Command Palette
Search for a command to run...
Jianzong Wu Liang Hou Haotian Yang Xin Tao Ye Tian Pengfei Wan Di Zhang Yunhai Tong
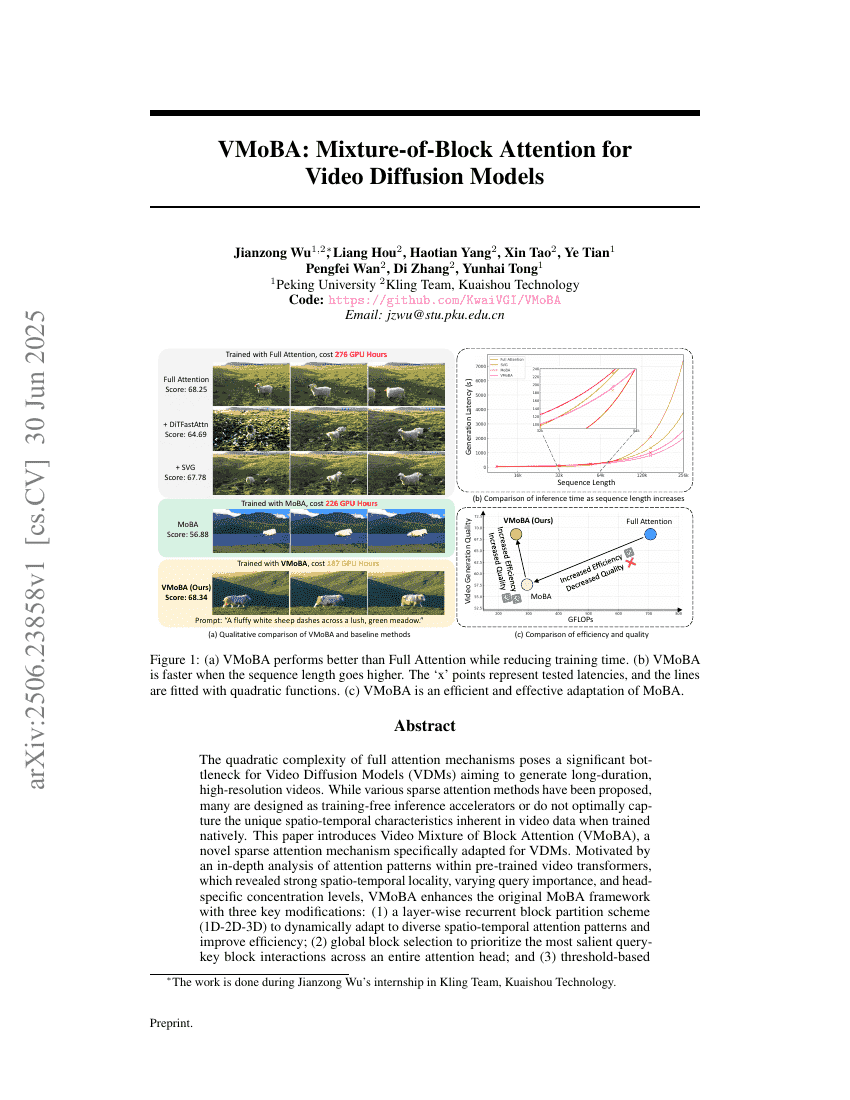
摘要
全注意力机制的二次复杂度对旨在生成长时间、高分辨率视频的视频扩散模型(VDMs)构成了显著的瓶颈。尽管已提出多种稀疏注意力方法,但许多方法要么被设计为无需训练的推理加速器,要么在本地训练时未能最优地捕捉视频数据中固有的独特时空特性。本文介绍了一种新型稀疏注意力机制——视频块注意力混合(Video Mixture of Block Attention, VMoBA),该机制专门针对VDMs进行了适应。通过对预训练视频变换器中注意力模式的深入分析,发现其具有强烈的时空局部性、变化的查询重要性和特定头部的集中水平,VMoBA在原有MoBA框架的基础上进行了三项关键改进:(1) 层级递归块划分方案(1D-2D-3D),以动态适应多样化的时空注意力模式并提高效率;(2) 全局块选择,以优先考虑整个注意力头中最显著的查询-键块交互;(3) 基于阈值的块选择,根据累积相似性动态确定参与注意的块数量。大量实验表明,VMoBA显著加速了VDMs在更长序列上的训练,实现了2.92倍的浮点运算量(FLOPs)和1.48倍的延迟加速,同时生成质量与全注意力机制相当甚至更优。此外,VMoBA在无需训练的推理过程中也表现出竞争力,为高分辨率视频生成提供了2.40倍的浮点运算量和1.35倍的延迟加速。