Command Palette
Search for a command to run...
摘要
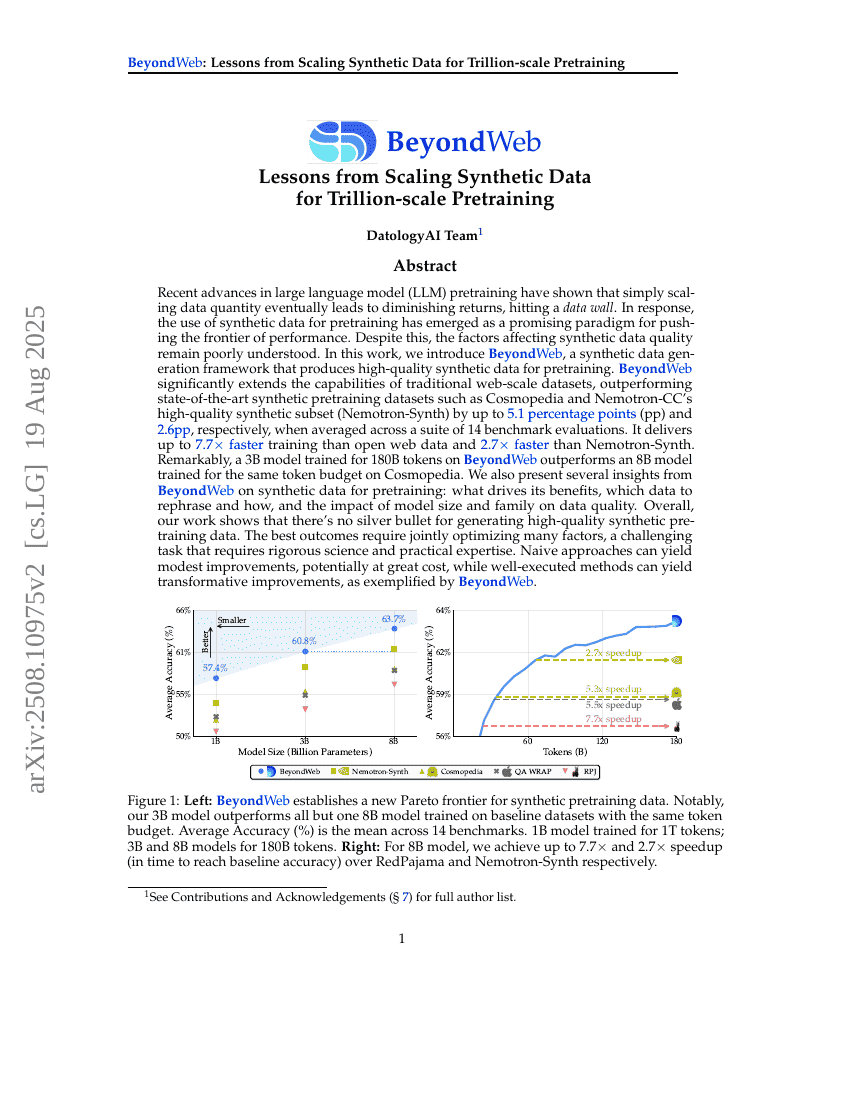
近年来,大规模语言模型(LLM)预训练技术的进展表明,单纯增加数据量最终将导致收益递减,触及“数据瓶颈”。为此,利用合成数据进行预训练逐渐成为突破性能极限的有前景范式。然而,影响合成数据质量的关键因素至今仍缺乏深入理解。在本工作中,我们提出 BeyondWeb——一种合成数据生成框架,能够生成高质量的预训练用合成数据。BeyondWeb 显著扩展了传统网络规模数据集的能力,在涵盖14项基准测试的综合评估中,其性能分别优于当前最先进的合成预训练数据集 Cosmopedia 和 Nemotron-CC 的高质量合成子集(Nemotron-Synth),提升幅度分别高达5.1个百分点(pp)和2.6个百分点。在训练效率方面,BeyondWeb 相较于开源网络数据实现最高达7.7倍的加速,相较 Nemotron-Synth 也提升2.7倍。值得注意的是,仅用1800亿个token在 BeyondWeb 上训练的30亿参数模型,其性能已超过在 Cosmopedia 上训练相同token数量的80亿参数模型。此外,我们基于 BeyondWeb 提供了关于合成数据预训练的若干关键洞见:哪些因素驱动其性能优势、应如何选择并重构哪些数据、以及模型规模与模型家族对数据质量的影响。总体而言,我们的研究表明,生成高质量合成预训练数据并无“万能解法”;最优结果需要协同优化多个因素,这一过程极具挑战性,既需要严谨的科学方法,也依赖丰富的实践经验。盲目采用简单方法可能仅带来有限提升,甚至付出高昂代价;而经过精心设计与实施的方法,则可实现颠覆性突破,BeyondWeb 正是这一理念的有力例证。