Command Palette
Search for a command to run...
Xiang Hu Zhanchao Zhou Ruiqi Liang Zehuan Li Wei Wu Jianguo Li
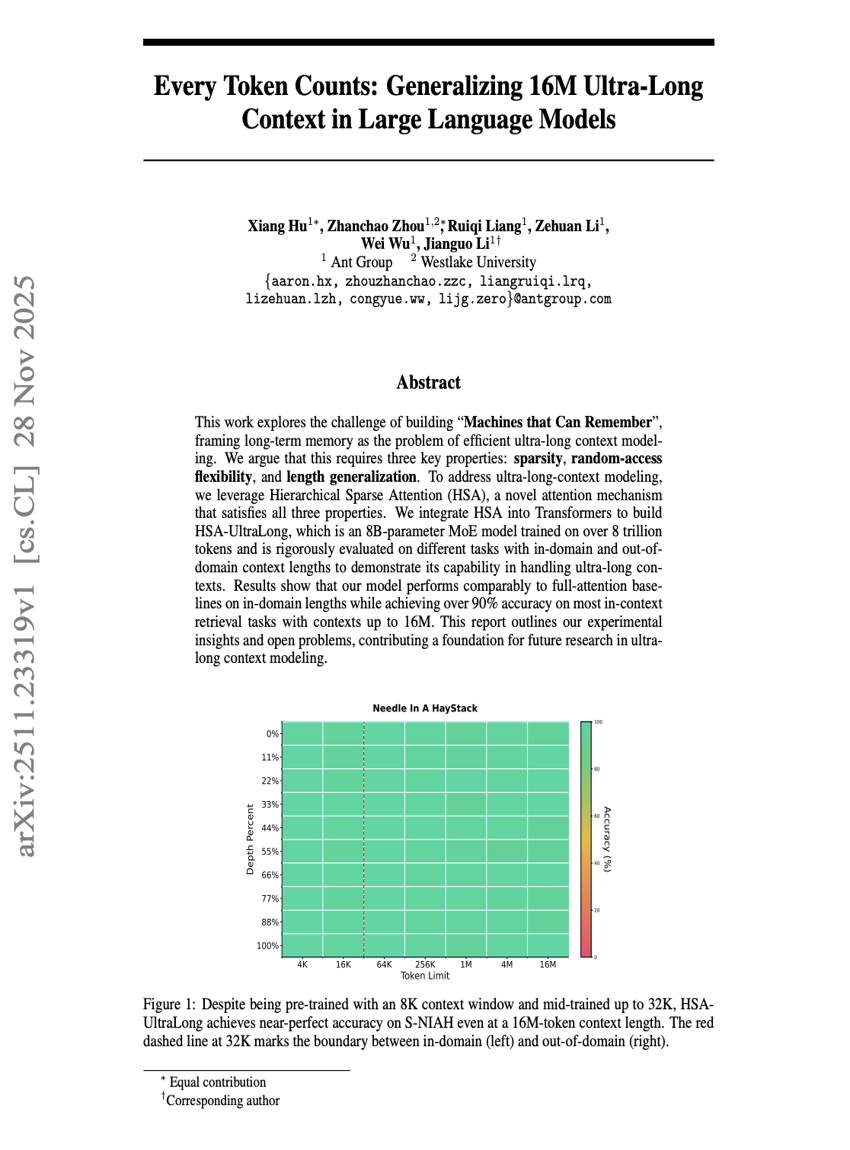
摘要
本研究探讨了构建“能够记忆的机器”这一挑战,将长期记忆问题定义为高效超长上下文建模的问题。我们认为,实现这一目标需要具备三个关键特性:稀疏性、随机访问的灵活性以及长度泛化能力。为应对超长上下文建模的挑战,我们引入了一种新颖的注意力机制——分层稀疏注意力(Hierarchical Sparse Attention, HSA),该机制同时满足上述三项特性。我们将HSA集成到Transformer架构中,构建了HSA-UltraLong模型——一个参数量为80亿的混合专家(MoE)模型,基于超过8万亿个token进行训练,并在多种任务上对域内与域外上下文长度进行了严格评估,以验证其处理超长上下文的能力。实验结果表明,该模型在域内上下文长度下性能可与全注意力基线模型相媲美,而在上下文长度高达1600万的多数上下文检索任务中,准确率仍超过90%。本文总结了我们的实验洞察与开放性问题,为未来超长上下文建模研究奠定了基础。