Command Palette
Search for a command to run...
Beyond Visual Reality: Tsinghua WorldArena's New Evaluation System Reveals the Capability Gap in Embodied World Models

When generative AI can create incredibly realistic videos, are we not far from true embodied intelligence? The answer may not be so optimistic.
Over the past few years, video generation models have made astonishing progress. From lighting and shadow details to complex dynamic scenes, many models can now generate images that are almost indistinguishable from reality to the naked eye. However, when these models are actually put into robotic systems and used for decision-making and execution in the physical world, an embarrassing reality emerges: visual realism has not translated into functional reliability.
Current evaluation systems for embodied world models largely rely on a single-dimensional comparison of "visual realism"—whoever produces the clearest and smoothest video is considered the better model. However, a fundamental question is overlooked: can these models, capable of generating beautiful videos, truly support stable decision-making and action in the real physical world?
This is precisely the core question that the new evaluation system WorldArena is trying to answer and solve.WorldArena, proposed by institutions including Tsinghua University, Peking University, the University of Hong Kong, Princeton University, the Chinese Academy of Sciences, Shanghai Jiao Tong University, the University of Science and Technology of China, and the National University of Singapore,Instead of limiting the evaluation to visual appearance, it has for the first time integrated the quality of video generation with the functionality of embodied tasks, and built a complete evaluation framework from "looks real" to "is actually usable".

Paper title: WorldArena: A Unified Benchmark for Evaluating Perception and Functional Utility of Embodied World Models
Paper address:
http://arxiv.org/abs/2602.08971
Project homepage:
http://world-arena.ai
Evaluation Ranking:
https://huggingface.co/spaces/WorldArena/WorldArena
Code repository:
https://github.com/tsinghua-fib-lab/WorldArena
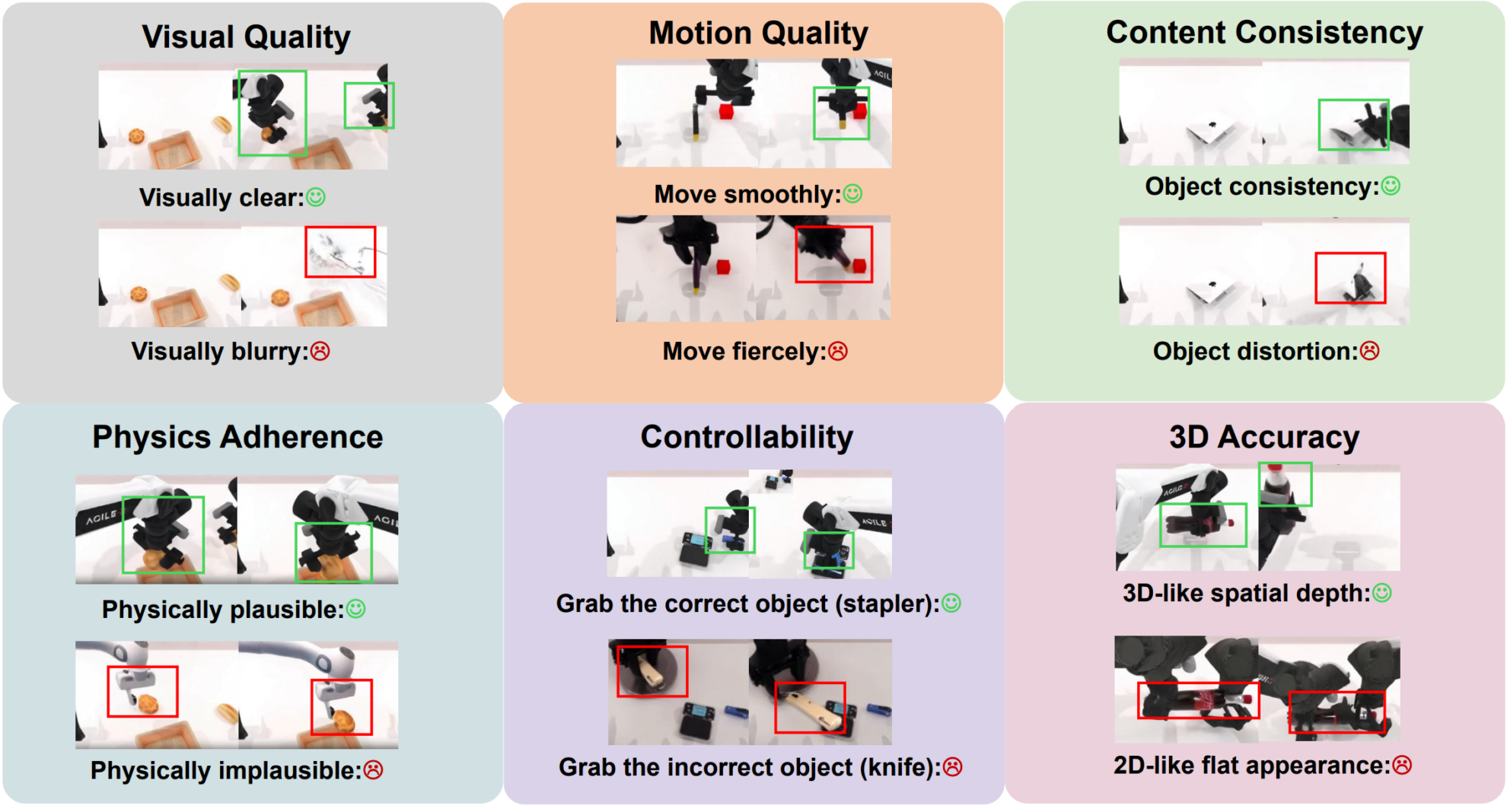
Redefining what constitutes a "good" generated video from six dimensions.
In order to systematically evaluate the quality of the generated videos,WorldArena is structured around 6 core dimensions.They not only focus on visual aesthetics, but also delve into the physical laws and spatial intelligence.
Visual quality
Visual quality is the most basic perceptual layer assessment. It measures the realism and statistical distribution similarity of a video at the pixel level through indicators such as image sharpness, aesthetic score, and JEPA representation similarity.This dimension primarily answers one question: Does the generated result visually approximate the actual data distribution?

Action quality
The motion quality dimension focuses on the temporal rationality, through optical flow continuity, motion intensity analysis, and motion smoothness.Assess whether the motion of objects in the video is coherent, stable, and conforms to natural laws.Even if a model can generate clear frames, its physical credibility is still insufficient if there are jumps or discontinuities in the motion trajectory.

Content consistency
In the real world, objects do not disappear or mutate. The content consistency dimension tracks the stability of the subject and background in time and space to detect problems such as structural drift, subject identity confusion, or background inconsistency.This dimension emphasizes the ability to maintain consistency, which is a prerequisite for supporting long-term tasks.

Physical compliance
Physical conformity is a crucial bridge connecting vision and function. WorldArena specifically evaluates whether the interaction between the robotic arm and objects in the video is reasonable and whether the motion trajectory conforms to basic dynamics. In other words, the model must not only "look" like it, but also "move correctly." This dimension directly relates to whether the model can be used for practical control and planning.

3D accuracy
Embodied intelligence relies on an understanding of three-dimensional spatial structures. The 3D accuracy dimension examines whether the model truly captures the spatial geometric relationships of the scene through depth estimation error and perspective consistency. If the spatial relationships are distorted, even if the two-dimensional image is realistic, the robot still cannot rely on that prediction to perform precise operations.

Controllability
Finally, there is controllability, which is a key capability for generative models to become practical.This dimension examines whether the model truly "understands" instructions, whether it can accurately respond to user input at the semantic level, and whether it can generate discriminative results under different conditions.Controllability is not only related to the quality of the generated data, but also to the adaptability to the task.

These six dimensions together constitute WorldArena's comprehensive profile of generated video quality. They are no longer isolated indicators, but rather mutually corroborating each other, all pointing to one goal: generated content must possess a high degree of realism in terms of perception, temporality, physics, space, and semantics.
The real test: Can the world model become the executor of the mission?
If video quality assessment is a "physical examination," then embodied task functionality assessment is a "real-world exercise." Another core breakthrough of WorldArena lies in its pioneering placement of world models within realistic mission execution scenarios.Starting with three key roles, we examine its true practical value.
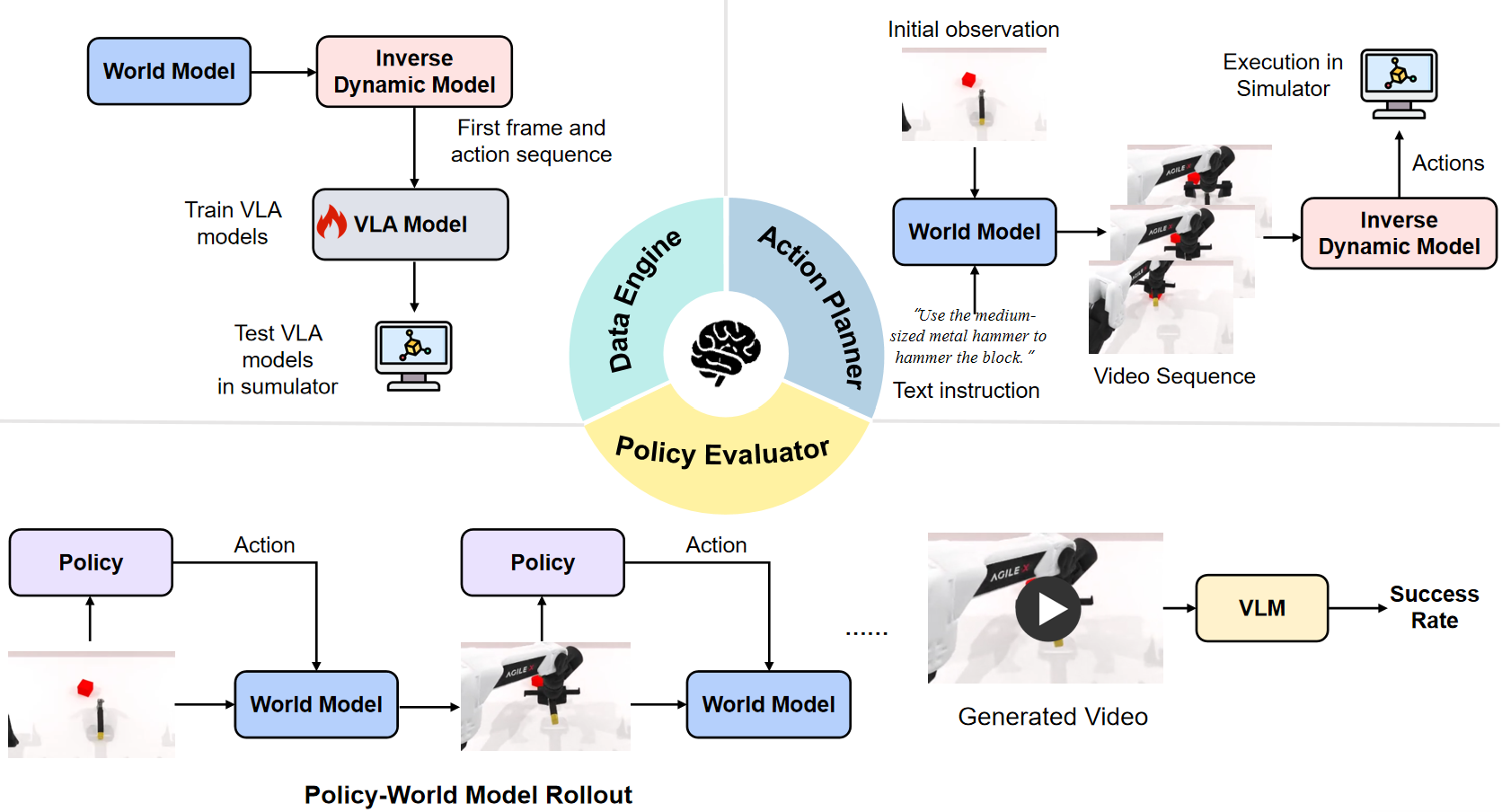
First, it serves as a data generation engine.
Can world models generate high-quality synthetic trajectory data to train downstream policy models (such as VLA)? Experimental results show that some models can indeed achieve performance improvements, but overall, the quality of synthetic data still lags significantly behind real data, and most models cannot yet provide stable and reliable gains for policy learning. This means that creating training data "out of thin air" using world models remains a challenge.

Second, it serves as a strategy evaluator.
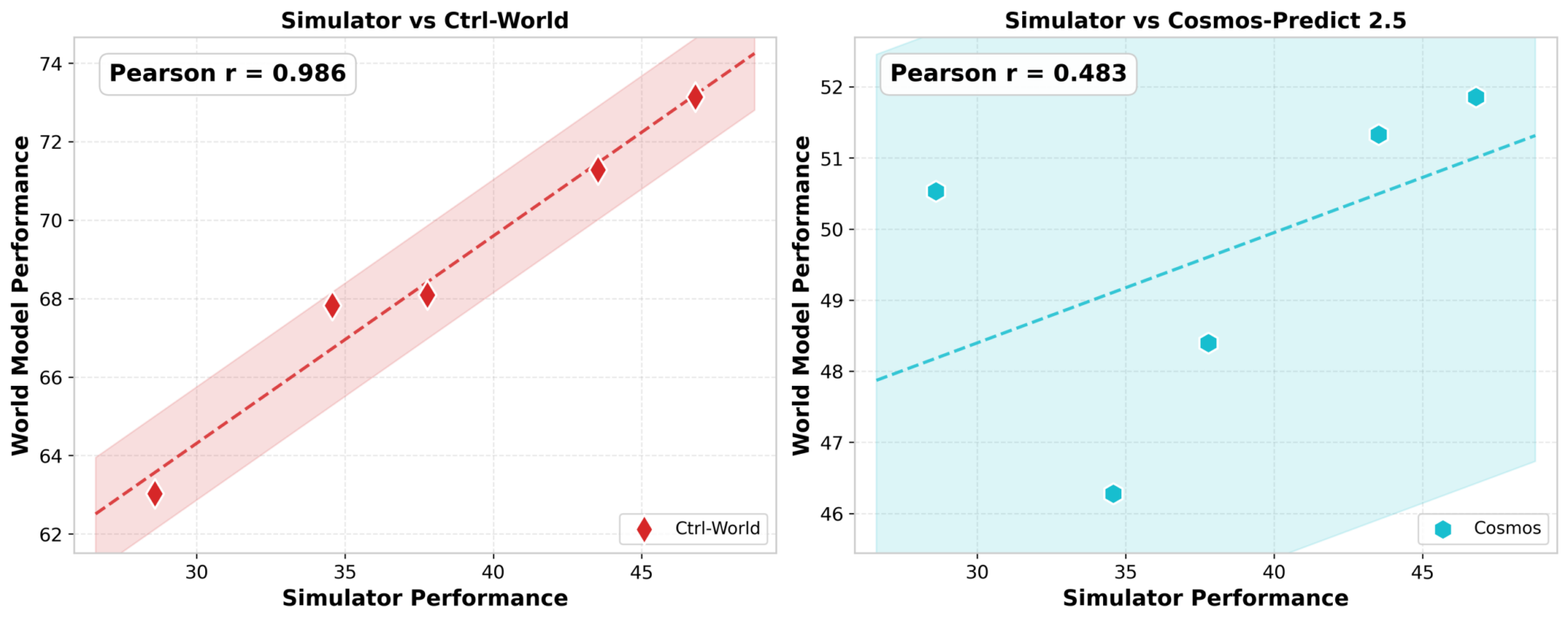
Can world models accurately simulate the dynamics of real-world environments, thus replacing the real environment in evaluating the performance of different strategy models? Researchers trained a series of VLA models with varying capabilities, tested them in both real-world simulation environments and world model environments, and compared the correlation between the two sets of results. The results showed significant differences: some models (such as CtrlWorld) achieved a correlation of up to 0.986 with the real environment, almost indistinguishable from reality; while others performed only moderately, reflecting their weakness in visual evaluation.
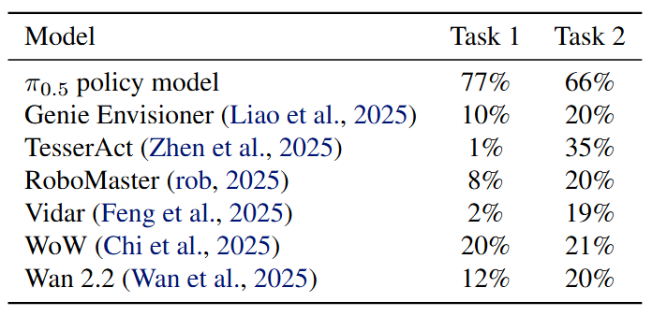
Third, it serves as an action planner.
This task integrates a world model into a closed-loop control system, allowing it to directly participate in end-to-end task execution. Experiments revealed that while some models can generate visually plausible future predictions, their performance in supporting long-term, multi-step closed-loop control tasks still lags significantly behind mature dedicated policy models (such as Pi 0.5). They may perform well in short-term predictions, but are prone to "losing their way" in complex long-term decision-making.
Visual realism is not the same as functional realism: a gap that must be faced.
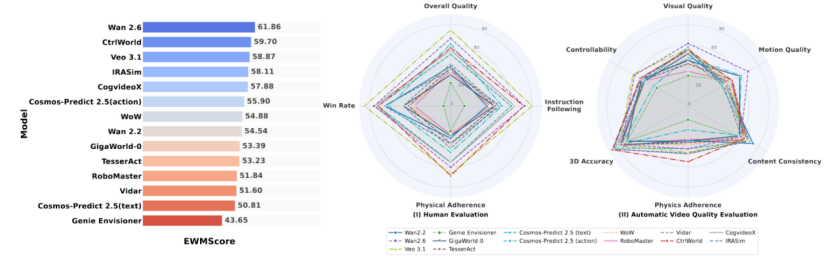
Through a systematic evaluation of 14 current mainstream world models, WorldArena reveals a harsh reality:There is a huge gap between visual generation capabilities and task execution capabilities.
Many models can generate highly realistic videos, but they reveal fundamental shortcomings in complex physical interactions, long-term consistency, and stable policy support. Therefore,WorldArena has introduced a unified comprehensive scoring metric, EWMScore, which integrates multi-dimensional video evaluation results into a single score that can be compared across different audiences.Importantly, EWMScore is highly positively correlated with human subjective assessment of video quality, demonstrating its effectiveness at the perceptual level.
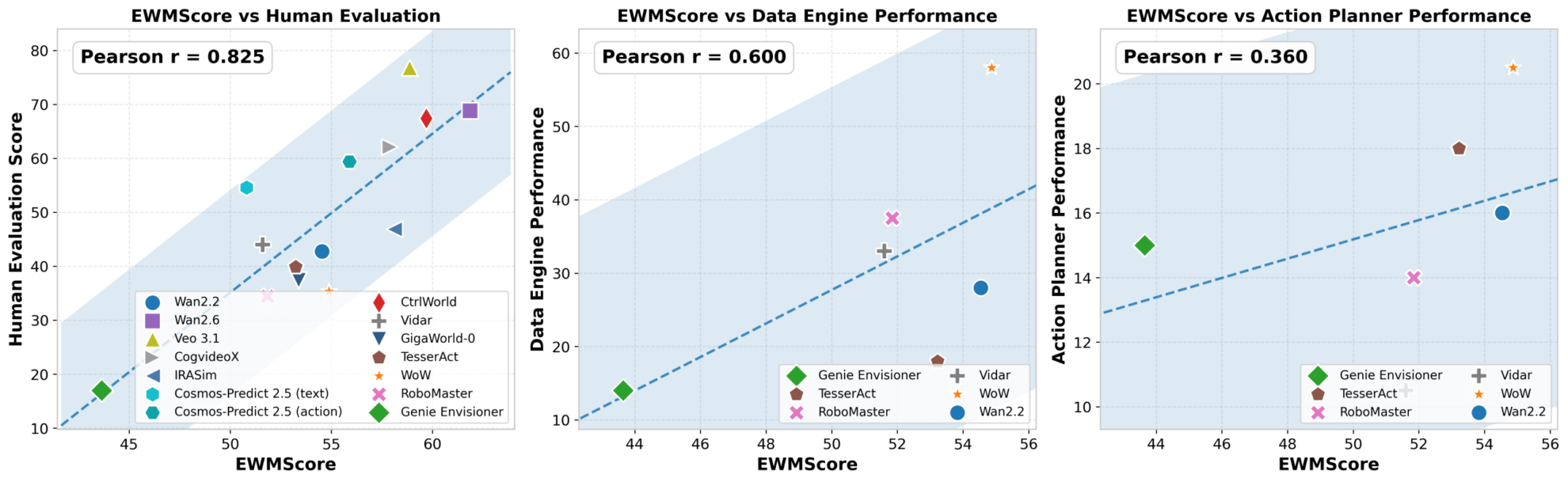
However, when researchers conducted a correlation analysis between EWMScore and embodied task performance, a more alarming fact emerged: its correlation with data engine tasks was 0.600, and its correlation with motion planning tasks was even lower at 0.360. This data clearly demonstrates that even if a model is visually acceptable to humans, it does not necessarily mean it can effectively support real-world embodied tasks. The gap between "aesthetically pleasing" and "user-friendly" is a hurdle that current technology must overcome.
WorldArena's significance lies not only in providing a new set of metrics, but also in changing researchers' focus. It shifts the focus from visual generation competitions to functional capability verification; from perceptual realism to physical understanding and long-term decision stability.
When the competition of world models is no longer limited to "who is more like a movie", but rather "who understands physics better, who is more robust, and who can better support real-world decision-making", the development of embodied intelligence will truly enter a new stage.
Evaluation systems determine the direction of technological evolution. What WorldArena has proposed is a necessary path to practical embodied intelligence.