Command Palette
Search for a command to run...
Junhao Shen Haiteng Zhao Yuzhe Gu Songyang Gao Kuikun Liu Haian Huang Jianfei Gao Dahua Lin Wenwei Zhang Kai Chen
摘要
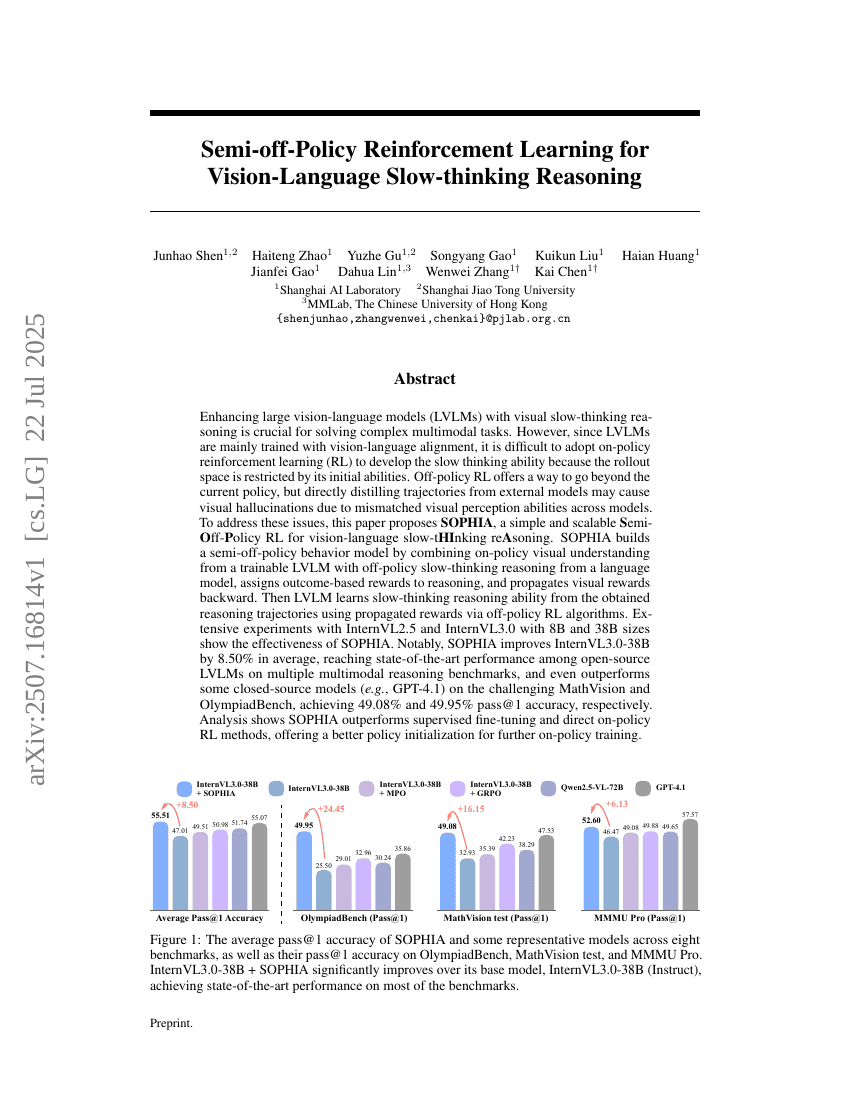
将视觉慢思考推理能力融入大型视觉-语言模型(LVLMs)对于解决复杂的多模态任务至关重要。然而,由于LVLM主要通过视觉-语言对齐进行训练,因此很难采用在线策略强化学习(RL)来培养慢思考能力,因为其策略的执行空间受到初始能力的限制。离线策略RL提供了一种突破当前策略的方法,但直接从外部模型中蒸馏轨迹可能导致视觉幻觉,这是由于不同模型之间的视觉感知能力存在差异。为了解决这些问题,本文提出了SOPHIA,一种简单且可扩展的半离线策略强化学习方法,用于视觉-语言的慢思考推理。SOPHIA通过将可训练LVLM的在线策略视觉理解与语言模型的离线策略慢思考推理相结合,构建了一个半离线策略的行为模型,为推理过程分配基于结果的奖励,并将视觉奖励向后传播。随后,LVLM通过离线策略RL算法,利用传播后的奖励从获得的推理轨迹中学习慢思考推理能力。大量实验表明,使用8B和38B参数规模的InternVL2.5和InternVL3.0模型,SOPHIA具有显著的有效性。值得注意的是,SOPHIA在InternVL3.0-38B模型上的平均性能提升了8.50%,在多个多模态推理基准测试中达到了开源LVLM的最先进水平,甚至在具有挑战性的MathVision和OlympiadBench任务上,分别实现了49.08%和49.95%的pass@1准确率,超过了部分闭源模型(如GPT-4.1)。分析表明,SOPHIA在监督微调和直接在线策略RL方法上表现更优,为后续的在线策略训练提供了更优的策略初始化。