Command Palette
Search for a command to run...
摘要
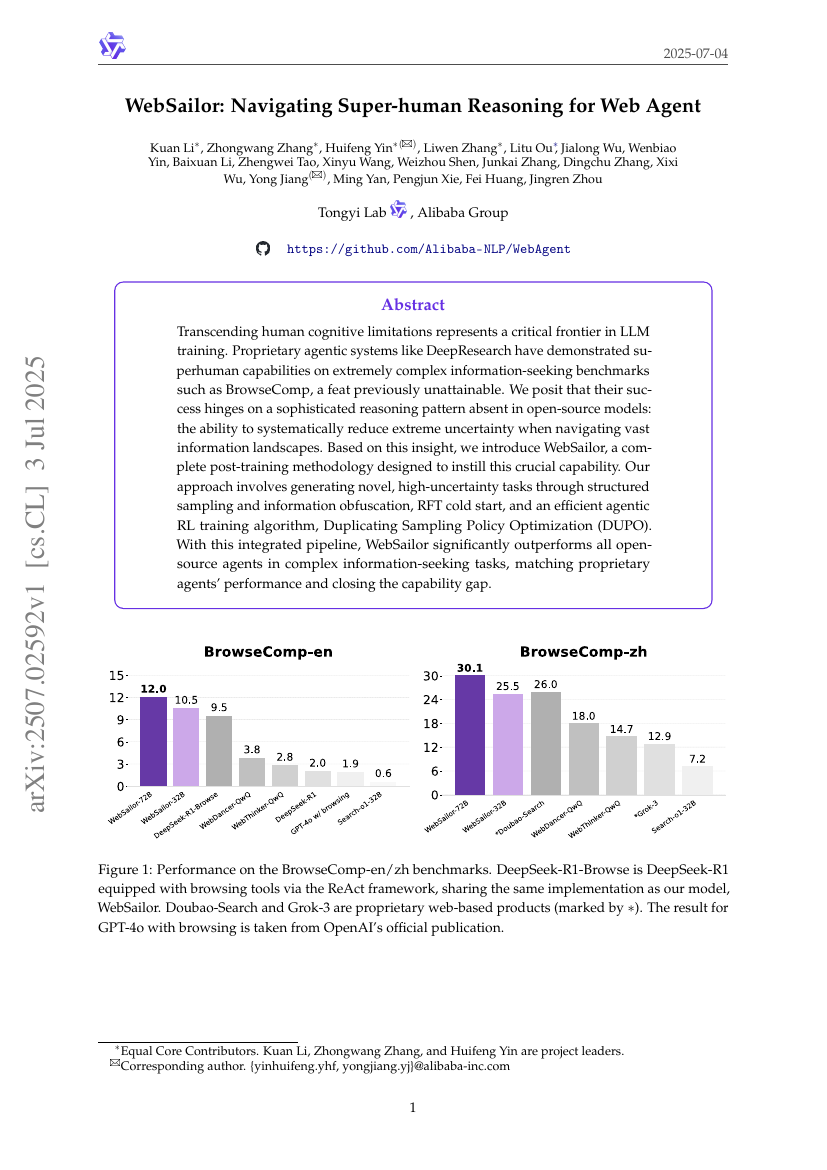
超越人类认知限制是大型语言模型(LLM)训练中的一个关键前沿。像DeepResearch这样的专有代理系统已经在极其复杂的寻息基准测试中展示了超人的能力,例如BrowseComp,这是以前无法实现的壮举。我们认为,它们的成功在于一种在开源模型中缺失的复杂推理模式:即在导航广阔的信息空间时,能够系统地减少极端不确定性。基于这一见解,我们引入了WebSailor,这是一种完整的后训练方法论,旨在培养这种关键能力。我们的方法包括通过结构化采样和信息混淆生成新的高不确定性任务、RFT冷启动以及一种高效的代理强化学习算法——重复采样策略优化(DUPO)。通过这一集成管道,WebSailor在复杂的信息寻息任务中显著优于所有开源代理,其性能与专有代理相当,从而缩小了能力差距。
代码仓库
alibaba-nlp/webwalker
GitHub 中提及
SnailDev/github-hot-hub
pytorch
GitHub 中提及
alibaba-nlp/webagent
官方
GitHub 中提及
kun-g/Scraping-Github-trending
tf
GitHub 中提及