Command Palette
Search for a command to run...
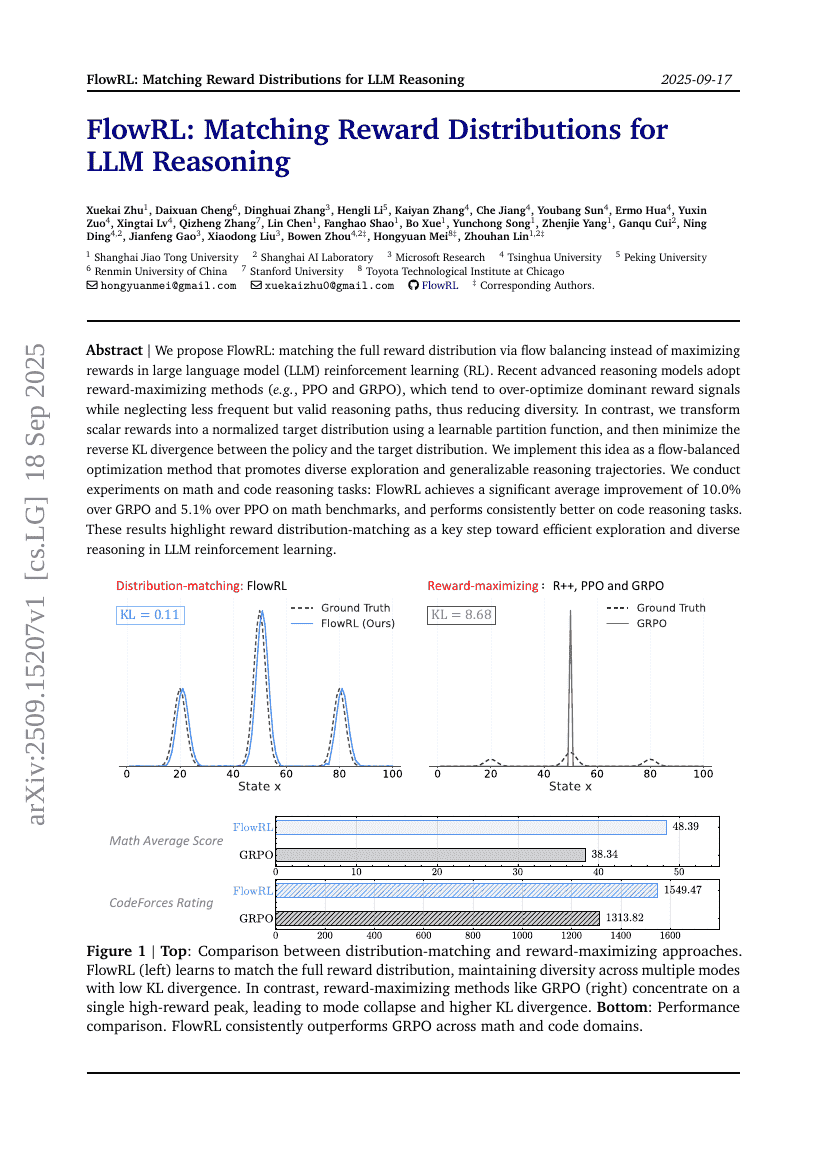
摘要
我们提出 FlowRL:通过流平衡(flow balancing)匹配完整的奖励分布,而非在大型语言模型(LLM)强化学习(RL)中单纯最大化奖励。近期先进的推理模型普遍采用奖励最大化方法(如 PPO 和 GRPO),这类方法往往过度优化主导的奖励信号,而忽视了那些出现频率较低但同样有效的推理路径,从而导致推理多样性下降。相比之下,我们引入一个可学习的分区函数,将标量奖励转化为归一化的目标分布,并最小化策略分布与目标分布之间的反向 KL 散度。我们据此实现了一种流平衡优化方法,能够促进多样化的探索以及更具泛化能力的推理轨迹。我们在数学和代码推理任务上进行了实验:在数学基准测试中,FlowRL 相较于 GRPO 提升了 10.0% 的平均性能,相较于 PPO 提升了 5.1%;在代码推理任务上也表现出持续更优的性能。这些结果表明,奖励分布匹配是实现高效探索与多样化推理的关键一步,对 LLM 强化学习具有重要意义。