Command Palette
Search for a command to run...
Fara-7B: An Efficient Agentic Model for Computer Use
Fara-7B: An Efficient Agentic Model for Computer Use
Abstract
Progress in computer use agents (CUAs) has been constrained by the absence of large and high-quality datasets that capture how humans interact with a computer. While LLMs have thrived on abundant textual data, no comparable corpus exists for CUA trajectories. To address these gaps, we introduce FaraGen, a novel synthetic data generation system for multi-step web tasks. FaraGen can propose diverse tasks from frequently used websites, generate multiple solution attempts, and filter successful trajectories using multiple verifiers. It achieves high throughput, yield, and diversity for multi-step web tasks, producing verified trajectories at approximately $1 each. We use this data to train Fara-7B, a native CUA model that perceives the computer using only screenshots, executes actions via predicted coordinates, and is small enough to run on-device. We find that Fara-7B outperforms other CUA models of comparable size on benchmarks like WebVoyager, Online-Mind2Web, and WebTailBench -- our novel benchmark that better captures under-represented web tasks in pre-existing benchmarks. Furthermore, Fara-7B is competitive with much larger frontier models, illustrating key benefits of scalable data generation systems in advancing small efficient agentic models. We are making Fara-7B open-weight on Microsoft Foundry and HuggingFace, and we are releasing WebTailBench.
One-sentence Summary
Microsoft researchers introduce FaraGen, a scalable synthetic data engine generating verified web task trajectories at ~$1 each, enabling training of Fara-7B—a compact, screenshot-based CUA model that outperforms peers on WebVoyager and WebTailBench while running efficiently on-device.
Key Contributions
- FaraGen introduces a scalable synthetic data engine that automates task proposal, multi-agent solving, and LLM-based verification to generate high-quality, diverse web interaction trajectories at ~$1 per task, addressing the critical data scarcity bottleneck in computer use agent (CUA) research.
- Fara-7B, a compact 7B-parameter CUA trained on FaraGen’s 145K trajectory dataset, operates via pixel-in, action-out inference (using screenshots and coordinate predictions) and achieves state-of-the-art performance on benchmarks like WebVoyager and WebTailBench while running efficiently on-device.
- The paper releases WebTailBench, a new benchmark targeting under-represented real-world web tasks, and demonstrates that Fara-7B rivals much larger frontier models in performance while offering superior cost-efficiency and privacy-preserving local deployment.
Introduction
The authors leverage synthetic data generation to overcome the scarcity of high-quality human-computer interaction datasets needed to train computer use agents (CUAs). Prior work relied on manual annotation, constrained environments, or brittle DOM-based approaches that fail to generalize to real-world, dynamic web interfaces. FaraGen, their multi-agent data engine, automatically proposes, solves, and verifies multi-step web tasks at ~$1 per trajectory, enabling scalable training of Fara-7B — a compact 7B-parameter model that perceives screens via raw screenshots and predicts low-level actions like clicks and scrolls. Fara-7B matches or exceeds larger models on web benchmarks and introduces WebTailBench to evaluate underrepresented real-world tasks, demonstrating that small, efficient models can achieve strong agentic performance when trained on targeted synthetic data.
Dataset
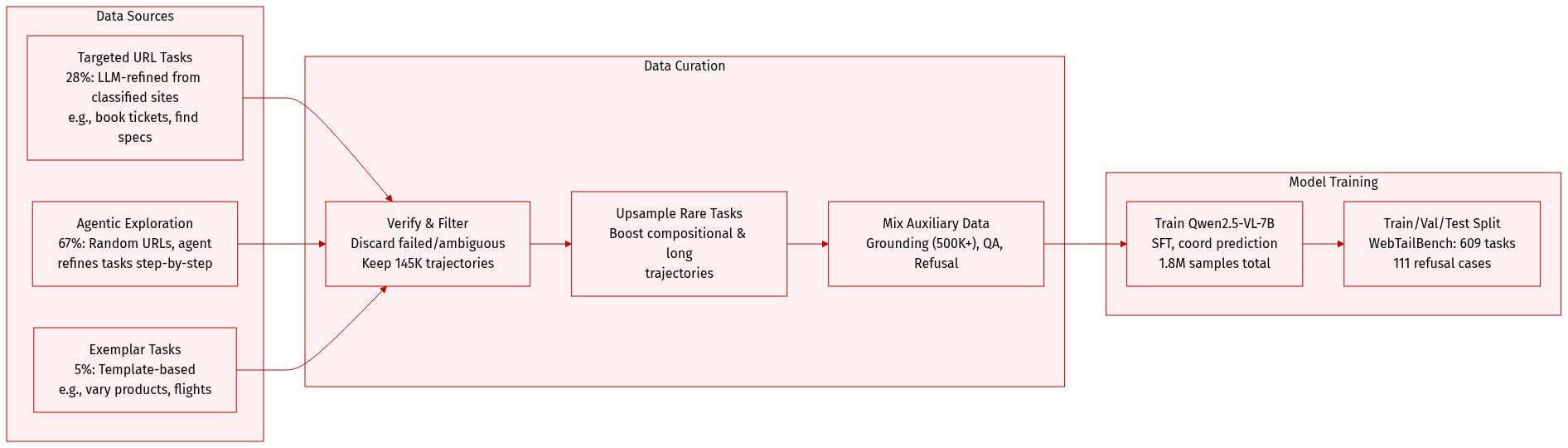
The authors use FaraGen, a synthetic data engine, to generate high-quality computer use agent (CUA) training data by avoiding manual annotation and instead leveraging real websites and LLM-driven task generation. Here’s how the dataset is composed and used:
-
Dataset Composition & Sources:
- Built from three task generation strategies: Targeted URL Task Proposal (28% of tasks), Agentic URL Exploration (67%), and Exemplar Task Proposal (remaining 5%).
- Primary URL sources: ClueWeb22 (preferred for richer, task-relevant sites) and Tranco (used for comparison).
- Tasks span information-seeking (e.g., product specs) and actionable goals (e.g., booking, purchasing), with 28% being compositional (multi-site, multi-step).
-
Key Subset Details:
- Targeted URL Tasks: Generated from classified URLs (e.g., “movies”, “restaurants”) using LLMs to create verifiable, login-free, real-world tasks. Filtered for achievability, specificity, and usefulness.
- Agentic Exploration Tasks: Agents traverse random URLs using screenshots and accessibility trees to iteratively refine and complete tasks. Simpler on average, with fewer steps.
- Exemplar Tasks: Expand existing seed tasks via LLM templating (e.g., varying products, retailers, or flight parameters).
- WebTailBench (609 tasks): A hand-verified benchmark subset targeting 11 underrepresented categories (e.g., real estate, job apps, multi-item shopping), including 111 refusal tasks across 7 harmful categories.
-
Data Usage in Training:
- Final dataset: 145K verified trajectories (1M steps) across 70K domains; avg. 0.5 unique domains per trajectory, indicating high diversity.
- Trajectory data is split into steps; each step includes screenshot, reasoning text, and action (converted from SoM IDs to pixel coordinates).
- Mixed with auxiliary data: grounding (500K+ samples), UI QA/captioning, and refusal data. Total training samples: 1.8M.
- Trajectory data is upsampled for longer or rarer task types (e.g., compositional tasks). Grounding data is second-largest component; refusal data is minimal to avoid over-refusal.
-
Processing & Metadata:
- Screenshots and accessibility trees guide agent actions; actions are grounded to pixel coordinates for direct model prediction.
- Verification agents filter successful trajectories; failed or ambiguous tasks are discarded.
- Grounding data uses element descriptions + VLM verification; QA data is generated via GPT-5 prompts focused on image-grounded, challenging questions.
- Refusal data combines synthetic harmful tasks (based on training screenshots) and curated examples from WildGuard.
- Training uses Qwen2.5-VL-7B base model, SFT with cross-entropy loss, and coordinate prediction via tokenization. Batch size 128, 2 epochs, bf16 precision, DeepSpeed Stage 3 on 64 H100 GPUs.
Method
The authors leverage a multi-agent system built on Magentic-One to generate high-quality demonstration trajectories for supervised fine-tuning. This system centers around two core agents: the Orchestrator and the WebSurfer, which operate in a tightly coupled loop to solve synthetic web tasks. The Orchestrator is responsible for high-level planning, progress monitoring, and enforcing safety constraints—particularly around critical points—while the WebSurfer executes low-level browser actions based on the Orchestrator’s directives. Refer to the framework diagram below, which illustrates the iterative interaction between these agents, the role of the UserSimulator in multi-turn task extension, and the final filtering through trajectory verifiers before trajectories are stored for training.
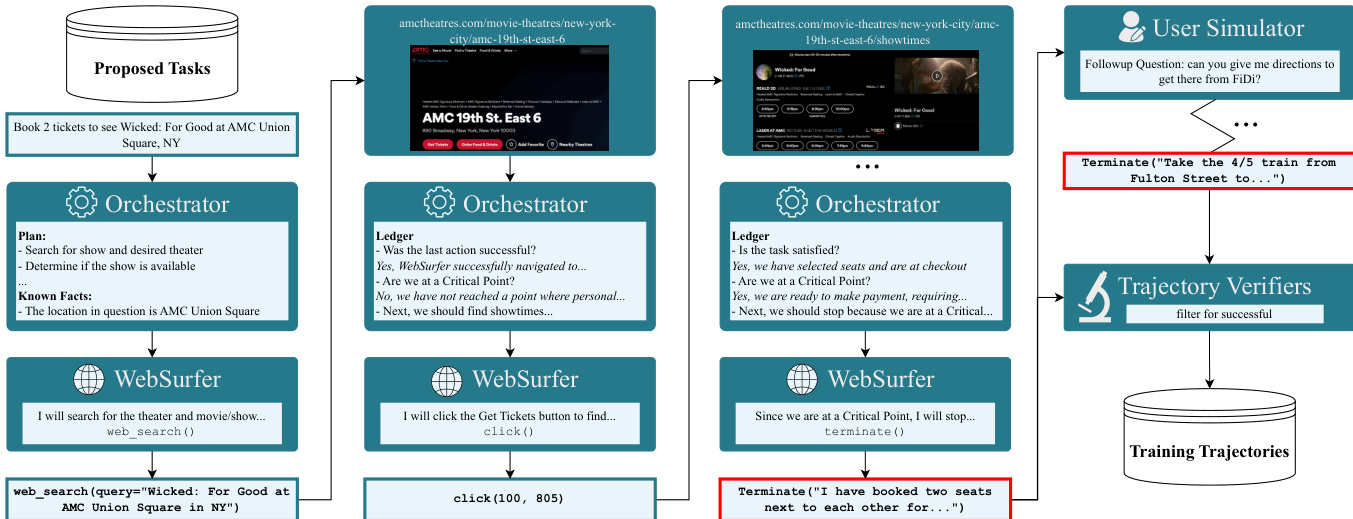
At each step, the Orchestrator maintains a diagnostic ledger that tracks five key properties of the trajectory’s state, including whether the last action was successful, whether the task is satisfied, and whether a critical point has been reached. These fields are inferred from the WebSurfer’s action history and the preceding and current screenshots. Based on this ledger, the Orchestrator decides whether to issue the next instruction, re-plan, or terminate the trajectory. Critical points—defined as irreversible actions requiring user consent, such as submitting personal data or completing a purchase—are strictly enforced as stopping conditions. When such a point is reached, the UserSimulator may be invoked to simulate user input, allowing the pipeline to resume from that point with synthetic approval or data.
The WebSurfer, acting as a SoM (State of the Model) agent, receives as input the current browser screenshot annotated with bounding boxes from the accessibility tree, the full history of prior actions, and the Orchestrator’s next-step instruction. It then outputs a chain-of-thought reflection on the current state, followed by a specific tool call (e.g., click, type, scroll) to execute in the browser. The action is then performed, and the resulting screenshot, along with the WebSurfer’s reasoning and action, is reported back to the Orchestrator. This closed-loop interaction continues until a stopping condition is met.
To ensure robustness and scalability, the authors introduce several architectural refinements. The WebSurfer’s action space is dynamic—for instance, scroll_up is disabled if the viewport is already at the top of the page—and includes a Memorize action to store key information across pages, reducing hallucinations. The Orchestrator’s decision logic is governed by a precedence-based table that resolves conflicts between agent signals, with critical point detection taking highest priority. Additionally, the system employs loop-detection heuristics: a coarse-grained is_in_loop flag triggers re-planning after repeated failures, while a fine-grained last_action_successful flag evaluates whether the visual change between screenshots aligns with the executed action.
The generated trajectories are then subjected to a multi-verifier pipeline to ensure correctness before inclusion in training. Three complementary LLM-based verifiers assess trajectories from different angles: an Alignment Verifier checks high-level task intent, a Rubric Verifier scores partial completion against a generated rubric, and a Multimodal Verifier validates consistency between the final response and salient screenshots. This layered verification is essential, as even sophisticated task-solving systems exhibit failure modes—particularly in longer, more complex tasks—where subtle errors like looping or hallucination can go undetected without multimodal evidence checks.
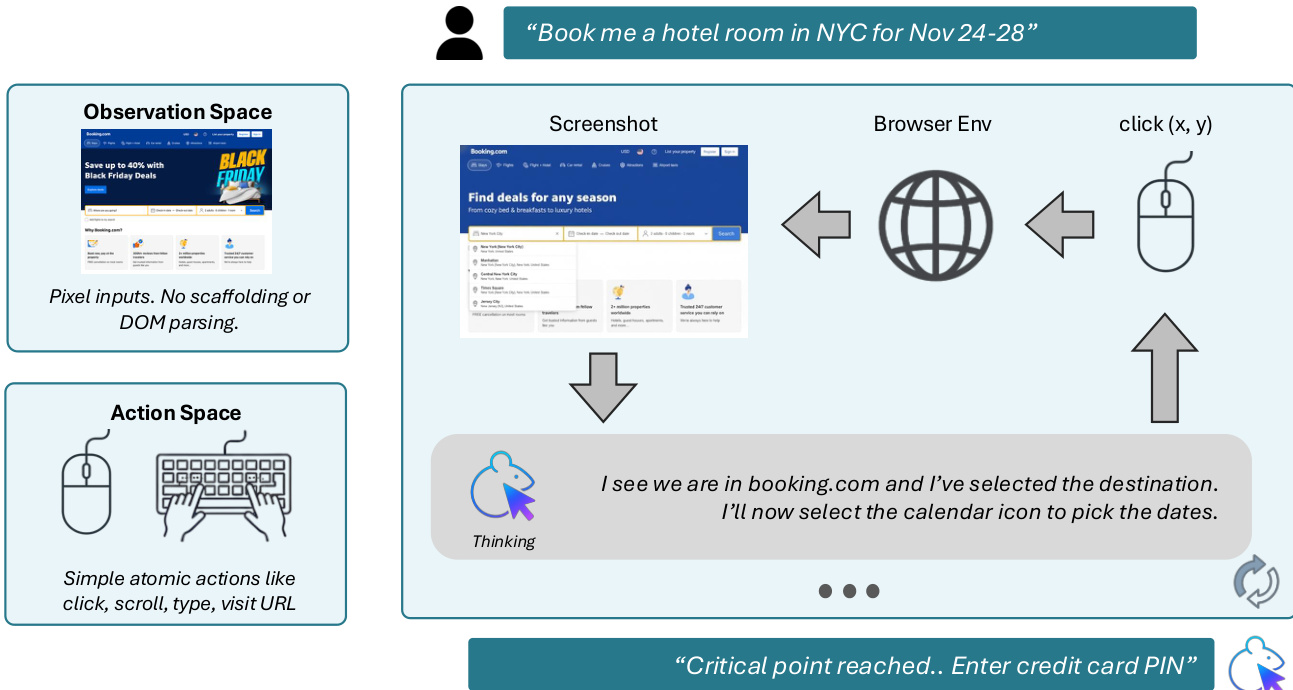
The final model, Fara-7B, is trained to distill the behaviors learned from these multi-agent trajectories into a single, efficient computer-use agent. Unlike the training-time agents, Fara-7B operates without accessibility trees at inference time, relying solely on pixel inputs (screenshots) and browser metadata (e.g., URL). It predicts grounded actions—such as click coordinates—directly from the visual input. The model’s architecture is designed to output a sequence of steps, each comprising an observation ot, thoughts rt, and action at, conditioned on the full history of prior steps and the initial query q0:
P(rt,at∣q0,{o0,r0,a0},…,{ot−1,rt−1,at−1}).To manage computational load from high-token visual inputs, the model retains only the most recent N=3 observations in context while preserving the full history of thoughts and actions. Fara-7B also supports multi-turn interactions: if a user issues a follow-up query q1 after the initial task q0 is completed, the model continues predicting steps while maintaining the full trajectory history, enabling seamless task chaining.
As shown in the figure below, Fara-7B’s inference flow is streamlined: it receives a user query, observes the browser environment via screenshot, reasons internally, and outputs atomic actions like click, type, or scroll. It is explicitly trained to terminate and hand back control when reaching critical points, ensuring safe and user-aligned behavior.
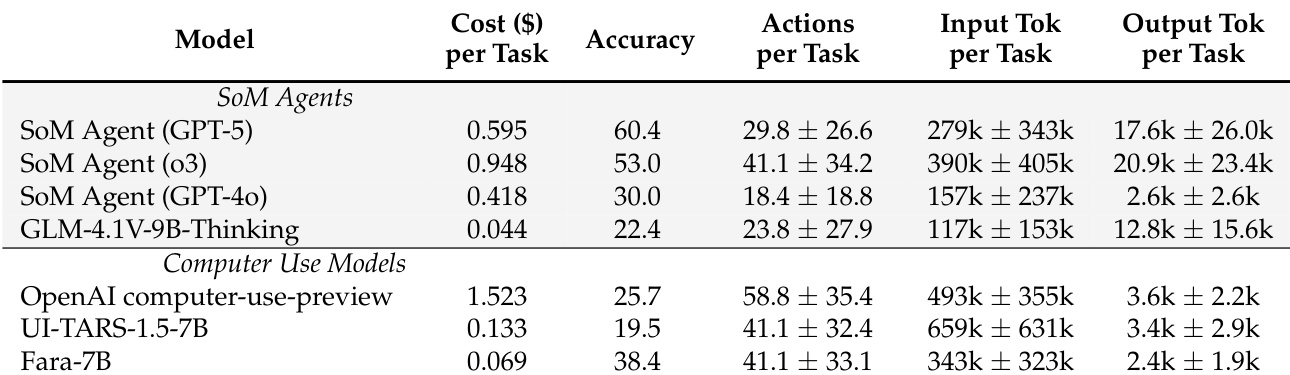
Experiment
- FaraGen enables cost-effective generation of large-scale CUA training data (~$1 per trajectory), even with premium models, making scalable data creation economically viable.
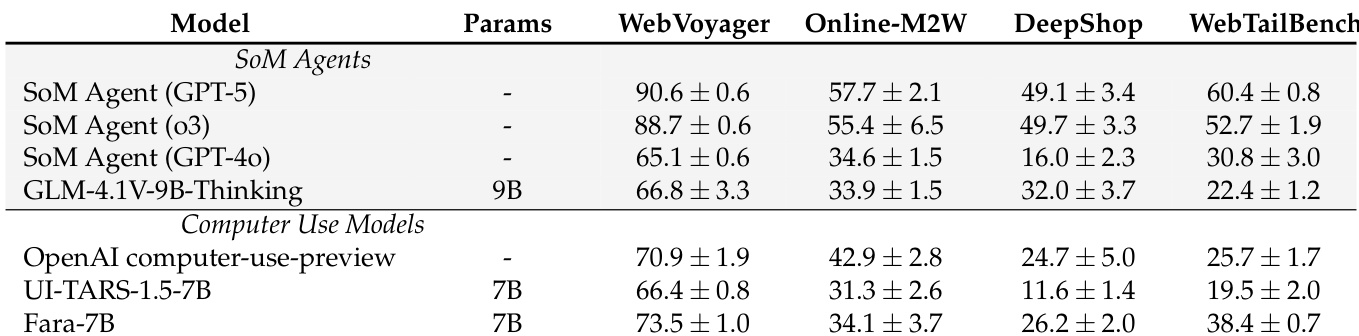
- Fara-7B outperforms comparable 7B-scale CUA models and matches or exceeds larger SoM agents across multiple web benchmarks, particularly excelling in shopping and tail-bench tasks.
- Fara-7B achieves strong grounding performance, improving over its base model and demonstrating reliable UI element localization, especially for text-based elements.
- The model shows significant performance gains with increased training data and benefits from longer inference step budgets, rivaling RL-trained models despite using only supervised fine-tuning.
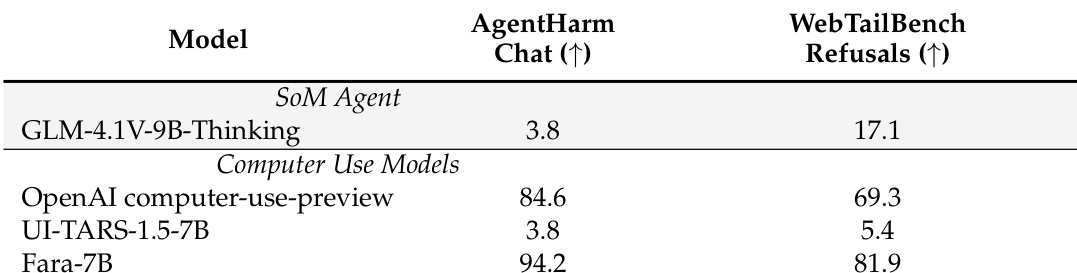
- Fara-7B leads in safety evaluations, refusing harmful tasks at higher rates than baselines and reliably pausing before critical actions (e.g., entering personal data or confirming bookings) to prevent unintended consequences.
- It achieves superior cost-efficiency, using 10x fewer output tokens than larger models and costing ~0.025pertaskversus 0.30 for proprietary baselines, while maintaining competitive accuracy and step efficiency.
- Human evaluations confirm its performance, though slightly lower than auto-eval metrics, highlighting the need for improved LLM-as-judge frameworks for CUA tasks.
- Despite limited training data per skill (e.g., <4K flight/hotel tasks), Fara-7B approaches frontier model performance in specific domains, validating the effectiveness of high-quality, targeted data.
- Adversarial testing shows resilience against phishing and malicious UI traps, with failures limited to edge cases mitigated by browser sandboxing.
Fara-7B outperforms other 7B-scale computer-use models across multiple web benchmarks and matches or exceeds larger SoM agents in several categories, demonstrating strong agentic capabilities despite its smaller size. It achieves this while being significantly more cost-efficient, using far fewer output tokens per task than proprietary baselines. The model also shows consistent performance across repeated evaluations, indicating stable and reliable behavior in real-world web environments.
The authors use a diverse dataset comprising over 1.8 million samples across trajectory generation, grounding, refusals, and UI captioning to train Fara-7B, with trajectory data forming the dominant component. Results show that this balanced training approach supports strong performance across agentic, safety, and perception tasks, enabling the model to achieve high accuracy while maintaining cost efficiency and safety compliance. The scale and composition of the data reflect a deliberate focus on generating high-quality, task-relevant interactions that drive robust real-world behavior.

Fara-7B demonstrates significantly stronger safety performance than other computer-use models, achieving the highest refusal rates on both AgentHarm-Chat and WebTailBench-Refusals benchmarks. It outperforms the OpenAI computer-use-preview model and UI-TARS-1.5-7B by wide margins, indicating its training effectively instills robust refusal behavior for harmful tasks. The results highlight Fara-7B’s ability to prioritize user safety while maintaining functional capabilities.
Fara-7B demonstrates improved grounding performance over its base model Qwen2.5-VL, achieving higher accuracy on both ScreenSpot-V1 and ScreenSpot-V2 benchmarks. It shows strong localization capabilities across mobile, desktop, and web interfaces, particularly excelling in text element grounding while maintaining solid performance on icon/widget identification. These results indicate that Fara-7B’s training enhances its ability to accurately perceive and interact with diverse UI elements, supporting its use as a reliable computer-use agent.

Fara-7B achieves higher accuracy than other 7B-scale computer-use models while costing significantly less per task, demonstrating a favorable cost-accuracy trade-off. It uses fewer output tokens than larger SoM agents, contributing to its efficiency, despite requiring a similar number of actions and input tokens. The model also shows competitive performance against more expensive proprietary systems, particularly in cost-sensitive deployment scenarios.