Command Palette
Search for a command to run...
The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models via the Lens of Problem Complexity
The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models via the Lens of Problem Complexity
Parshin Shojae Iman Mirzadeh Keivan Alizadeh Maxwell Horton Samy Bengio Mehrdad Farajtabar
Abstract
Recent generations of frontier language models have introduced Large Reasoning Models (LRMs) that generate detailed thinking processes before providing answers. While these models demonstrate improved performance on reasoning benchmarks, their fundamental capabilities, scaling properties, and limitations remain insufficiently understood. Current evaluations primarily focus on established mathematical and coding benchmarks, emphasizing final answer accuracy. However, this evaluation paradigm often suffers from data contamination and does not provide insights into the reasoning traces' structure and quality. In this work, we systematically investigate these gaps with the help of controllable puzzle environments that allow precise manipulation of compositional complexity while maintaining consistent logical structures. This setup enables the analysis of not only final answers but also the internal reasoning traces, offering insights into how LRMs "think". Through extensive experimentation across diverse puzzles, we show that frontier LRMs face a complete accuracy collapse beyond certain complexities. Moreover, they exhibit a counter-intuitive scaling limit: their reasoning effort increases with problem complexity up to a point, then declines despite having an adequate token budget.
One-sentence Summary
This work systematically investigates Large Reasoning Models using controllable puzzle environments to analyze internal reasoning traces, revealing that unlike current evaluations emphasizing final answer accuracy, frontier LRMs face complete accuracy collapse beyond certain complexities and exhibit a counterintuitive scaling limit where reasoning effort declines despite an adequate token budget.
Key Contributions
- The paper introduces controllable puzzle environments that allow precise manipulation of compositional complexity while maintaining consistent logical structures. This setup enables the analysis of internal reasoning traces alongside final answers to offer insights into how Large Reasoning Models think.
- Through extensive experimentation across diverse puzzles, the work shows that frontier Large Reasoning Models face a complete accuracy collapse beyond certain complexities. This evidence addresses gaps in evaluations that primarily focus on final answer accuracy without considering reasoning trace quality.
- The study identifies a counter-intuitive scaling limit where reasoning effort increases with problem complexity up to a point, then declines despite having an adequate token budget. This observation clarifies the fundamental capabilities and scaling properties of Large Reasoning Models that remain insufficiently understood.
Introduction
Large Reasoning Models (LRMs) have emerged as powerful tools for complex problem solving by generating detailed thinking processes before answering, yet their fundamental capabilities and scaling properties remain insufficiently understood. Current evaluation paradigms rely on established math and coding benchmarks that often suffer from data contamination and fail to reveal the quality of internal reasoning traces. To address this, the authors leverage controllable puzzle environments that allow precise manipulation of problem complexity while maintaining consistent logical structures. This setup enables a systematic analysis of both final answers and reasoning traces, revealing that frontier LRMs experience complete accuracy collapse beyond specific complexity thresholds and exhibit a counter-intuitive scaling limit where reasoning effort decreases as problems become harder.
Dataset

The authors construct a procedural evaluation benchmark comprising four controllable puzzle environments to test reasoning capabilities. This dataset is not sourced from a static corpus but is generated dynamically based on specific complexity parameters.
-
Dataset Composition and Sources
- The benchmark includes Tower of Hanoi, Checker Jumping, River Crossing, and Blocks World.
- Difficulty is controlled by adjusting parameters such as disk count, checker count, or block count.
-
Key Details for Each Subset
- Tower of Hanoi: Defined by N disks. Constraints require moving only the top disk and never placing a larger disk on a smaller one.
- Checker Jumping: Defined by 2n checkers (red and blue). Valid moves include sliding into adjacent empty spaces or jumping over one opposite-colored checker without moving backward.
- River Crossing: Defined by N actor-agent pairs. Boat capacity k is set to 2 for N≤3 pairs and 3 for larger sets. Safety rules prevent actors from being with foreign agents without their own agent.
- Blocks World: Defined by N blocks. Initial states divide blocks alphabetically between two stacks. Goal states require interleaving blocks to force complete disassembly and reassembly.
-
Usage in the Model
- The data is used exclusively for evaluation to measure Pass@k performance.
- The authors compare thinking models against non-thinking counterparts across varying complexity levels.
- No training mixture ratios are applied as the focus is on inference-time reasoning.
-
Processing and Validation
- Custom simulators track state evolution and validate each move against puzzle constraints.
- Prompts include system instructions, rule definitions, and formatted examples for solution output.
- Validation processes check for peg boundaries, disk positions, move types, and final goal state achievement.
Method
The proposed framework evaluates reasoning capabilities by combining structured prompting with rigorous simulation-based verification. For logic puzzles such as the Tower of Hanoi, River Crossing, and Blocks World, the system employs specific system prompts that define the rules, initial states, and goal configurations. These prompts explicitly instruct the model to generate a sequence of moves, often requiring a structured format such as a list of tuples or specific tags. To ensure validity, custom simulators are integrated into the evaluation pipeline. For example, the River Crossing simulator enforces safety constraints regarding actors and agents, while the Blocks World simulator validates that only the topmost block is moved and checks stack boundaries.
The evaluation process involves parsing the model's generation to separate reasoning from the final result. Refer to the framework diagram for a visualization of this extraction pipeline.
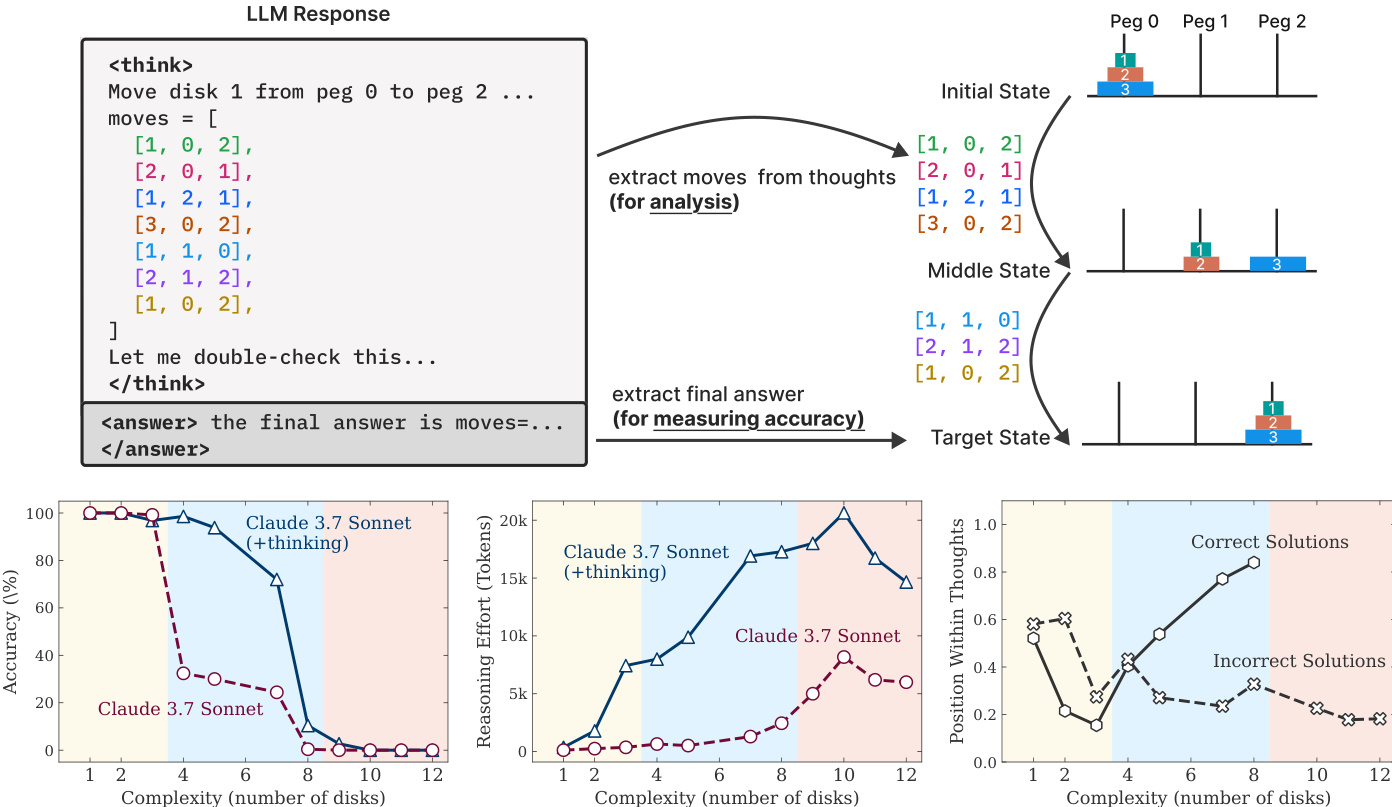
The system distinguishes between the reasoning trace enclosed in <think> tags and the final answer in <answer> tags. Moves extracted from the thought process are used to reconstruct the state transitions, mapping the sequence from the initial state through middle states to the target state. This allows for a granular analysis of the reasoning path, distinct from the final accuracy measurement derived from the answer block. The associated plots demonstrate how reasoning effort and accuracy scale with problem complexity, indicating that deeper reasoning traces often correlate with correct solutions.
To further support complex reasoning, the method leverages algorithmic scratchpads. As shown in the figure below:

This approach allows the model to simulate the problem-solving process step-by-step within its generation, validating moves against specific rules before committing to a sequence. For instance, the framework encourages the use of recursive pseudocode with backtracking to explore potential solutions. This structured algorithmic guidance helps the model adhere to the puzzle constraints during the reasoning phase, ensuring that moves such as jumps or block transfers comply with the defined logic.
Experiment
The study evaluates frontier Large Reasoning Models against non-reasoning counterparts using controlled puzzle environments to systematically analyze performance across varying problem complexities. Results identify three distinct reasoning regimes where reasoning models excel at moderate complexity but ultimately collapse alongside standard models at high complexity, often reducing inference effort counterintuitively. Detailed trace analysis reveals inefficient overthinking on simple tasks and a fundamental inability to execute prescribed logical algorithms, indicating that current reasoning capabilities are limited by training data familiarity rather than pure computational complexity.