Command Palette
Search for a command to run...
Xingrun Xing Zhiyuan Fan Jie Lou Guoqi Li Jiajun Zhang Debing Zhang
摘要
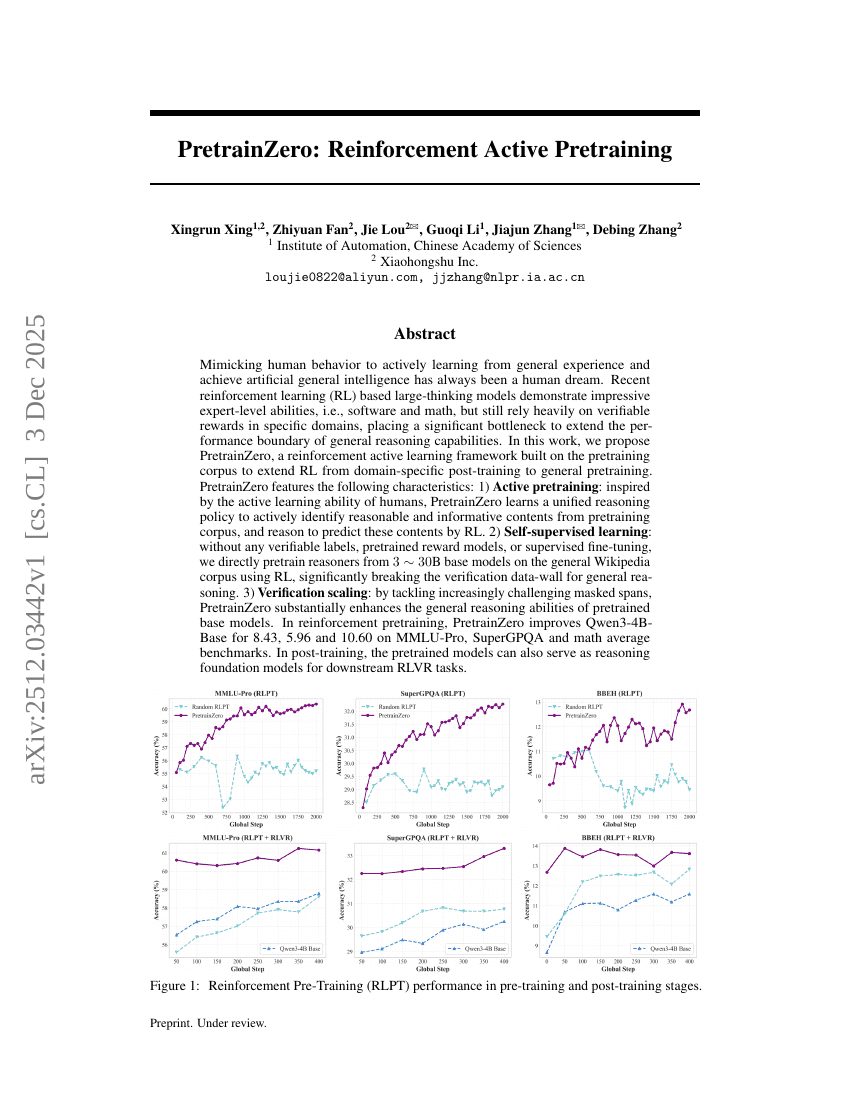
模仿人类行为,从通用经验中主动学习并实现人工通用智能(AGI),始终是人类的梦想。近年来,基于强化学习(Reinforcement Learning, RL)的大规模思维模型展现出令人瞩目的专家级能力,例如在软件开发与数学推理等领域表现卓越,但其性能仍严重依赖于特定领域内可验证的奖励信号,这成为制约通用推理能力边界拓展的重大瓶颈。在本研究中,我们提出 PretrainZero——一种基于预训练语料库构建的强化主动学习框架,旨在将强化学习从领域特定的后训练阶段扩展至通用的预训练阶段。PretrainZero 具备以下核心特性:1)主动预训练:受人类主动学习能力的启发,PretrainZero 能够学习一个统一的推理策略,主动从预训练语料中识别出合理且信息丰富的文本内容,并通过强化学习进行推理,以预测这些内容。2)自监督学习:无需任何可验证的标签、预训练的奖励模型或监督微调,我们直接在通用维基百科语料上,利用强化学习对 30 亿至 300 亿参数规模的基础模型进行预训练,显著突破了通用推理任务中长期存在的“验证数据墙”限制。3)验证能力的可扩展性:通过逐步应对日益复杂的掩码片段(masked spans)挑战,PretrainZero 显著提升了预训练基础模型的通用推理能力。在强化预训练阶段,PretrainZero 使 Qwen3-4B-Base 模型在 MMLU-Pro、SuperGPQA 以及数学平均基准上分别提升 8.43、5.96 和 10.60 分。在后训练阶段,这些预训练模型亦可作为下游强化学习验证与推理(RLVR)任务的通用推理基础模型,展现出强大的泛化潜力。本工作为实现无需人工标注、可自主学习的通用推理系统提供了新路径,推动了人工通用智能向更广泛、更自主的方向发展。