Command Palette
Search for a command to run...
LongSpeech: A Scalable Benchmark for Transcription, Translation and Understanding in Long Speech
LongSpeech: A Scalable Benchmark for Transcription, Translation and Understanding in Long Speech
Fei Yang Xuanfan Ni Renyi Yang Jiahui Geng Qing Li Chenyang Lyu Yichao Du Longyue Wang Weihua Luo Kaifu Zhang
Abstract
Recent advances in audio-language models have demonstrated remarkable success on short, segment-level speech tasks. However, real-world applications such as meeting transcription, spoken document understanding, and conversational analysis require robust models capable of processing and reasoning over long-form audio. In this work, we present LongSpeech, a large-scale and scalable benchmark specifically designed to evaluate and advance the capabilities of speech models on long-duration audio. LongSpeech comprises over 100,000 speech segments, each approximately 10 minutes long, with rich annotations for ASR, speech translation, summarization, language detection, speaker counting, content separation, and question answering. We introduce a reproducible pipeline for constructing long-form speech benchmarks from diverse sources, enabling future extensions. Our initial experiments with state-of-the-art models reveal significant performance gaps, with models often specializing in one task at the expense of others and struggling with higher-level reasoning. These findings underscore the challenging nature of our benchmark. Our benchmark will be made publicly available to the research community.
One-sentence Summary
The authors present LongSpeech, a scalable benchmark comprising over 100,000 speech segments approximately 10 minutes long annotated for transcription, translation, and understanding, alongside a reproducible construction pipeline, with initial experiments revealing significant performance gaps in state-of-the-art models regarding higher-level reasoning for real-world applications such as meeting transcription.
Key Contributions
- The work presents LongSpeech, a large-scale benchmark comprising over 100,000 speech segments approximately 10 minutes long with rich annotations for tasks like ASR and summarization. This dataset is designed to evaluate and advance the capabilities of speech models on long-duration audio across multiple domains.
- A reproducible pipeline for constructing long-form speech benchmarks from diverse sources is introduced to enable future extensions. This method facilitates the replication and expansion of the benchmark construction process for subsequent studies.
- Experiments conducted with state-of-the-art models reveal significant performance gaps, particularly in higher-level reasoning tasks such as summarization and temporal localization. These findings validate the challenging nature of the benchmark and highlight critical gaps in current models' ability to maintain context over extended audio streams.
Introduction
Advanced audio-language models face significant challenges when processing extended audio streams for real-world tasks. Existing systems often exhibit a trade-off between core functions like transcription and higher-level reasoning tasks such as summarization or temporal localization. To address these deficiencies, the authors introduce LongSpeech. This large-scale benchmark serves as a scalable evaluation platform designed to test and improve transcription, translation, and understanding capabilities in long-form speech.
Dataset
-
Dataset Composition and Sources
- The authors construct LongSpeech using over 100,000 speech segments, each approximately 10 minutes long.
- Sources include LibriSpeech, TED-LIUM v3, SPGISpeech, Vox-Populi, CommonVoice, AISHELL-2, IWSLT, and a custom movie dialogue corpus.
- These corpora cover diverse domains, speakers, and languages under research-permissive licenses.
-
Curation and Processing Details
- LibriSpeech and SPGISpeech data are grouped by speaker and chapter, concatenating sequentially to reach roughly 600 seconds.
- CommonVoice segments utilize embedding-based selection with FAISS clustering to group semantically similar content.
- VoxPopuli and AISHELL-2 prioritize supervised multi-speaker segments while filtering out short utterances.
- The movie corpus uses text-to-speech synthesis to ensure diverse speaker and gender distributions.
- Ground-truth transcriptions come from original datasets or high-quality generation models.
- Metadata for speaker counting and language detection is inferred from corpus-level annotations.
-
Model Training and Splits
- The benchmark evaluates eight tasks including ASR, translation, summarization, and question answering.
- Data is partitioned into train, dev, and test sets following a 7:1.5:1.5 ratio.
- Final splits aggregate examples from all tasks to ensure comprehensive representation.
- The total set contains 142,200 training examples, 30,100 development examples, and 30,100 test examples.
Experiment
The study evaluates multiple foundation audio-language models using standard metrics across core speech tasks and higher-level understanding benchmarks. Results reveal significant performance gaps where models demonstrate specialization in areas like translation but struggle with long-form processing and deep semantic reasoning. Notably, systems frequently parse user intent correctly yet lack the precision to extract accurate information or track temporal issues, underscoring the necessity of the LongSpeech benchmark for identifying current limitations.
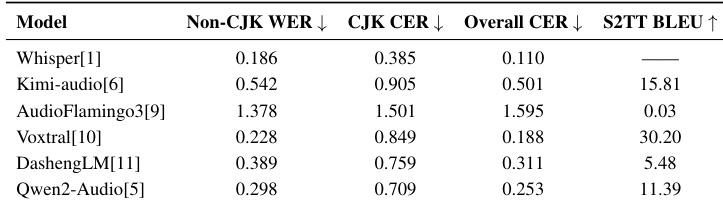
The the the table evaluates the performance of various audio-language models on speech recognition and translation tasks, revealing distinct specializations rather than uniform superiority across the board. While Whisper achieves the lowest error rates for recognition, it does not support translation, whereas Voxtral demonstrates the strongest translation capabilities. Other models like AudioFlamingo3 exhibit significantly higher error rates across both metrics compared to the specialized baselines. Voxtral delivers the strongest speech-to-text translation performance among the evaluated models. Whisper achieves the most accurate speech recognition but lacks translation functionality. AudioFlamingo3 shows the weakest performance with the highest error rates in both recognition and translation.
The authors evaluate audio-language models on tasks ranging from content separation to temporal localization, revealing significant limitations in current long-form speech processing. While models generally excel at parsing query intent, they struggle to generate accurate answers, particularly in reasoning-heavy tasks like temporal localization. Voxtral emerges as the strongest performer overall, although AudioFlamingo3 shows strength in language detection. Voxtral achieves the highest scores in emotion analysis, summarization, and temporal localization tasks. DashengLM demonstrates high parsability rates in speaker counting but fails to provide correct numeric answers. Language detection is the only task where AudioFlamingo3 outperforms the other models significantly.

These experiments evaluate audio language models on speech recognition, translation, and long form processing tasks, revealing distinct specializations rather than uniform superiority across the board. Voxtral emerges as the strongest overall performer, particularly in translation and reasoning tasks, whereas Whisper achieves the most accurate recognition but lacks translation functionality. While current models excel at parsing query intent, they exhibit significant limitations in generating accurate answers for complex reasoning, with AudioFlamingo3 showing the weakest performance despite its strength in language detection.