Command Palette
Search for a command to run...
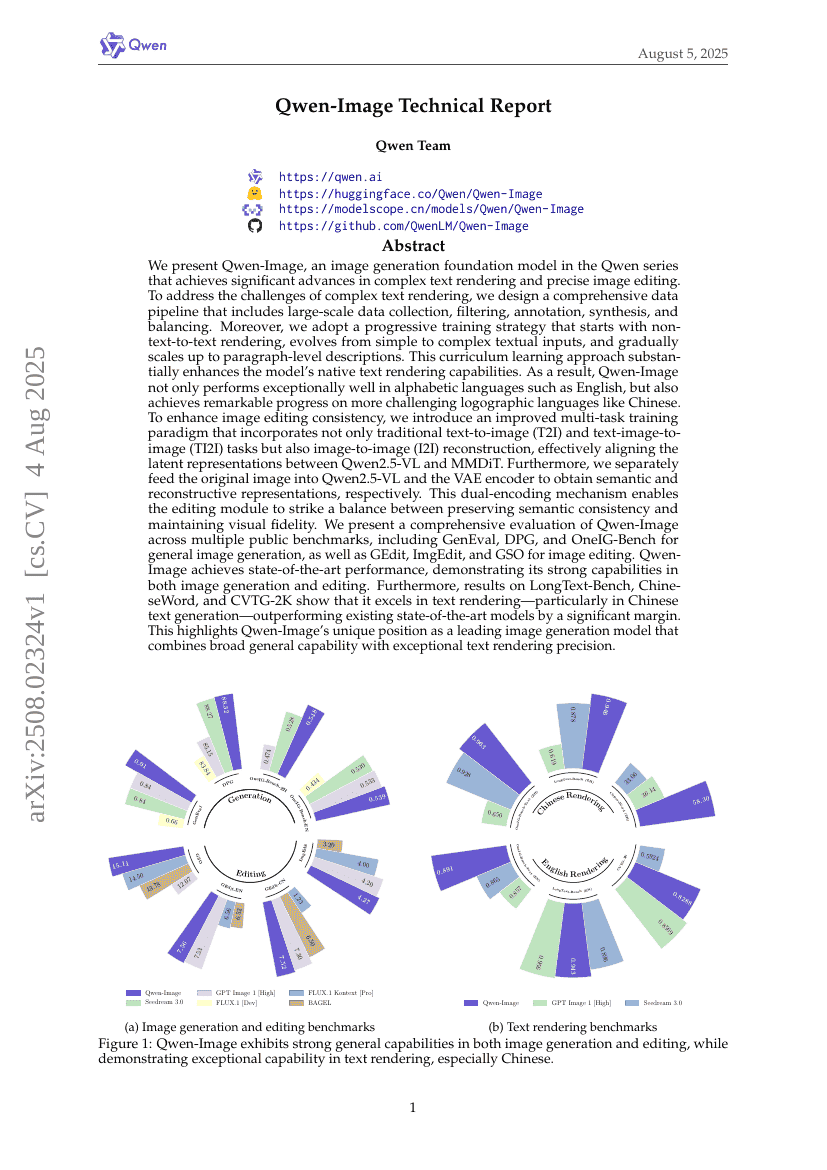
摘要
我们提出 Qwen-Image,这是 Qwen 系列中的一个图像生成基础模型,在复杂文本渲染与精确图像编辑方面取得了显著进展。为应对复杂文本渲染带来的挑战,我们设计了一套完整的数据处理流程,涵盖大规模数据采集、过滤、标注、合成与平衡等环节。此外,我们采用了一种渐进式训练策略:从非文本到文本的渲染任务开始,逐步从简单文本输入过渡到复杂文本输入,最终扩展至段落级描述的生成。这种课程学习方法显著提升了模型在原始文本渲染方面的能力。结果表明,Qwen-Image 不仅在英语等字母语言上表现优异,更在中文等更具挑战性的表意文字语言上取得了突破性进展。为提升图像编辑的一致性,我们引入了一种改进的多任务训练范式,不仅包含传统的文本到图像(T2I)和文本-图像到图像(TI2I)任务,还融合了图像到图像(I2I)重建任务,有效对齐了 Qwen2.5-VL 与 MMDiT 之间的潜在表征。此外,我们将原始图像分别输入 Qwen2.5-VL 和 VAE 编码器,以分别获取语义表征与重建表征。这种双编码机制使编辑模块能够在保持语义一致性与维持视觉保真度之间取得良好平衡。Qwen-Image 在多个基准测试中均达到当前最优性能,充分展现了其在图像生成与编辑任务中的强大能力。