Command Palette
Search for a command to run...
摘要
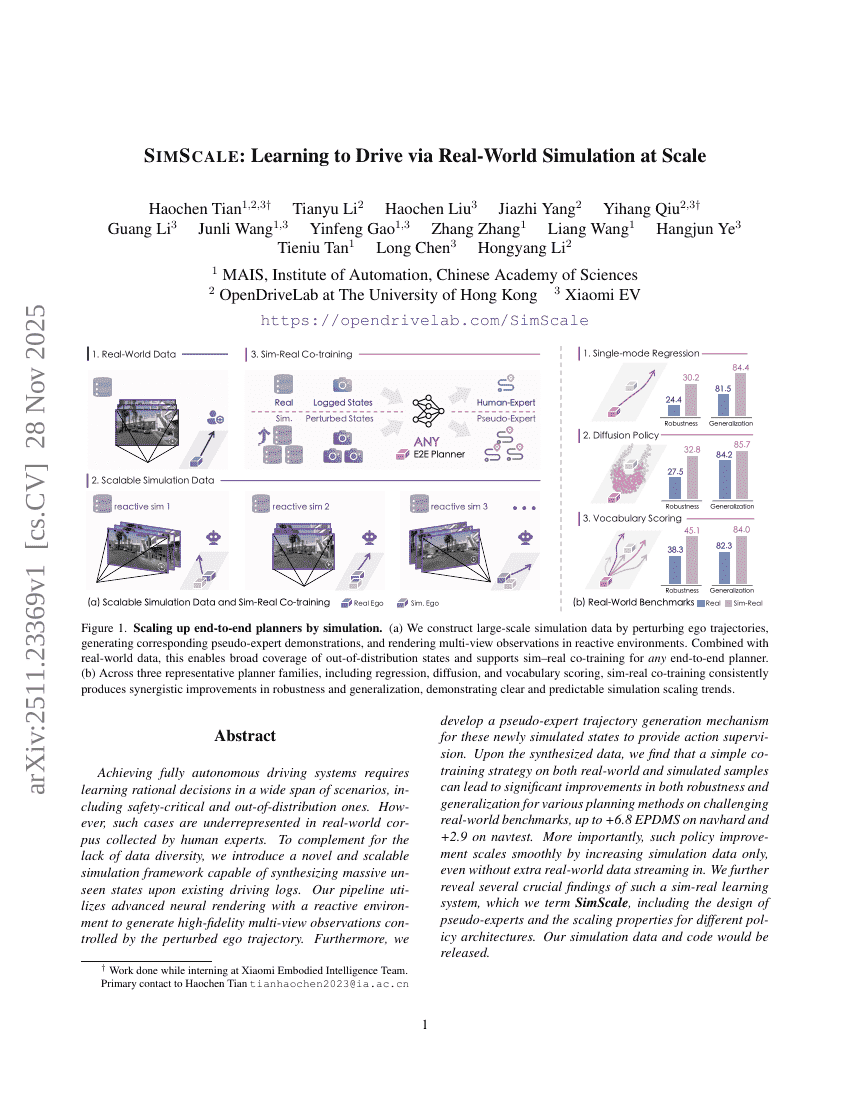
实现完全自动驾驶系统的关键在于学习在广泛场景下做出合理决策的能力,包括那些安全关键性及分布外(out-of-distribution)的极端情况。然而,由人类专家采集的真实世界数据集在这些罕见场景中往往严重缺乏代表性。为弥补数据多样性的不足,我们提出了一种新颖且可扩展的仿真框架,能够基于已有驾驶日志生成大量前所未见的状态。该框架的流水线结合了先进的神经渲染技术与动态响应式环境,可生成由扰动的本车轨迹所控制的高保真多视角观测数据。此外,我们还设计了一种伪专家(pseudo-expert)轨迹生成机制,为这些新生成的仿真状态提供动作监督信号。在合成数据的基础上,我们发现,仅对真实世界数据与仿真数据进行简单的联合训练(co-training),即可显著提升多种规划方法在具有挑战性的真实世界基准测试中的鲁棒性与泛化能力,例如在NavHard基准上提升达+6.8 EPDMS,在NavTest上提升+2.9。更重要的是,这种策略的性能提升可随着仿真数据量的增加而平滑扩展,即使不引入额外的真实世界数据流,也能持续优化模型表现。我们进一步揭示了该“仿真-真实”联合学习系统(我们称之为 SimScale)的若干关键发现,包括伪专家的设计原则,以及不同策略架构下的可扩展性特征。我们将在后续公开所生成的仿真数据集与全部代码。
总结
来自中国科学院、香港大学和小米汽车的研究人员推出了 SimScale,这是一个可扩展的仿真框架,利用神经渲染和伪专家轨迹生成来合成多样化的未见场景,从而通过虚实联合训练显著增强自动驾驶策略的鲁棒性和泛化能力。
介绍
自动驾驶中的端到端规划严重依赖数据规模,以将原始观测直接映射到动作。虽然增加数据集大小通常能提高性能,但现实世界的驾驶日志严重偏向于常规场景,导致安全关键或罕见事件代表性不足。因此,仅在人类演示上训练的模型难以泛化到分布外 (OOD) 状态,在部署时常导致因果混淆。尽管仿真提供了一种生成这些罕见场景的方法,但现有方法往往无法为 OOD 状态产生可行的专家演示,或者存在严重的视觉差异,阻碍了向现实世界的迁移。
为了解决这个问题,作者推出了 SimScale,这是一个可扩展的闭环训练框架,通过高保真仿真增强现有的现实世界数据集。利用 3D 高斯溅射 (3DGS) 引擎,该系统生成了超越人类专家分布的多样化、反应式驾驶场景。作者证明,这种方法允许规划器有效地从合成数据中学习,在不需要额外现实世界数据收集的情况下,提高在具有挑战性的基准测试上的性能。
关键创新包括:
- 伪专家轨迹生成: 系统主动扰动自车轨迹(例如车道漂移),并采用基于恢复的或特权专家来生成可行的纠正动作,教导规划器如何处理偏差。
- 逼真的传感器仿真: 利用 3D 高斯溅射,该框架从自车视角渲染高保真多视图视频,弥合了模拟逻辑与现实世界感知输入之间的视觉差异。
- 可扩展的虚实联合训练: 一种将非重叠仿真数据与固定现实世界语料库逐步整合的训练策略,在各种规划器架构中产生可预测的鲁棒性和泛化性能增益。
数据集
作者结合公开许可的现实世界驾驶数据和旨在解决分布外 (OOD) 挑战的精选仿真场景来构建他们的数据集。
- 数据来源: 训练和评估依赖于已建立的公共数据集,具体为 nuPlan、OpenScene 和 NAVSIM v2。
- 仿真构成: 仿真数据集中在学习策略通常难以应对的四种代表性 OOD 场景:偏离中心车道漂移、近距离碰撞、车道偏离和切入案例。
- 数据结构: 每个仿真样本包含用于感知输入的合成前视图像、代表历史动作的偏离扰动轨迹,以及用作监督的伪专家轨迹。
- 筛选和过滤: 为了确保有效的监督,作者在伪专家轨迹生成过程中丢弃了不可行的候选者。
- 质量指标: 筛选过程强制执行 EPDMS 的所有子指标。为了防止驾驶风格偏差,作者对 EP 分数应用了特定的放宽,要求其大于或等于 0.5。
方法
作者利用伪专家场景仿真流程,从现实世界驾驶场景生成多样化且可行的仿真数据,从而实现端到端规划模型的可扩展虚实联合训练。该框架主要分两个阶段运行:轨迹扰动和伪专家轨迹生成,两者都依赖于逼真的数据引擎进行传感器渲染。
请参考框架图以了解流程概览。该过程始于一个现实世界的训练片段,其中自车在时间步 T 的状态受到扰动,以生成 T+H 处的新终端状态。如图中 (a) 部分所示,此扰动步骤从聚类的人类轨迹词汇表中采样,以确保多样性,同时强制执行物理和运动学约束以保持合理性。扰动在空间上是稀疏的,使用交错网格来促进动作空间的均匀覆盖。这种初始扰动产生了一组动力学和物理上可行的状态,作为下一阶段的起点。
在图中 (b) 部分所示的第二阶段,伪专家策略生成从 T+H 到 T+2H 的扰动状态对应的轨迹。此阶段采用两种不同的策略:基于恢复的专家和基于规划器的专家。基于恢复的专家从大型词汇表中检索与自车扰动状态最匹配的类人轨迹,确保保守和稳定的行为。相比之下,基于规划器的专家使用利用真值状态的特权规划器来生成优化和反应式的轨迹推演,以偶尔偏离类人行为为代价提供更大的多样性和探索性。
仿真流程解耦为行为仿真和传感器渲染。对于每个仿真步骤,自车的轨迹使用线性二次调节器 (LQR) 生成,而其他代理使用智能驾驶员模型 (IDM) 建模以确保逼真的交互。由此产生的未来状态随后使用数据引擎 Φ 渲染成多视图视频,该引擎将相机内参、外参以及所有车辆的位置和方向作为输入。这种解耦允许环境对自车的动作做出合理的反应,增强了生成数据的真实感和多样性。

实验
- 在 NAVSIM
navhard和navtest基准上评估了三种不同的规划器范式(回归、扩散和评分),验证了虚实联合训练与模型无关的有效性。 - 在
navhard排行榜上,GTRS-Dense (V2-99) 模型取得了 47.2 的最先进 EPDMS 分数,而 LTF 和 DiffusionDrive 等基线模型的性能提升超过 20%。 - 数据扩展分析表明,探索性的基于规划器的伪专家优于保守的基于恢复的专家,特别是随着仿真数据量的增加。
- 架构比较显示,基于扩散的规划器随仿真数据表现出线性性能扩展,而基于回归的模型由于处理多模态的能力有限而趋于饱和。
- 消融研究证实,与非反应式仿真相比,反应式交通仿真显著增强了训练有效性,即使生成的样本较少也能提供更好的结果。
- 多专家集成实验表明,结合多样化的伪专家行为会产生互补效益,在 ResNet34 主干上将 EPDMS 提高了 3.4 分。
- 可扩展性测试表明,仿真数据在不同数量的现实世界训练数据下均能持续提高性能,从 10K 到 100K 现实场景均保持有效性。
作者使用带有伪专家监督的仿真数据来增强三种规划器范式的端到端驾驶模型的性能。结果表明,结合仿真数据显著提高了 EPDMS 分数,基于评分的 GTRS-Dense 模型在 NAVSIM-v2 navhard 排行榜上取得了 47.2 的新 SOTA,证明了虚实联合训练的有效性。

作者使用仿真数据来增强三种规划器范式的端到端驾驶模型的性能。结果表明,结合带有伪专家监督的仿真数据显著提高了模型在 NAVSIM-v2 navhard 和 navtest 基准上的性能,其中基于评分的 GTRS-Dense 模型在 navtest 上取得了 84.6 的最高 EPDMS 分数。

作者使用从两种类型的伪专家(基于恢复的和基于规划器的)生成的仿真数据来评估对模型性能的影响。结果表明,结合基于规划器的专家的仿真数据在两种主干架构上均持续提高性能,其中 V2-99 模型在同时使用真实和仿真数据训练时取得了 47.2 的最高 EPDMS 分数。

作者比较了反应式与非反应式交通仿真对模型性能的影响,使用 EPDMS 作为主要指标。结果表明,尽管生成的仿真样本较少,但具有三轮采样的反应式仿真取得了比非反应式仿真(43.7 和 45.6)更高的 EPDMS 分数(ResNet34 和 V2-99 分别为 44.8 和 46.6)。这表明反应式代理动力学增强了交通交互的真实感和多样性,从而产生更有效的仿真数据。
