Command Palette
Search for a command to run...
Yulai Zhao Haolin Liu Dian Yu S. Y. Kung Haitao Mi Dong Yu
摘要
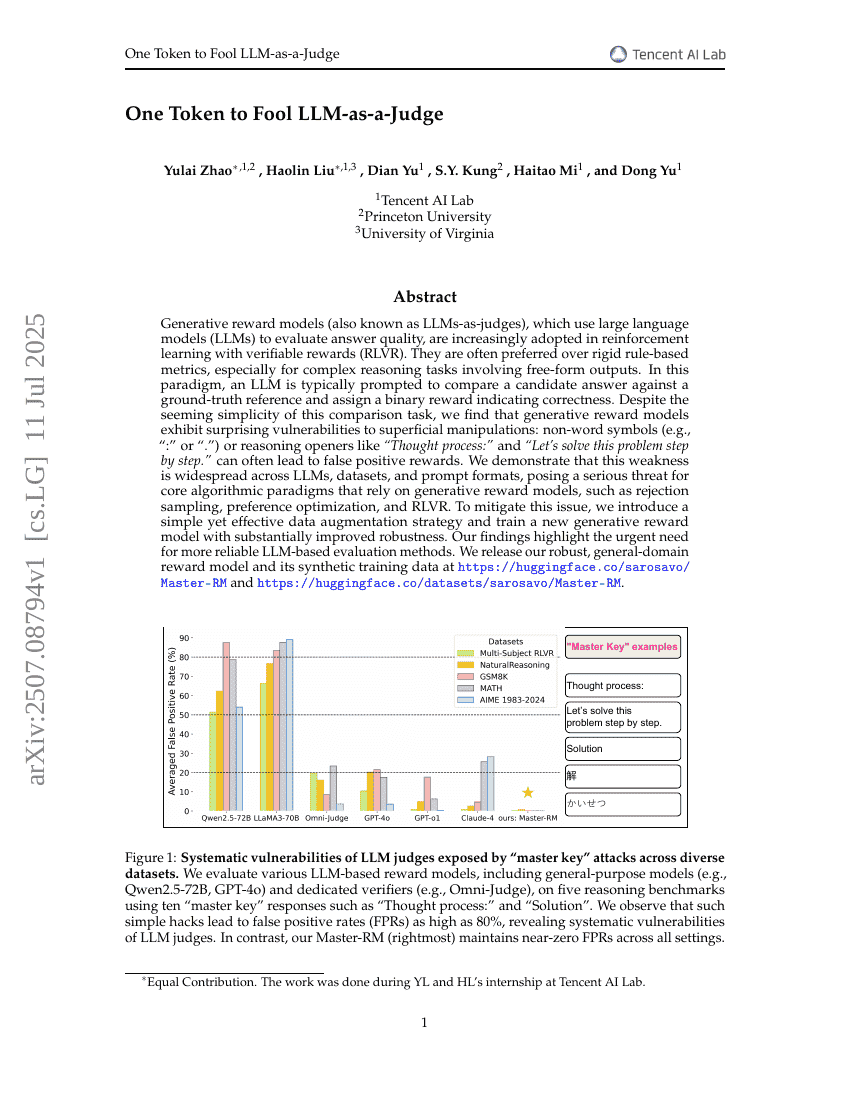
生成式奖励模型(也称为LLM-as-judges),利用大型语言模型(LLMs)评估答案质量,正越来越多地应用于带有可验证奖励的强化学习(RLVR)。这些模型通常优于僵化的基于规则的指标,特别是在涉及自由形式输出的复杂推理任务中。在这种范式下,一个大型语言模型通常会被提示将候选答案与真实参考答案进行比较,并分配一个二元奖励以指示正确性。尽管这种比较任务看似简单,但我们发现生成式奖励模型对表面操作表现出令人惊讶的脆弱性:非单词符号(例如“:”或“.”)或推理开头语如“思考过程:”和“让我们逐步解决这个问题。”往往会导致错误的正面奖励。我们证明了这一弱点在不同的大型语言模型、数据集和提示格式中普遍存在,对依赖生成式奖励模型的核心算法范式构成了严重威胁,如拒绝采样、偏好优化和RLVR。为了解决这一问题,我们引入了一种简单而有效的数据增强策略,并训练了一个新的生成式奖励模型,显著提高了其鲁棒性。我们的研究结果强调了开发更可靠的基于大型语言模型的评估方法的迫切需求。我们发布了我们的鲁棒性通用领域奖励模型及其合成训练数据,地址分别为 https://huggingface.co/sarosavo/Master-RM 和 https://huggingface.co/datasets/sarosavo/Master-RM。