Command Palette
Search for a command to run...
摘要
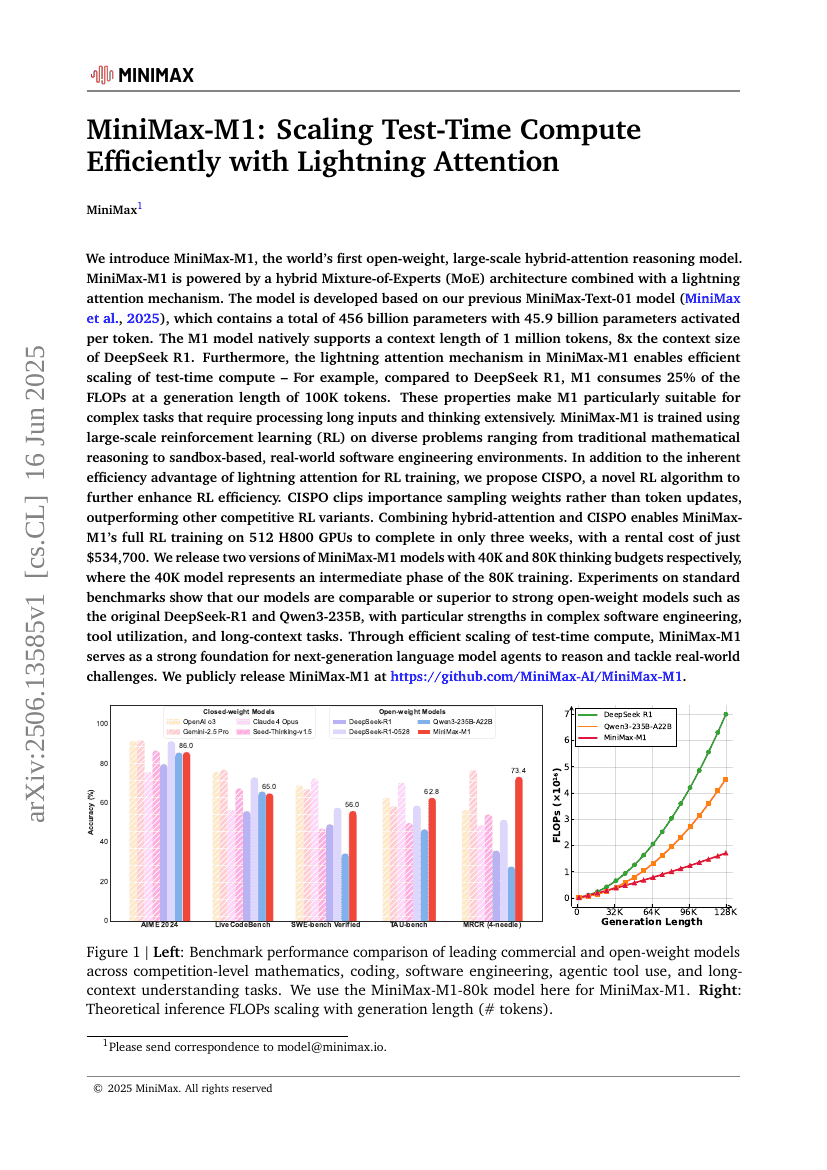
我们介绍了一种名为MiniMax-M1的世界首个开放权重、大规模混合注意力推理模型。MiniMax-M1采用了混合专家(Mixture-of-Experts, MoE)架构与闪电注意力机制相结合的设计。该模型基于我们先前的MiniMax-Text-01模型开发,后者总共包含4560亿个参数,每个标记激活45.9亿个参数。M1模型原生支持长达1百万个标记的上下文长度,是DeepSeek R1上下文长度的8倍。此外,MiniMax-M1中的闪电注意力机制使得测试时计算能够高效扩展。这些特性使得M1特别适用于需要处理长输入和进行深入思考的复杂任务。为了在多样化的任务中训练MiniMax-M1,包括基于沙箱的真实世界软件工程环境,我们使用了大规模强化学习(Reinforcement Learning, RL)。除了M1本身在RL训练中的效率优势外,我们还提出了一种新的RL算法——CISPO,以进一步提高RL效率。CISPO通过裁剪重要性采样权重而不是标记更新来超越其他竞争性的RL变体。结合使用混合注意力和CISPO,使得MiniMax-M1能够在仅534,700美元的租赁成本下,在512个H800 GPU上完成为期三周的完整RL训练。我们发布了两个版本的MiniMax-M1模型,分别具有40K和80K的思考预算,其中40K模型代表了80K训练过程中的一个中间阶段。在标准基准测试中的实验表明,我们的模型在性能上可与强大的开放权重模型如原始DeepSeek-R1和Qwen3-235B相媲美或优于它们,在复杂的软件工程、工具利用和长上下文任务方面表现出色。我们已公开发布MiniMax-M1,地址为https://github.com/MiniMax-AI/MiniMax-M1。