Command Palette
Search for a command to run...
摘要
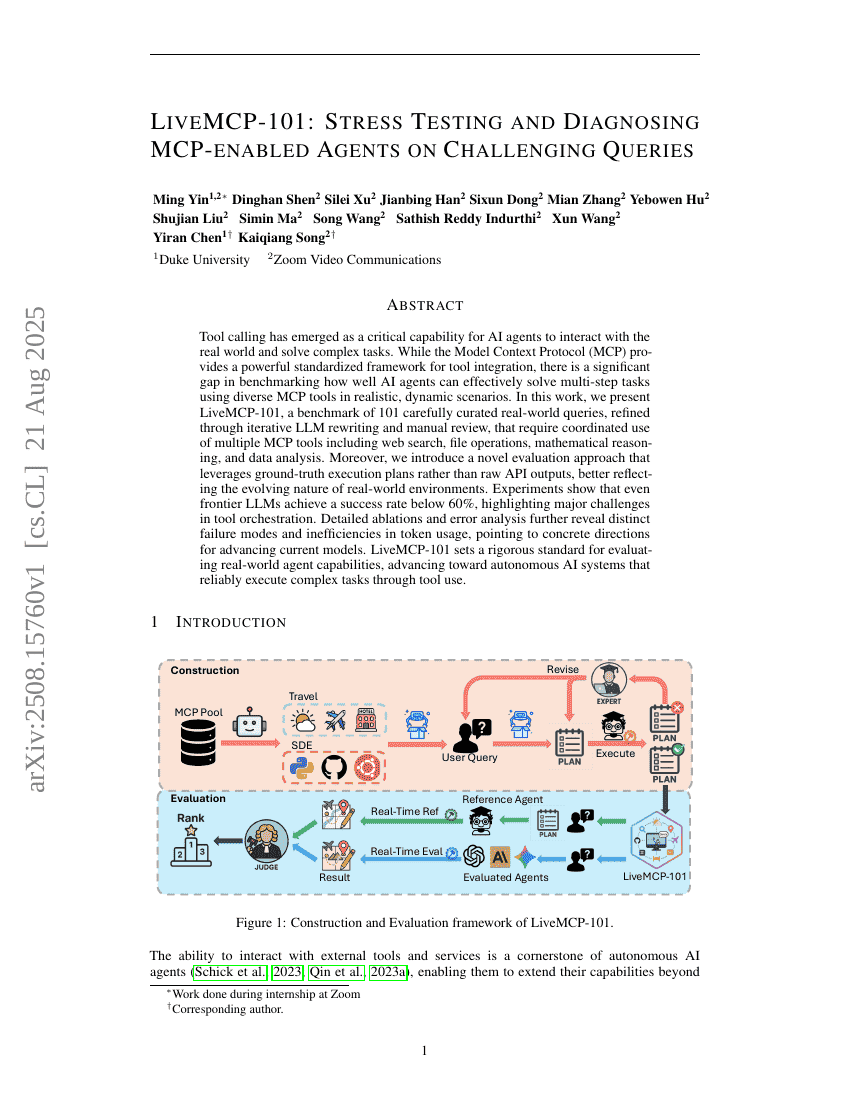
工具调用已成为AI代理与现实世界交互并解决复杂任务的关键能力。尽管模型上下文协议(Model Context Protocol, MCP)提供了一个强大的标准化框架,用于工具集成,但在真实、动态场景中,评估AI代理有效运用多种MCP工具完成多步骤任务的能力方面,仍存在显著的空白。在本研究中,我们提出了LiveMCP-101,一个精心构建的101个真实世界查询组成的基准测试集。这些查询经过多轮大语言模型(LLM)重写与人工审核不断优化,要求协同使用多种MCP工具,包括网络搜索、文件操作、数学推理和数据分析等。此外,我们引入了一种新颖的评估方法,该方法基于真实执行计划(ground-truth execution plans)而非原始API输出进行评估,更准确地反映了现实环境的动态演化特性。实验结果表明,即使是最先进的大语言模型,其任务成功率也低于60%,凸显了工具编排方面存在的重大挑战。详细的消融实验与错误分析进一步揭示了模型在不同失败模式以及令牌(token)使用效率方面的显著缺陷,为当前模型的改进指明了具体方向。LiveMCP-101为评估AI代理在真实场景下的能力设立了严格标准,推动了能够通过工具调用可靠执行复杂任务的自主AI系统的发展。