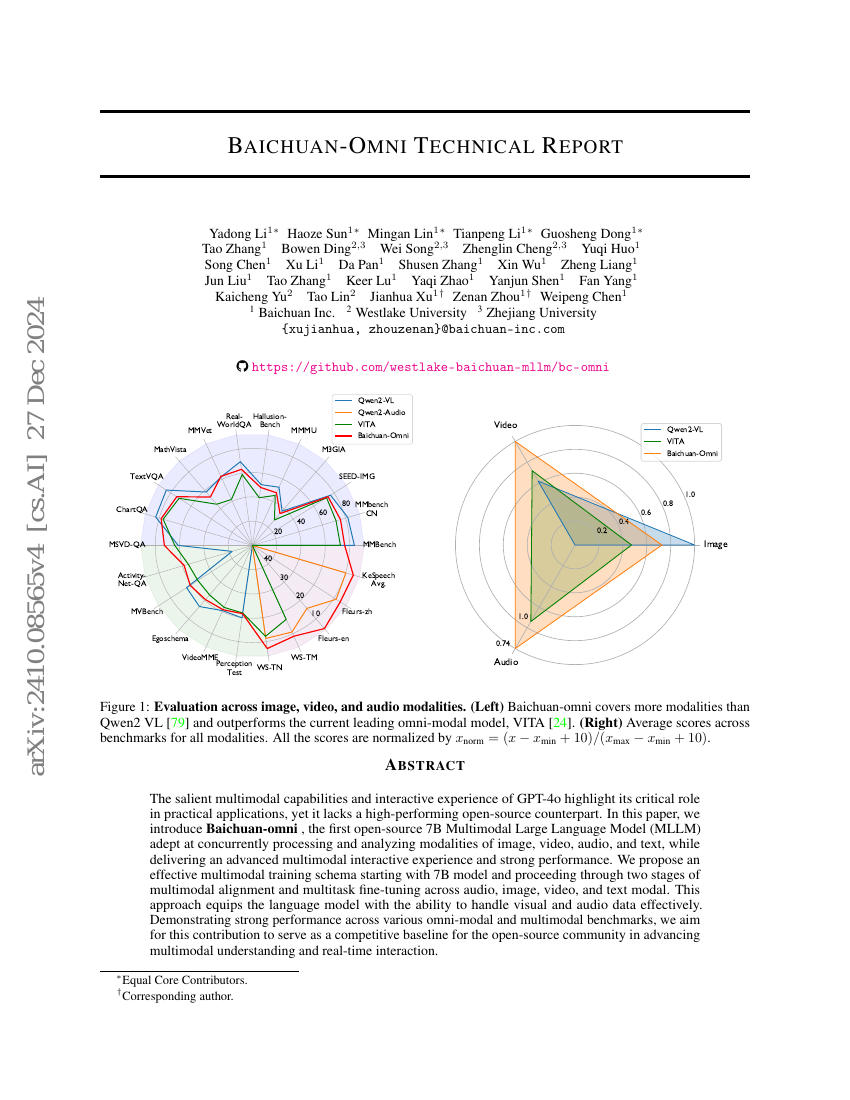
摘要
GPT-4o 凭借其突出的多模态能力与交互体验,展现出在实际应用中的关键作用,然而目前尚缺乏高性能的开源替代方案。本文提出 Baichuan-Omni,这是首个开源的 7B 参数多模态大语言模型(MLLM),能够同时处理并分析图像、视频、音频与文本等多种模态信息,同时提供先进的多模态交互体验与优异的性能表现。我们设计了一种高效的多模态训练框架,从 7B 参数模型出发,依次经过两个阶段:多模态对齐与跨模态(音频、图像、视频、文本)多任务微调。该方法使语言模型具备了有效处理视觉与音频数据的能力。在多个全模态(omni-modal)与多模态基准测试中,Baichuan-Omni 均展现出强劲的性能。我们期望本工作能为开源社区提供一个具有竞争力的基准,推动多模态理解与实时交互技术的进一步发展。
代码仓库
westlake-baichuan-mllm/ocean-omni
官方
GitHub 中提及
westlake-baichuan-mllm/bc-omni
官方
GitHub 中提及
基准测试
| 基准 | 方法 | 指标 |
|---|---|---|
| visual-question-answering-on-mm-vet | Baichuan-Omni (7B) | GPT-4 score: 65.4 |