Command Palette
Search for a command to run...
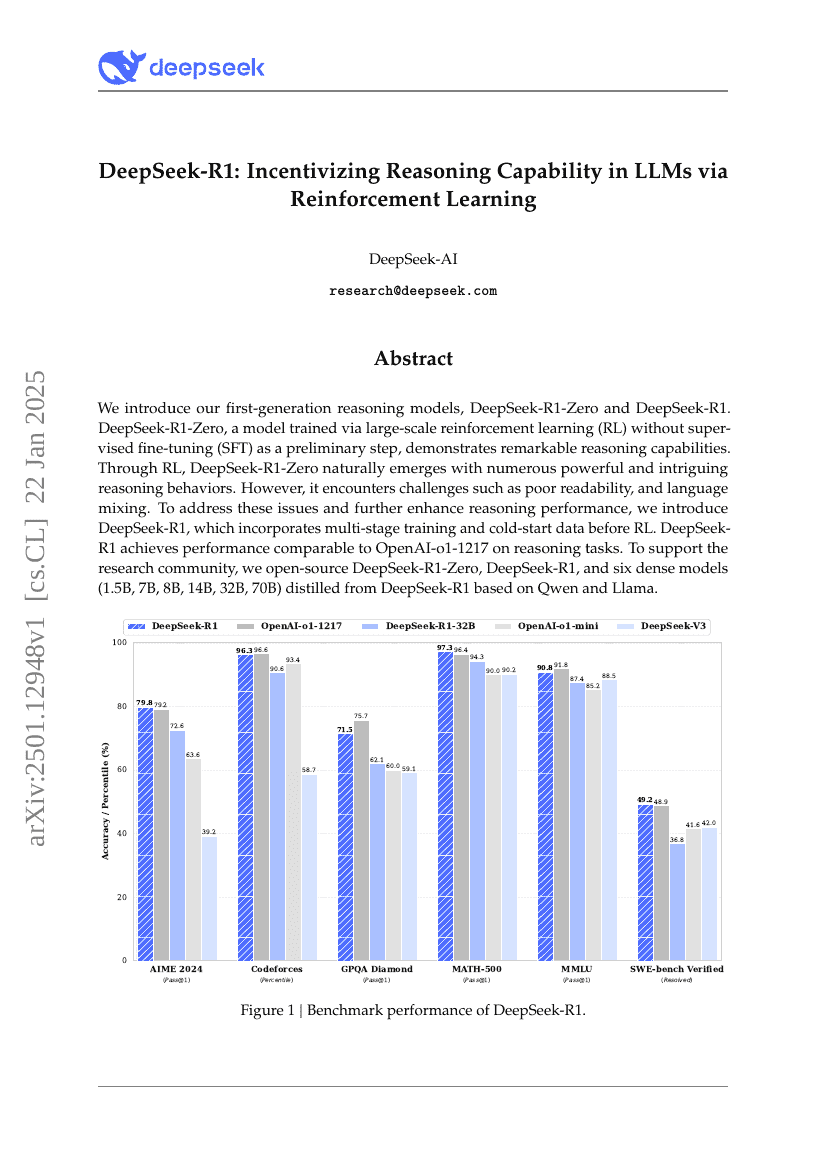
摘要
我们推出了首代推理模型——DeepSeek-R1-Zero 与 DeepSeek-R1。DeepSeek-R1-Zero 是一种通过大规模强化学习(Reinforcement Learning, RL)训练而成的模型,无需经过监督微调(Supervised Fine-Tuning, SFT)作为预处理步骤,便展现出卓越的推理能力。在强化学习的驱动下,DeepSeek-R1-Zero 自然涌现出多种强大而引人注目的推理行为。然而,该模型仍面临可读性较差、语言混用等挑战。为解决上述问题并进一步提升推理性能,我们提出了 DeepSeek-R1,该模型在强化学习前引入了多阶段训练和冷启动数据。在推理任务上,DeepSeek-R1 的表现已可与 OpenAI-o1-1217 相媲美。为支持科研社区的发展,我们开源了 DeepSeek-R1-Zero、DeepSeek-R1 以及基于 Qwen 和 Llama 架构蒸馏出的六款密集型模型(1.5B、7B、8B、14B、32B、70B)。
代码仓库
deepseek-ai/deepseek-r1
官方
GitHub 中提及
turningpoint-ai/visualthinker-r1-zero
pytorch
GitHub 中提及
vlm-rl/ocean-r1
pytorch
GitHub 中提及
zhaoolee/garss
pytorch
GitHub 中提及
基准测试
| 基准 | 方法 | 指标 |
|---|---|---|
| apex-v1.0 | DeepSeek-R1 | Mean score: 57.6% |
| mathematical-reasoning-on-aime24 | DeepSeek-r1 | Acc: 79.8 |
| multi-task-language-understanding-on-mmlu | ds-r1(671b) | Average (%): 87.5 |
| question-answering-on-newsqa | deepseek-r1 | EM: 80.57 F1: 86.13 |