Command Palette
Search for a command to run...
Dr. Zero: Self-Evolving Search Agents without Training Data
Dr. Zero: Self-Evolving Search Agents without Training Data
Zhenrui Yue Kartikeya Upasani Xianjun Yang Suyu Ge Shaoliang Nie Yuning Mao Zhe Liu Dong Wang
Abstract
As high-quality data becomes increasingly difficult to obtain, data-free self-evolution has emerged as a promising paradigm. This approach allows large language models (LLMs) to autonomously generate and solve complex problems, thereby improving their reasoning capabilities. However, multi-turn search agents struggle in data-free self-evolution due to the limited question diversity and the substantial compute required for multi-step reasoning and tool using. In this work, we introduce Dr. Zero, a framework enabling search agents to effectively self-evolve without any training data. In particular, we design a self-evolution feedback loop where a proposer generates diverse questions to train a solver initialized from the same base model. As the solver evolves, it incentivizes the proposer to produce increasingly difficult yet solvable tasks, thus establishing an automated curriculum to refine both agents. To enhance training efficiency, we also introduce hop-grouped relative policy optimization (HRPO). This method clusters structurally similar questions to construct group-level baselines, effectively minimizing the sampling overhead in evaluating each query's individual difficulty and solvability. Consequently, HRPO significantly reduces the compute requirements for solver training without compromising performance or stability. Extensive experiment results demonstrate that the data-free Dr. Zero matches or surpasses fully supervised search agents, proving that complex reasoning and search capabilities can emerge solely through self-evolution.
One-sentence Summary
The authors from Meta Superintelligence Labs and the University of Illinois Urbana-Champaign propose Dr. Zero, a data-free self-evolution framework that enables search agents to autonomously improve reasoning and search capabilities through a co-evolutionary loop between a proposer and solver, leveraging an external search engine for supervision; the key innovation lies in hop-grouped relative policy optimization (HRPO), which clusters structurally similar questions to eliminate costly nested sampling and reduce compute overhead while maintaining performance, enabling the system to match or exceed supervised baselines on complex open-domain QA benchmarks without any training data.
Key Contributions
- Dr. Zero enables data-free self-evolution of search agents by eliminating reliance on human-curated questions or answer annotations, instead using an external search engine to provide supervision signals through a difficulty-guided reward that encourages the generation of complex, multi-hop queries.
- The framework introduces hop-grouped relative policy optimization (HRPO), which clusters structurally similar questions to establish robust group-level baselines, thereby avoiding the computationally expensive nested sampling required by standard methods while maintaining training stability and performance.
- Extensive experiments show that Dr. Zero's self-evolving agents match or exceed fully supervised baselines by up to 14.1% on complex QA benchmarks, demonstrating that advanced reasoning and search capabilities can emerge solely through autonomous self-evolution without any training data.
Introduction
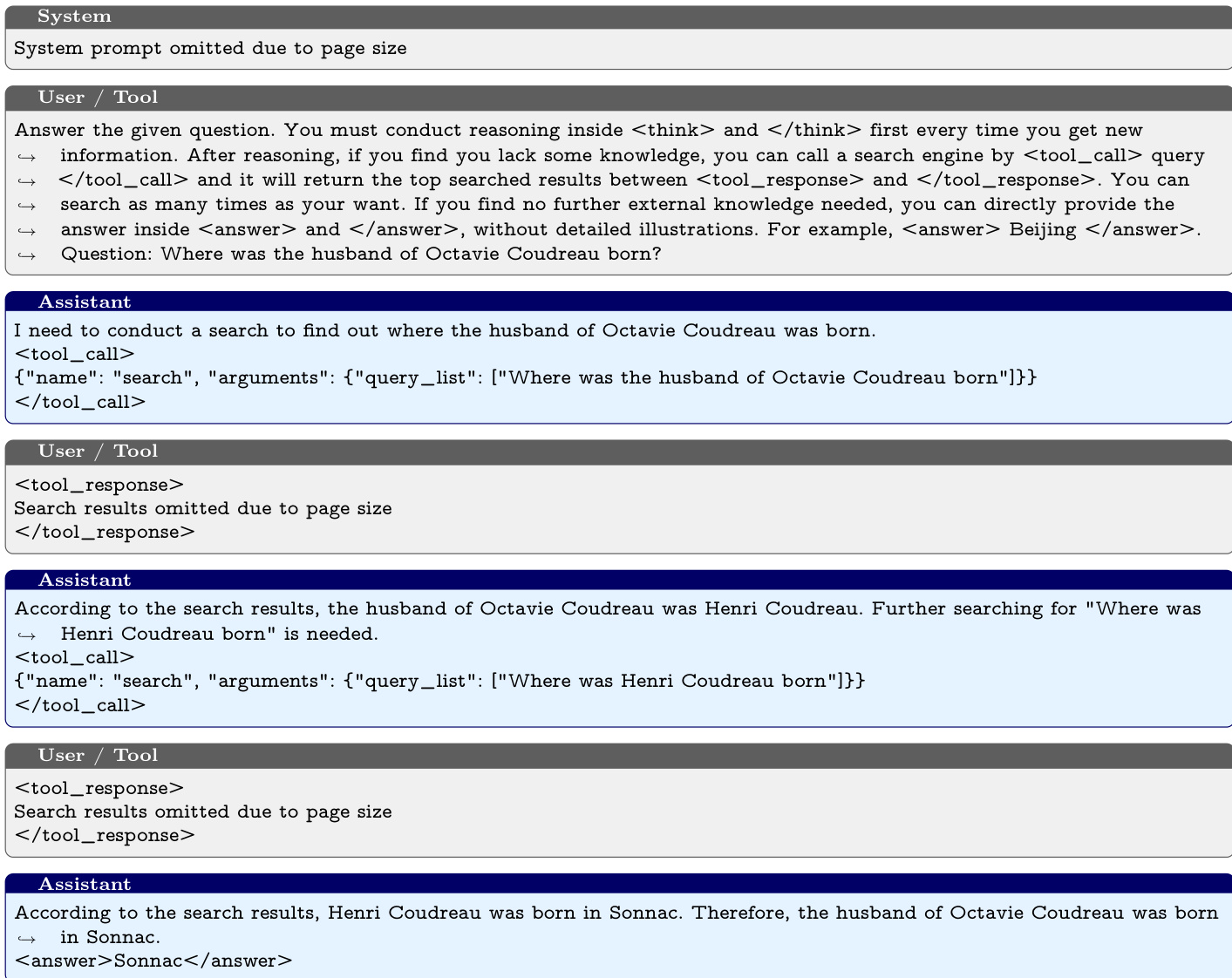
The authors leverage external search engines to enable self-evolving search agents in a data-free setting, where large language models (LLMs) autonomously generate and solve complex, open-domain questions without relying on human-curated data or annotations. This is critical for scaling reasoning and search capabilities in real-world applications where high-quality training data is scarce or expensive to obtain. Prior work in self-evolving LLMs faces two key challenges: proposers generate limited question diversity—often favoring simple, one-hop queries—and standard training methods like group relative policy optimization (GRPO) require computationally expensive nested sampling, making them impractical for multi-step reasoning and tool use. To address these, the authors introduce Dr. Zero, a framework that combines a refined multi-turn tool-use pipeline with a difficulty-guided reward to drive the proposer toward generating increasingly complex, verifiable questions. They further propose hop-grouped relative policy optimization (HRPO), which clusters structurally similar questions to create stable, group-level baselines for advantage estimation—eliminating the need for nested sampling while maintaining training efficiency and performance. Experiments show Dr. Zero matches or exceeds fully supervised baselines on complex QA benchmarks, demonstrating that advanced reasoning and search abilities can emerge purely through self-evolution.
Dataset

- The dataset comprises multiple open-domain question answering benchmarks, including three one-hop datasets: Natural Questions (NQ), TriviaQA, and PopQA, and four multi-hop datasets: HotpotQA, 2WikiMultihopQA (2WikiMQA), MuSiQue, and Bamboogle.
- These datasets are sourced from publicly available academic publications and cover a wide range of search and reasoning challenges, enabling evaluation across both single-turn and multi-hop question scenarios.
- The authors use Qwen2.5 3B/7B Instruct as the base language models for all experiments, including both Dr. Zero and the baseline methods.
- Dr. Zero is evaluated against a range of baselines: few-shot methods (standard prompting, IRCoT, Search-o1, and RAG), and supervised methods (SFT, R1, and Search-R1).
- All models are evaluated using exact match under identical conditions: the E5 base model as the search engine and an English Wikipedia dump as the corpus.
- A key distinction is that all baseline methods rely on human-annotated demonstrations or training data, while Dr. Zero operates without any such data, making it a data-free approach.
- The evaluation setup ensures fair comparison by using consistent search and retrieval infrastructure across all methods.
Method
The authors leverage a proposer-solver self-evolution framework where both models function as search agents capable of leveraging external knowledge through a search engine R. The proposer πθ and the solver πϕ are trained to maximize their respective expected rewards. The proposer's objective is to generate diverse and challenging questions, while the solver's objective is to produce correct answers. The proposer reward is defined over the distribution of predicted answers {y^i}i=1n, penalizing questions that are either trivial (all predictions correct) or too difficult (no predictions correct). The solver's reward is based on the outcome, using an indicator function to assess correctness. This creates a symbiotic loop where the proposer learns to synthesize increasingly complex queries based on solver feedback, and the solver improves its reasoning capabilities by solving these queries, forming a continuously evolving curriculum.
The proposer training faces challenges due to the high computational cost of generating multiple responses for a single prompt, which is exacerbated by the need for multiple solver predictions to assess query difficulty. To address this, the authors propose hop-grouped relative policy optimization (HRPO). This method groups generated QA pairs by their cross-hop complexity, denoted by the number of hops h∈H, and computes advantages by standardizing the solver's reward scores over all h-hop questions. This hop-specific normalization produces low-variance advantage estimates while avoiding the computational cost of sampling multiple candidate questions per prompt. HRPO is formulated as a policy optimization objective that maximizes the log-likelihood of the generated QA pairs weighted by their relative advantages, with a KL divergence regularizer. The advantage Ai,h is calculated by standardizing the reward ri over all h-hop questions, ensuring that the proposer learns to generate questions that are both verifiable and challenging.

For solver training, the authors sample data pairs (x,y) from the proposer πθ and optimize πϕ via group relative policy optimization (GRPO). GRPO computes advantages from the empirical group statistics of the solver's predictions, reinforcing valid trajectories and refining the model's search and reasoning capabilities without requiring a separate value function. The optimization objective is driven by an outcome-based reward that evaluates the correctness of final predictions against the synthesized ground truth y. The advantages are computed via reward standardization, which normalizes the correctness of each prediction within a batch. This approach allows the solver to continuously refine its search and reasoning capabilities as it encounters increasingly complex queries from the proposer, creating a dynamic curriculum that ensures improving solver performance across diverse problem domains.
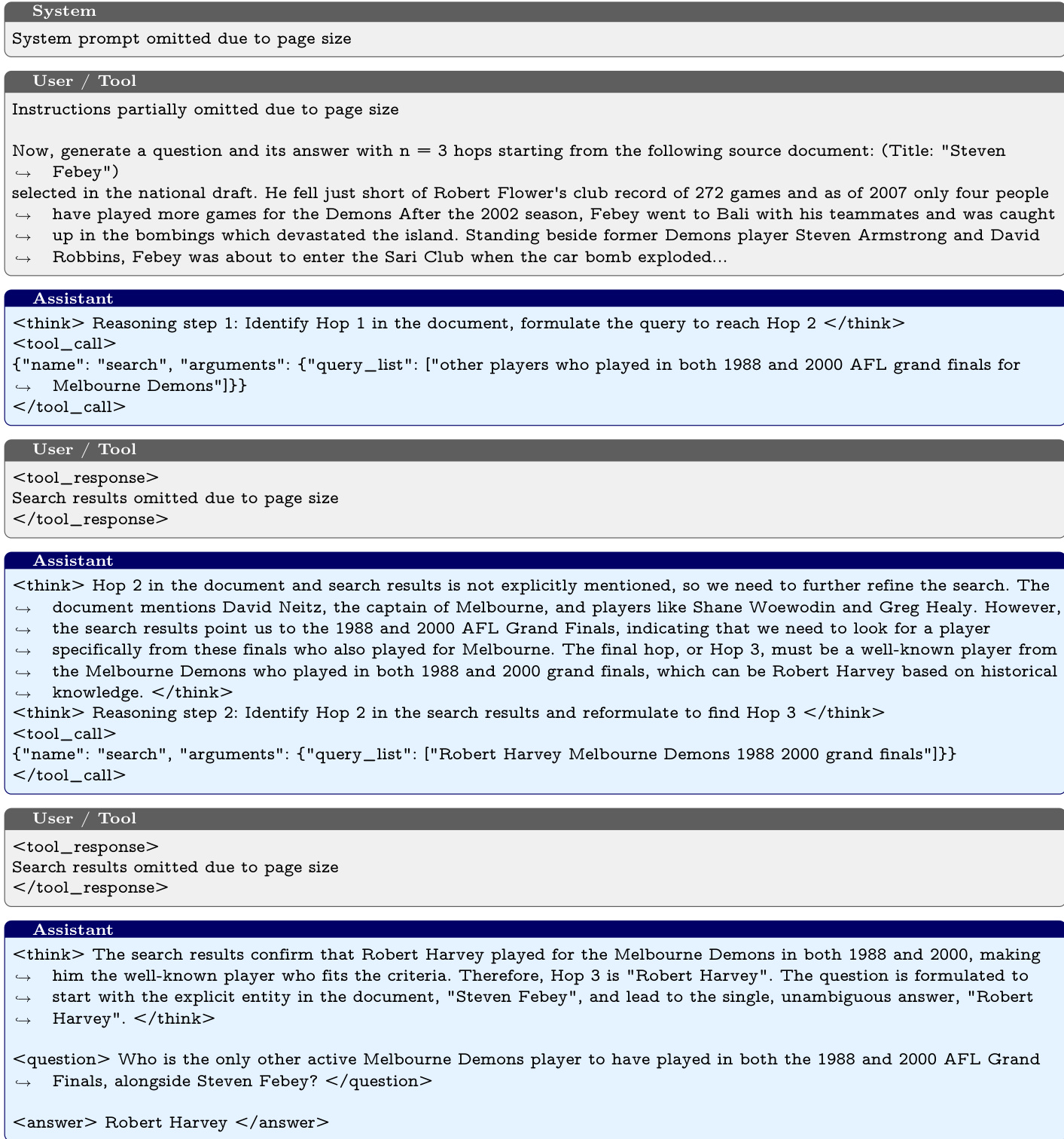
In summary, the Dr. Zero framework leverages data-free self-evolution to iteratively enhance both the proposer and solver. In each iteration, the proposer synthesizes a batch of QA pairs with heterogeneous hop structures. Utilizing solver feedback, the proposer is optimized via HRPO to produce verifiable, diverse, and challenging queries. Meanwhile, the solver leverages the generated data through GRPO to refine its search and reasoning capabilities. This alternating optimization loop creates a symbiotic feedback mechanism: as the solver improves, simple queries yield diminishing rewards, forcing the proposer to explore more complex reasoning paths to maximize its returns. Conversely, the increasingly difficult questions prevent the solver's training rewards from plateauing, allowing the solver to continuously expand its reasoning skills. Both models are initialized from the same base LLM and evolve without any training data, relying solely on the external search engine to drive their performance improvements.
Experiment
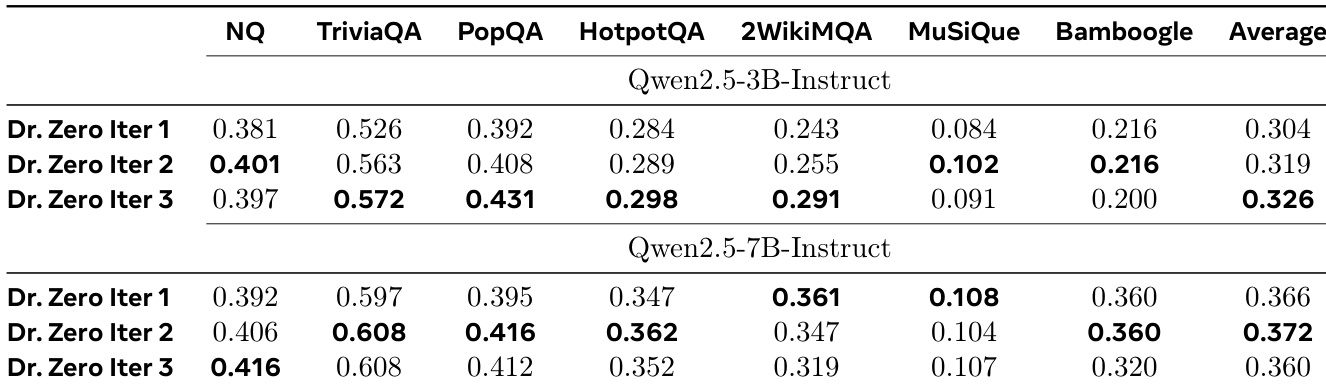
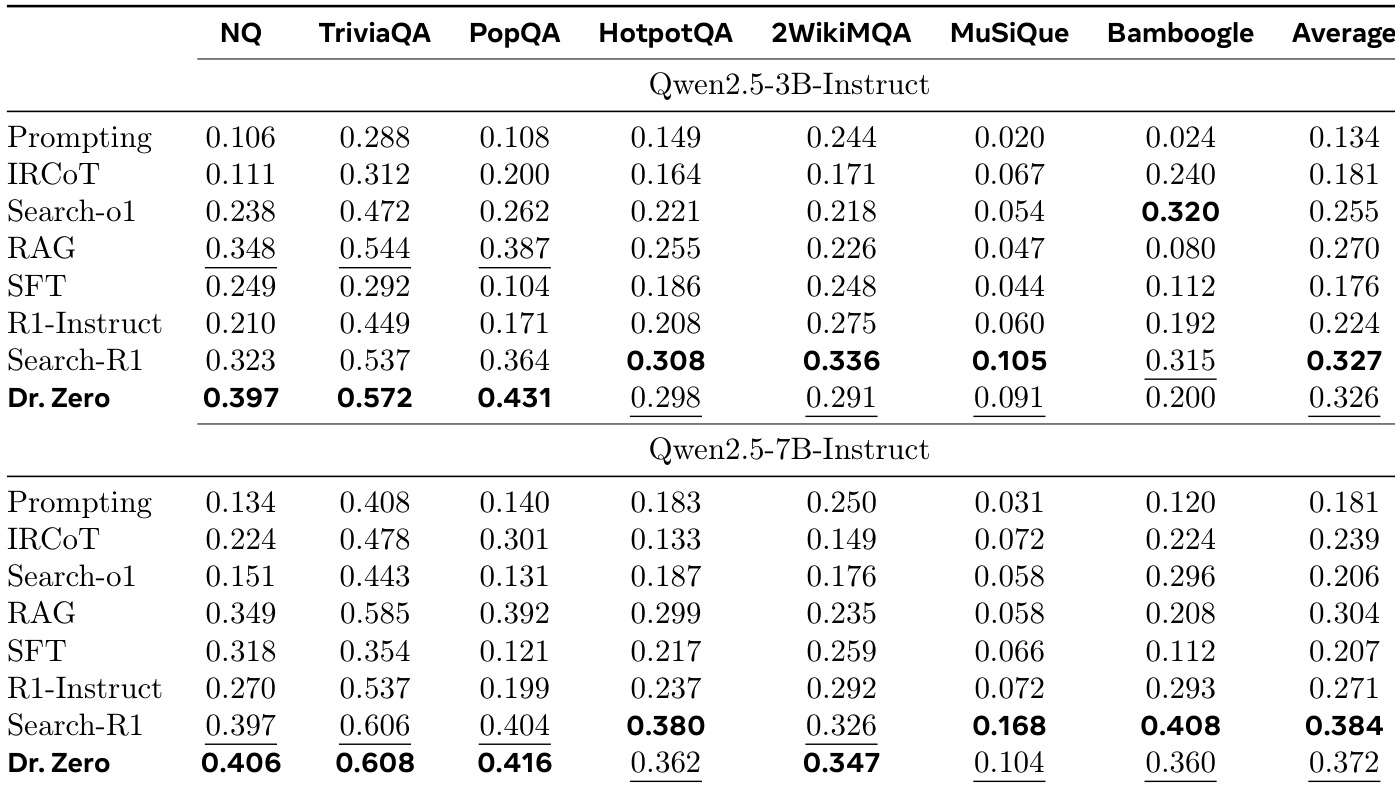
- Dr. Zero achieves state-of-the-art performance in data-free search and reasoning, outperforming supervised baselines on single-hop (NQ, TriviaQA, PopQA) and multi-hop (2WikiMQA) benchmarks without any training data. On NQ with Qwen2.5-3B, it achieves 0.397 EM, surpassing few-shot prompting (0.106), IRCoT (0.111), and Search-o1 (0.238).
- The 3B variant exceeds supervised Search-R1 by 22.9%, 6.5%, and 18.4% on NQ, TriviaQA, and PopQA, respectively; the 7B variant reaches ~90% of Search-R1’s performance and outperforms it on 2WikiMQA.
- Dr. Zero consistently surpasses data-free baselines (SQLM*, R-Zero*) by 39.9% and 27.3% on average, with an 83.3% gain on multi-hop benchmarks due to improved reward design and hop-based clustering.
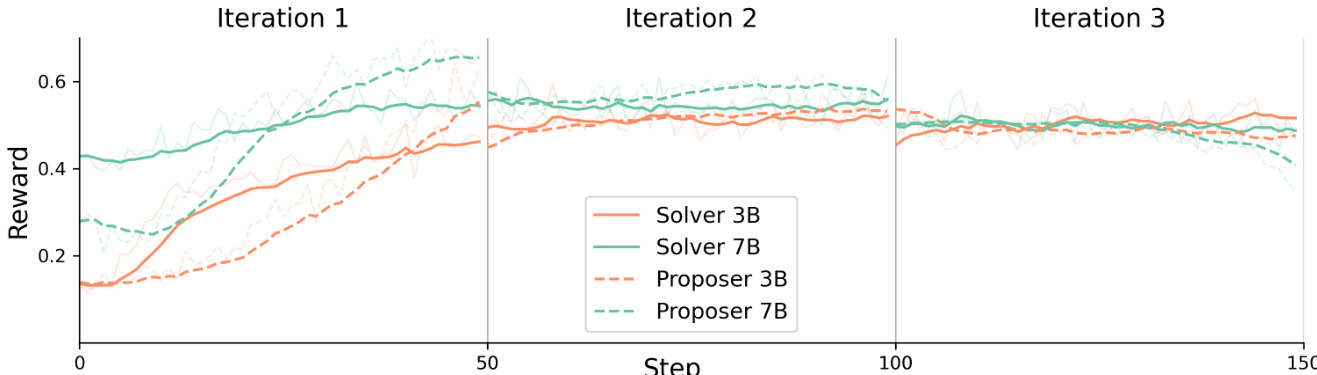
- Training dynamics show rapid performance gains within 50 steps, with the 3B model peaking after 2 iterations and the 7B model plateauing after 3 iterations, indicating efficient self-evolution with minimal training steps (150 total steps per model).
- HRPO reduces computational cost to one-fourth of GRPO while achieving higher average performance (0.326 vs. 0.320), demonstrating efficiency and effectiveness in data-free self-evolution.
- Ablation studies confirm the critical role of format and difficulty-based rewards, with removal of initial context causing a 20.7% performance drop, and longer training yielding no benefit.
- Qualitative analysis shows strong multi-hop reasoning, adaptive retrieval, and structured decomposition, though long-context generation remains a limitation, with occasional instruction deviation or truncation.
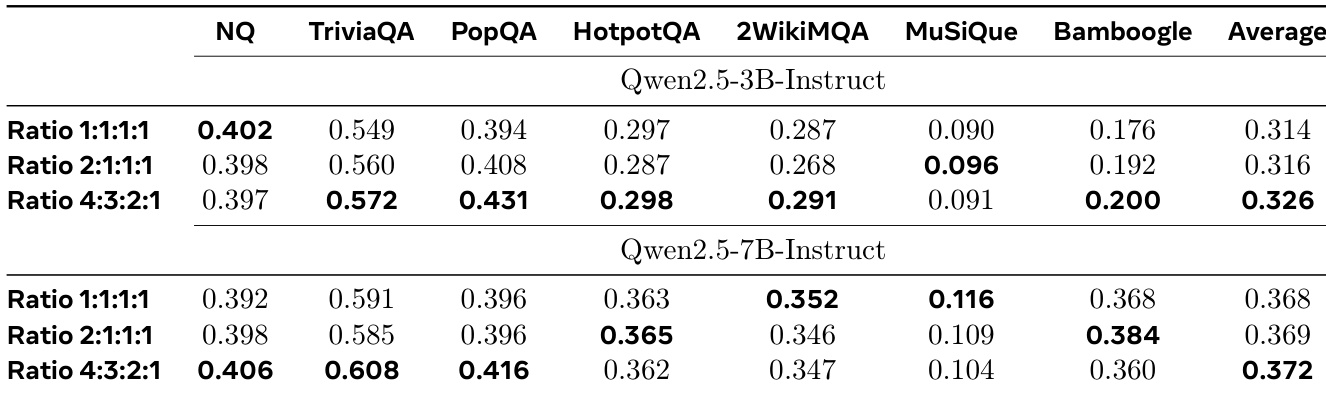
The authors investigate the impact of different hop ratios on Dr. Zero's performance, testing 1:1:1:1, 2:1:1:1, and 4:3:2:1 distributions of 1-, 2-, 3-, and 4-hop questions. Results show that the 4:3:2:1 ratio yields the highest average performance for both the 3B and 7B models, indicating that a balanced curriculum with more multi-hop questions improves overall reasoning. The 7B model benefits more from higher proportions of multi-hop data, achieving better performance on complex benchmarks compared to the 3B variant, which performs best with a more even distribution.
The authors use Dr. Zero to evaluate its performance against data-free baselines SQLM* and R-Zero* on multiple benchmarks using a 3B model. Results show that Dr. Zero achieves higher average performance than both baselines, with an average score of 0.326 compared to 0.233 for SQLM* and 0.256 for R-Zero*, demonstrating its effectiveness in generating high-quality synthetic data for search and reasoning tasks.

Results show that the reward for both the 3B and 7B solvers increases rapidly in the first iteration, reaching a peak around step 50, after which the rewards stabilize or slightly decline in subsequent iterations. The proposer rewards follow a similar trend, with the 7B proposer showing higher and more stable rewards than the 3B proposer, indicating stronger self-evolution in the larger model.
The authors use Dr. Zero to evaluate its performance on single-hop and multi-hop benchmarks, comparing it against supervised and data-free baselines. Results show that Dr. Zero achieves competitive or superior performance, with the 3B model outperforming supervised Search-R1 on single-hop tasks and the 7B variant reaching approximately 90% of Search-R1's performance on multi-hop tasks, demonstrating effective self-evolution without training data.
The authors use Dr. Zero to evaluate the impact of iterative training on model performance across multiple benchmarks. Results show that both the 3B and 7B models achieve peak performance by the second iteration, with the 7B model maintaining higher scores on multi-hop tasks, while further iterations yield only marginal improvements.