Command Palette
Search for a command to run...
Ziheng Ouyang Yiren Song Yaoli Liu Shihao Zhu Qibin Hou Ming-Ming Cheng Mike Zheng Shou

摘要
先前的研究在给定参考图像的前提下,探索了多种定制化图像生成任务,但这些方法在生成一致的细粒度细节方面仍存在局限。本文旨在通过引入一种参考引导的后编辑(post-editing)方法,解决生成图像中的一致性问题,并提出我们的ImageCritic框架。我们首先构建了一个由参考图像-退化图像-目标图像组成的三元组数据集,该数据集通过基于视觉语言模型(VLM)的筛选与显式退化处理获得,能够有效模拟现有生成模型中常见的不准确或不一致现象。此外,基于对模型注意力机制与内在表征的深入分析,我们进一步设计了注意力对齐损失函数与细节编码器,以精准修正生成结果中的不一致性。ImageCritic可集成至智能体(agent)框架中,在复杂场景下实现多轮、局部化的自动检测与修正。大量实验表明,ImageCritic在多种定制化生成场景中均能有效解决细节相关问题,显著优于现有方法。
总结
来自南开大学、新加坡国立大学和浙江大学的研究人员推出了 ImageCritic,这是一个参考引导的后编辑框架,它采用新颖的注意力对齐损失和细节编码器,自动检测并修正复杂定制场景中生成图像的细粒度不一致问题。
简介
图像生成的最新进展已从 UNet 架构转向基于 Transformer 的扩散模型 (DiTs),推动了虚拟试穿、图像编辑和主体定制等参考引导应用的发展。虽然这些系统旨在将特定主体整合到新语境中,但在高保真现实世界部署中,实现生成输出与参考图像之间的精确一致性仍然是一个关键挑战。
当前最先进的模型经常遭受细粒度细节(如文本、Logo 和复杂纹理)不一致或模糊的困扰,这主要是由于基于 VAE 的编码和仅解码器结构固有的信息丢失造成的。超分辨率或多图编辑等标准解决方案往往无法准确地定位这些特定差异或纠正结构错误。此外,该领域缺乏专注于细微局部细节的高质量数据集,因为现有的基准测试优先考虑整体对象的一致性,而不是微小的结构对齐。
为了解决这些问题,作者推出了 ImageCritic,这是一个统一的后编辑修正框架,旨在检测和修复定制生成中的局部不一致。
关键创新
- 参考-退化-目标数据集: 研究人员利用基于 VLM 的筛选和显式退化构建了一个专门的数据集,以模拟现实世界的生成错误,创建了一个专门专注于恢复细粒度细节而不仅仅是通用语义一致性的基准。
- 精确对齐机制: 该模型利用注意力对齐损失来有效地解耦和定位需要修正的区域,并配合细节编码器显式嵌入来自参考图像和输入图像的特征,以提高泛化能力和结构保真度。
- 基于智能体的处理链: 作者设计了一个自动化智能体系统来管理整个工作流程,包括一致性评估、差异定位和图像优化,实现了既可一键自动修复,又可进行多轮人机交互。
数据集
作者构建了一个专门的数据集,旨在解决生成图像中的细粒度一致性和细节错位问题。数据整理流程包括以下步骤:
- 数据收集与生成: 该过程始于大规模收集网络爬取的产品图像。为了扩展多样性,作者使用 Flux Kontext、GPT-4o 和 Nano-Banana 等最先进的文生图模型生成合成变体,创建具有不同对象和光照条件的场景丰富的图像。
- 基于 VLM 的过滤与标注: 采用 Qwen-VL 和 Qwen3-vl 根据视觉清晰度和文本可读性过滤样本。作者还使用 Qwen 分配语义标签进行对象分类并执行图像定位,识别生成场景中特定对象的边界框。
- 分割与验证: 利用预测的边界框,Grounding SAM 提取精确的对象掩码。为确保准确性,Qwen 根据参考产品重新评估这些掩码,验证提取区域在形状、颜色和纹理方面与参考相匹配,同时过滤掉不一致之处。
- 受控退化: 为了模拟现实世界的伪影,作者使用 Flux-Fill 主动破坏 20% 到 70% 的已验证对象区域。这一步骤引入了特定错误,例如扭曲的中英文文本和不匹配的 Logo,而最后的合成步骤将这些退化区域与原始背景融合,以隔离伪影。
- 数据集构成: 最终数据集包含 10,000 个高质量三元组,每个三元组包含一张参考图像、一张退化输入和一张真值目标。这种结构为模型修复文本渲染错误和 Logo 错位提供了逼真的监督信号。
- 迭代增强: 作者采用迭代策略,对模型自身的修复输出进行裁剪并评估一致性。这些修正后的图像作为改进的目标被反馈到数据集中,逐步优化后续训练周期的数据质量。
实验
- 实现采用了 Flux.1-Kontext-dev 作为基础模型并进行 LoRA 微调,利用提出的 ImageCritic 增强数据集生成目标以提高一致性。
- 与开源和闭源模型(如 XVerse、GPT-Image)的定性比较表明,该方法在修正细粒度细节的同时,能够保持原始光照、纹理和背景保真度,表现出优越的能力。
- 在 Dreambench++ 和新推出的 CriticBench(专注于文本和 Logo 等复杂细节)上的定量评估显示,与基线相比,CLIP、DINO 和 DreamSim 分数有显著提高。
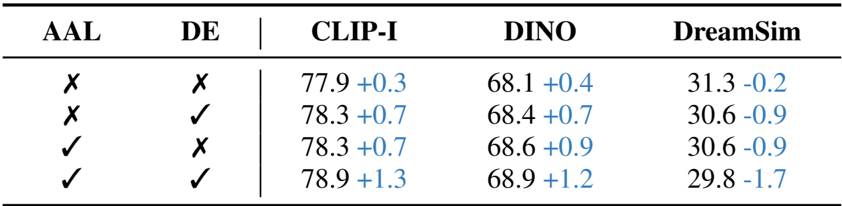
- 消融研究证实了所提出的数据集、注意力对齐损失 (AAL) 和细节编码器 (DE) 在增强注意力解耦和目标区域定位方面的独立有效性和协同有效性。
- 所提出的智能体链表现出强大的定位性能,与人工标注的真值相比,实现了 75.3% 的平均 IoU 和 88.4% 的平均 mAP@50。
- 额外的视觉和基于 OCR 的评估验证了该方法在不同语言、视角和风格化设置下的鲁棒性。
结果表明,所提出的方法在多个基准测试中实现了图像一致性的显著提升,在 CLIP-I 和 DINO 分数上优于 Xverse、DreamO 和 Qwen-Image 等现有模型,同时保持或提高了 DreamSim 值。这种增强在细粒度细节保留方面尤为明显,该方法在保持背景保真度的同时,持续修正纹理、颜色和文本方面的不一致。
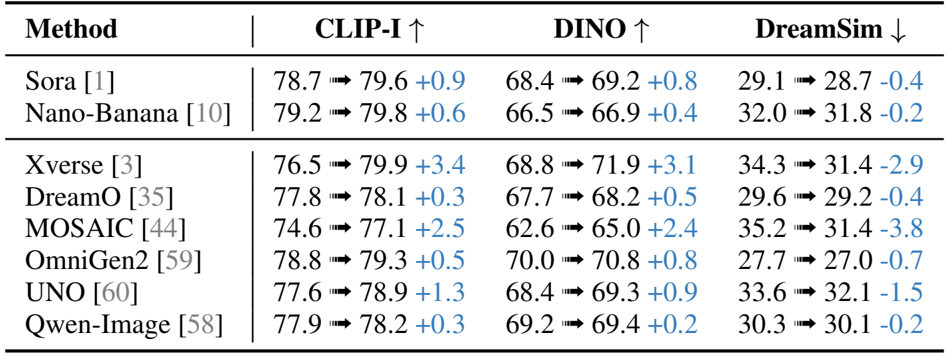
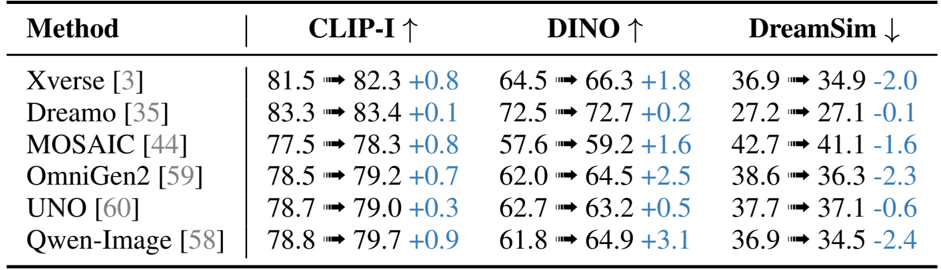
结果表明,所提出的方法在多个评估指标上提高了一致性,与基线模型相比,CLIP-I、DINO 和 DreamSim 分数有显著提升。这些改进表明细节保留和与参考图像的对齐得到了增强,特别是在细粒度视觉元素方面。
结果表明,结合注意力对齐损失 (AAL) 和细节编码器 (DE) 可以在 CLIP-I、DINO 和 DreamSim 的一致性指标上带来最大的提升。消融研究证实,这两个组件都独立地对性能做出了贡献,而它们的组合使用产生了最显著的收益。
作者通过比较自动预测的边界框与人工标注,使用交并比 (IoU) 和 50% IoU 下的平均精度均值 (mAP@50) 来评估其智能体链在定位细粒度细节方面的性能。结果显示平均 IoU 为 75.3%,平均 mAP@50 为 88.4%,表明智能体的预测与真值之间有很强的一致性,证明了其在准确识别和修正特定区域方面的有效性。
