Command Palette
Search for a command to run...

摘要
强化学习(Reinforcement Learning, RL)近年来在激发多模态大语言模型(Multimodal Large Language Models, MLLMs)的视觉推理能力方面取得了显著进展。然而,现有方法通常为不同任务训练独立的模型,并将图像与视频推理视为相互分离的领域,导致难以扩展为具备通用性的多模态推理模型,限制了实际应用的灵活性,并阻碍了任务间与模态间的知识共享。为此,我们提出 OneThinker——一个统一的全栈式推理模型,能够整合多种基础视觉任务中的图像与视频理解能力,涵盖问答、图像描述生成、空间与时间定位、目标跟踪以及图像分割等任务。为实现这一目标,我们构建了包含上述所有任务的 OneThinker-600k 训练语料库,并利用商用模型进行思维链(Chain-of-Thought, CoT)标注,从而获得用于监督微调(Supervised Fine-Tuning, SFT)的 OneThinker-SFT-340k 模型,实现SFT阶段的冷启动。此外,我们提出 EMA-GRPO 方法,通过追踪各任务奖励标准差的任务级移动平均值,有效应对多任务强化学习中的奖励异质性问题,实现更均衡的优化过程。在多个多样化视觉基准上的大量实验表明,OneThinker 在 31 个基准测试中均展现出强劲性能,覆盖 10 项基础视觉理解任务。更重要的是,模型在部分任务间表现出有效的知识迁移能力,并具备初步的零样本泛化能力,标志着向统一的多模态推理通用模型迈出了关键一步。所有代码、模型及数据均已开源。
总结
来自香港中文大学 MMLab 和美团的研究人员推出了 OneThinker,这是一个一体化的多模态推理模型,通过采用一种新颖的 EMA-GRPO 策略来处理多任务强化学习中的奖励异质性,从而统一了跨越十项基本任务的图像和视频理解,实现了比互不相连的特定领域模型更优越的可扩展性和知识迁移。
引言
推理能力正成为推动多模态大型语言模型 (MLLMs) 迈向通用智能的关键,近期的方法成功应用强化学习 (RL) 增强了逐步推理能力。虽然 Vision-R1 和 Video-R1 等模型在特定领域取得了成功,但目前的研究仍然是碎片化的,通常将图像处理与视频理解隔离开来,并将模型限制在单一任务中。
这种分离限制了 AI 智能体的实际通用性,因为现实场景需要对静态和动态视觉输入进行统一推理。此外,现有的优化算法难以同时处理异构任务中存在的多样化奖励特征。为了解决这个问题,作者提出了 OneThinker,这是一个统一的多模态通才,能够在一个框架内执行广泛的视觉推理任务,从问答和描述生成到空间跟踪和分割。
关键创新包括:
- 统一数据策略: 构建了 OneThinker-600k 数据集和一个高质量的思维链 (Chain-of-Thought) 标注子集,允许模型联合学习图像和视频模态中的空间和时间线索。
- EMA-GRPO 算法: 一种新颖的强化学习方法,采用任务级指数移动平均进行奖励归一化。这解决了稀疏奖励任务(如数学)与密集奖励任务(如检测)之间的优化不平衡问题。
- 跨任务泛化: 通过同时在多种基本任务上进行训练,该模型促进了知识共享,在 31 个基准测试中取得了优异的性能,并在未见过的场景中展现了零样本泛化能力。
数据集
数据集概览:OneThinker-600k 和 OneThinker-SFT-340k
作者构建了一个专门的语料库,旨在开发一个统一的多模态推理通才。数据集构建过程涉及以下关键组件和策略:
- 组成与来源: 训练数据的基础是 OneThinker-600k 语料库。该数据集汇集了来自广泛公共训练数据集的样本,经过精心策划以确保跨领域和难度级别的多样性。它涵盖了图像和视频模态,以支持静态和动态视觉上下文。
- 任务覆盖: 数据涵盖了一系列基本的视觉推理任务,包括基于规则和开放式的 QA、描述生成、跟踪、分割以及各种形式的定位(空间、时间及涉及时空的)。
- 格式化与处理: 对于定位和分割等感知导向的任务,作者要求模型以预定义的 JSON 模式输出响应。这种标准化确保了格式的一致性,并实现了自动、可验证的奖励计算。
- 思维链 (CoT) 标注: 为了实现有效的监督微调 (SFT) 初始化,作者使用专有的 Seed1.5-VL 模型在 OneThinker-600k 语料库上生成 CoT 标注。
- 过滤与最终子集: 生成的标注经过了特定任务的过滤阈值、基于规则的检查和质量验证,以确保准确性。这一过程产生了 OneThinker-SFT-340k 子集,作为训练模型推理能力的高质量、CoT 标注基础。
方法
作者对所有任务利用统一的文本接口,其中模型在 <think> 标签内生成内部推理轨迹,并在 <answer> 标签内生成特定于任务的输出。该框架实现了跨不同模态和任务的一致处理,感知导向任务的结构化输出允许自动解析和验证。总奖励由准确性部分 Racc 和格式奖励 Rformat 组成,后者确保结构化输出符合预定义的模式。
对于多项选择、数值、回归、数学和 OCR 等基于规则的任务,正确性由直接等价或标准指标确定。多项选择、数值和数学问题基于答案等价性进行评估,而回归任务使用平均相对准确率 (MRA) 来评估跨容差水平的相对接近度。OCR 任务采用词错误率进行评估。这些确定性奖励提供了适合强化学习的可解释反馈。
开放式问答和描述生成任务利用外部奖励模型来计算预测答案与参考答案之间的相似度得分。作者采用 POLAR-7B 作为奖励模型,评估生成响应的语义质量。时间定位任务要求模型预测连续的时间段,准确性通过预测区间与真实区间之间的时间交并比 (tIoU) 来衡量。空间定位涉及预测边界框,准确性使用空间 IoU (sIoU) 评估。时空定位的组合任务将准确性计算为 tIoU 与各帧平均 sIoU 的总和。跟踪任务将准确性衡量为预测边界框轨迹上的平均 IoU。
对于分割,模型预测一个边界框以及一组正负点来指导对象识别。这些预测由 SAM2 处理以生成最终的分割掩码。在视频分割中,还会预测关键帧时间以确定何时应用标注。准确性奖励结合了边界框重叠度与基于高斯核的点集相似度,其中距离使用具有特定任务参数的高斯函数进行归一化。在视频分割中,时间高斯核被应用于关键帧预测。
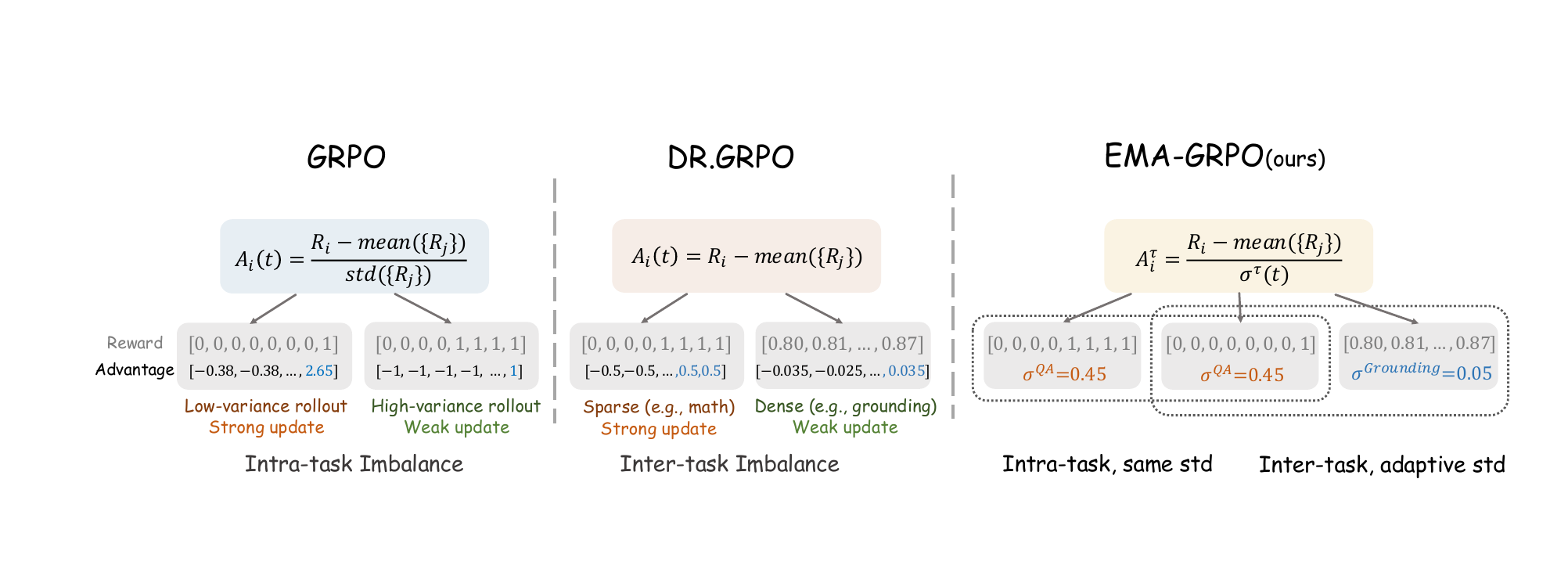
强化学习框架解决了多任务训练中的两个关键不平衡问题。标准 GRPO 通过组标准差对每个提示组内的奖励进行归一化,这通过过分强调具有极端方差的样本并对中等难度的样本优化不足而引入了任务内不平衡。像 Dr.GRPO 那样移除这种归一化虽然消除了任务内偏差,但产生了任务间不平衡,即稀疏奖励主导优化,而密集奖励被降低权重。为了解决这两个问题,作者提出了 EMA-GRPO,它使用指数移动平均来维护奖励分布的一阶矩和二阶矩的任务级估计。这些估计用于计算特定于任务的标准差,从而对每个任务的优势进行归一化。这种自适应归一化确保了在具有不同奖励尺度和密度的任务之间进行公平学习,同时保持每个任务内的平衡优化。
训练目标遵循标准 GRPO 公式,结合了 EMA 归一化的优势。策略更新最大化一个截断目标函数,该函数平衡新旧策略概率的比率与优势,同时包含一个 KL 散度项以防止过大的策略更新。这种方法促进了跨多样化视觉推理任务的稳定和有效优化。



实验
- 综合评估: 通过 SFT 和带有 EMA-GRPO 的 RL 训练的 OneThinker-8B 模型,在包括 QA、描述生成、定位、跟踪和分割在内的多种视觉推理任务中进行了评估。
- QA 优势: 在图像 QA 中,该模型在 MMMU 上达到 70.6%,在 MathVista 上达到 77.6%,超过了 Vision-R1-7B;在视频 QA 中,它在 LongVideo-Reason 上达到 79.2%,显著优于 Video-R1-7B (67.2%)。
- 定位与跟踪: 该模型展示了卓越的定位能力,在 ActivityNet(时间)上达到 65.0 [email protected],在 RefCOCO testA(空间)上达到 93.7,同时在 GOT-10k 跟踪基准上实现了 73.0 AO。
- 分割结果: OneThinker 在分割任务中获得了最佳性能,在 RefCOCO val 上记录了 75.8 cIoU,在 MeViS 上记录了 52.7 J&F,优于 PixelLM-7B 和 Seg-R1-7B 等基线。
- 消融与分析: 实验验证了 EMA-GRPO 算法优于标准 GRPO 和仅 SFT 的基线,而数据排除测试证实了在不同任务上的联合训练促进了跨模态知识迁移(例如,图像 QA 改善视频 QA)。
- 泛化: 该模型在未见过的 MMT-Bench 任务(如点跟踪和 GUI 导航)上表现出强大的零样本能力,超过了 Qwen3-VL-Instruct-8B 基础模型。
作者使用统一的训练框架在多个视觉推理任务(包括图像和视频问答、描述生成、定位、跟踪和分割)上评估 OneThinker-8B。结果表明,OneThinker-8B 在大多数基准测试中达到了最先进的性能,优于 Qwen3-VL-Instruct-8B 和专门的视频推理模型等先前模型,展示了跨任务和模态的强大泛化和迁移能力。

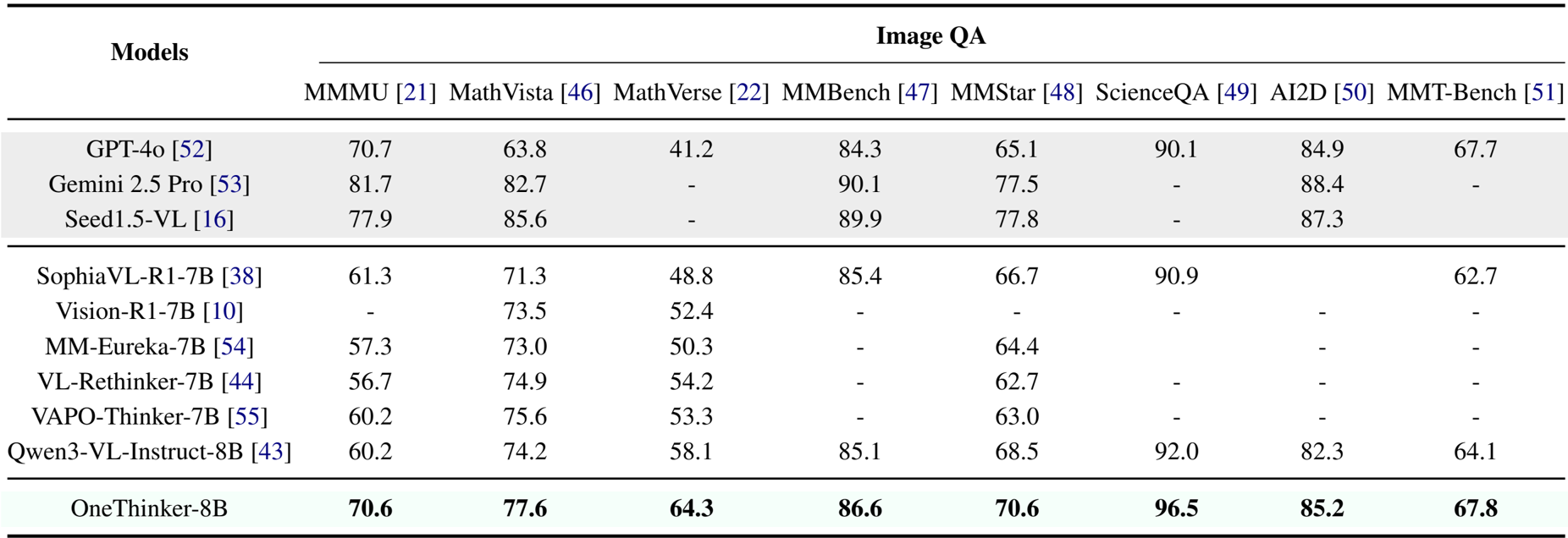
作者使用 OneThinker-8B 模型评估在多个基准上的图像问答性能。结果表明,OneThinker-8B 取得了顶尖结果,在所有测试任务(包括 MMMU、MathVista、MathVerse 和 ScienceQA)上均优于 Qwen3-VL-Instruct-8B 和 Vision-R1-7B 等先前的开源模型。
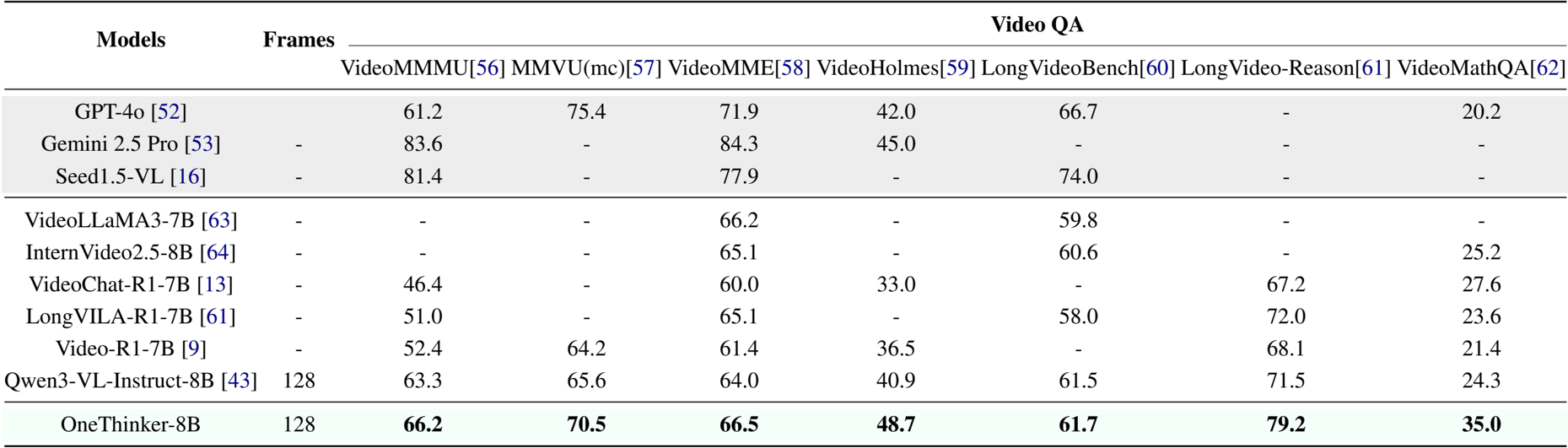
作者使用 OneThinker-8B 评估在多个基准上的视频问答性能。结果表明,OneThinker-8B 在 VideoMMMU、MMVU(mc)、VideoMME 和 LongVideo-Reason 上取得了最高分,优于 GPT-4o、Gemini 2.5 Pro 和 Qwen3-VL-Instruct-8B 等模型。它还在 VideoMathQA 上以 35.0 的得分领先,展示了在复杂视频理解任务中的强大推理能力。
作者使用该表比较了 OneThinker-8B 与其他模型在图像和视频描述生成任务上的性能。结果表明,OneThinker-8B 在 MMT-Caption 和 VideoMMLU-Caption 上均取得了最高分,优于 Qwen3-VL-Instruct-8B 和 LLaVA-1.5-7B,而 GPT-4o 在 MMSsci-Caption 和 VideoMMLU-Caption 上领先。

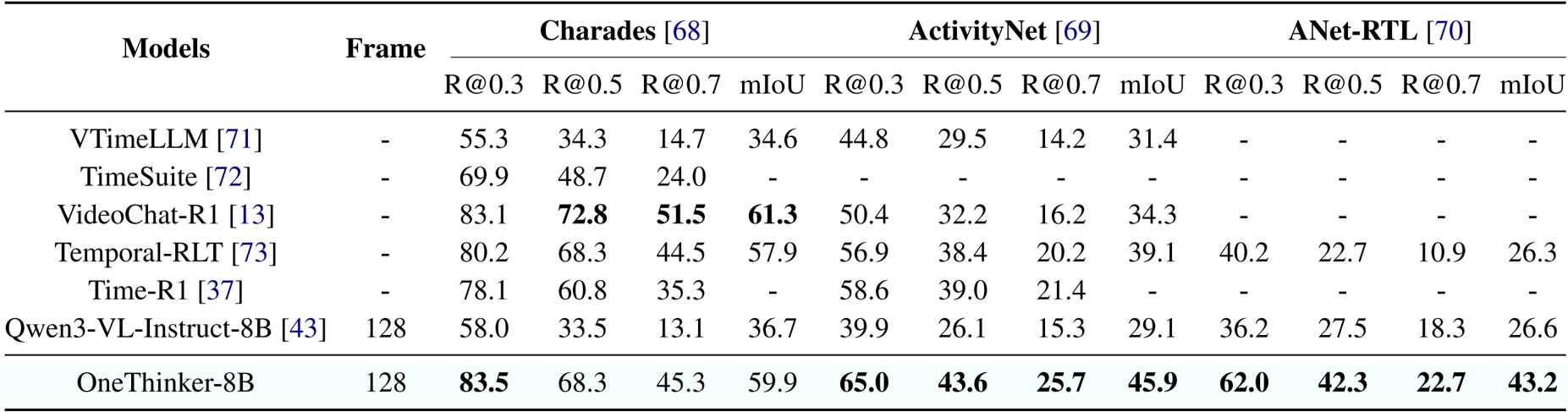
作者使用该表在 Charades、ActivityNet 和 ANet-RTL 基准上比较了 OneThinker-8B 与几种现有模型在时间定位任务上的表现。结果表明,OneThinker-8B 在 Charades 上取得了最高性能,达到 83.5 [email protected] 和 68.3 [email protected],并在 ActivityNet 上以 65.0 [email protected] 和 43.6 [email protected] 领先,同时在 ANet-RTL 上也获得了 43.2 的最佳 mIoU。