Command Palette
Search for a command to run...
ASTRA: Automated Synthesis of agentic Trajectories and Reinforcement Arenas
ASTRA: Automated Synthesis of agentic Trajectories and Reinforcement Arenas
Abstract
Large language models (LLMs) are increasingly used as tool-augmented agents for multi-step decision making, yet training robust tool-using agents remains challenging. Existing methods still require manual intervention, depend on non-verifiable simulated environments, rely exclusively on either supervised fine-tuning (SFT) or reinforcement learning (RL), and struggle with stable long-horizon, multi-turn learning. To address these challenges, we introduce ASTRA, a fully automated end-to-end framework for training tool-augmented language model agents via scalable data synthesis and verifiable reinforcement learning. ASTRA integrates two complementary components. First, a pipeline that leverages the static topology of tool-call graphs synthesizes diverse, structurally grounded trajectories, instilling broad and transferable tool-use competence. Second, an environment synthesis framework that captures the rich, compositional topology of human semantic reasoning converts decomposed question-answer traces into independent, code-executable, and rule-verifiable environments, enabling deterministic multi-turn RL. Based on this method, we develop a unified training methodology that integrates SFT with online RL using trajectory-level rewards to balance task completion and interaction efficiency. Experiments on multiple agentic tool-use benchmarks demonstrate that ASTRA-trained models achieve state-of-the-art performance at comparable scales, approaching closed-source systems while preserving core reasoning ability. We release the full pipelines, environments, and trained models at https://github.com/LianjiaTech/astra.
One-sentence Summary
Beike Language and Intelligence propose ASTRA, a fully automated framework for training tool-augmented LLM agents via scalable data synthesis and verifiable RL, enabling stable multi-turn learning and outperforming prior methods on agentic benchmarks while preserving core reasoning.
Key Contributions
- ASTRA introduces a fully automated framework for training tool-augmented LLM agents by synthesizing multi-turn trajectories from tool-call graph topologies and converting QA traces into rule-verifiable, code-executable environments, eliminating manual intervention and enabling deterministic reinforcement learning.
- The method combines supervised fine-tuning with online multi-turn RL using trajectory-level rewards to jointly optimize task completion and interaction efficiency, overcoming limitations of single-regime training and improving long-horizon decision-making stability.
- Evaluated on agentic benchmarks including BFCL v3, ASTRA-trained models achieve state-of-the-art performance at comparable scales, rivaling closed-source systems while maintaining core reasoning capabilities, with all pipelines and models publicly released.
Introduction
The authors leverage large language models as tool-augmented agents for multi-step decision making, a capability critical for real-world applications like data analysis and interactive systems. Prior methods suffer from reliance on non-verifiable simulated environments, fragmented single-step training, and exclusive use of either supervised fine-tuning or reinforcement learning—limiting stable, long-horizon learning and generalization. ASTRA introduces a fully automated framework that synthesizes multi-turn, structurally grounded trajectories using tool-call graphs for supervised training, and generates code-executable, rule-verifiable environments from human reasoning traces to enable deterministic, multi-turn reinforcement learning. Their unified training methodology combines SFT with online RL using trajectory-level rewards, achieving state-of-the-art performance while preserving core reasoning and enabling scalable, reproducible agent development.
Dataset

The authors use a carefully curated dataset for training and evaluating tool-using LLMs, built from heterogeneous tool documentation and synthesized user tasks. Here’s how it’s structured and processed:
-
Dataset Composition and Sources
Tool documents are collected from open MCP registries (e.g., Smithery, RapidAPI), internal specs, and public datasets. These are normalized into a unified OpenAI-style tool-calling schema and grouped by service (called “MCP servers”). Only 1,585 servers (19,036 tools across 41 domains) pass filtering for sufficient tool count, clear descriptions, and schema compatibility. -
Task Construction and Augmentation
For each server, tasks are synthesized via two modes:- Chain-conditioned: Generates tasks aligned with executable multi-step tool workflows.
- Server-only: Broadens coverage by generating tasks from server specs alone.
Augmentation expands tasks along three axes: diversity (paraphrasing), complexity (adding constraints), and persona (user style variations), while preserving language and intent. Tasks are scored on clarity, realism, and tool necessity—only those meeting all thresholds are retained.
-
SFT Dataset
Contains 54,885 multi-turn conversations (580,983 messages total), averaging 10.59 messages and 4.42 tool calls per sample. 72.2% have 1–5 tool calls. Tool responses and assistant utterances dominate (41.8% and 39.3%). Covers 6,765 unique functions across reasoning, search, and computation. -
RL Dataset
Includes 6,596 bilingual samples (71.2% English, 28.8% Chinese) spanning domains like Real Estate (15.6%), E-commerce (10.6%), and Healthcare (8.1%). Average 4.37 reasoning hops (median 4.0), with 47.8% being Parallel Multi-Hop scenarios. 91.3% of 28,794 sub-questions require tool calls; average 3.98 tool calls per sample. 44.2% of steps can be parallelized. -
Processing and Metadata
Tasks are generated via structured templates specifying domain, knowledge corpus, and hop constraints (min/max). Scenarios follow four logical structures: Single-Hop, Parallel Single-Hop, Multi-Hop, and Parallel Multi-Hop. All samples are filtered for quality, realism, and tool dependency before inclusion.
Method
The authors leverage a dual-track methodology for synthesizing tool-augmented agent training data: one for supervised fine-tuning (SFT) via trajectory generation and another for reinforcement learning (RL) via verifiable environment construction. Each track is underpinned by distinct architectural components and validation mechanisms designed to ensure realism, diversity, and executability.
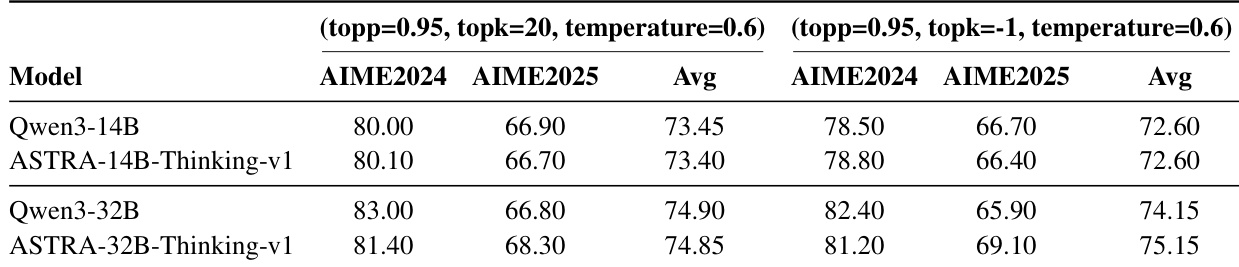
For SFT, the pipeline begins with tool document collection and normalization, followed by tool-chain synthesis and validation. As shown in the framework diagram, the process is structured into five sequential stages. Stage 1 involves filtering raw tool specifications into qualified documents by extracting function names and parameter schemas. Stage 2 constructs a directed transition graph from synthesized tool-chains, where nodes represent tools and edges denote valid consecutive invocations. Candidate chains are sampled via length-bounded random walks over this graph, biased by edge weights derived from prior synthesis frequency. Stage 3 generates task-conditioned queries paired with these chains, using an LLM to evolve plausible user intents and validate their coherence. Stage 4 executes multi-turn interactions using Qwen-Agent, integrating both real MCP servers and stateful emulators for doc-only tools. The emulator injects 20% failure rates to simulate real-world unreliability. Finally, Stage 5 applies a multi-dimensional reward model to assess trajectory quality across seven axes: query understanding, planning, tool-response context understanding, tool-response context-conditioned planning, tool call status, tool conciseness, and final answer quality. These scores are averaged into a single scalar reward for SFT signal generation.
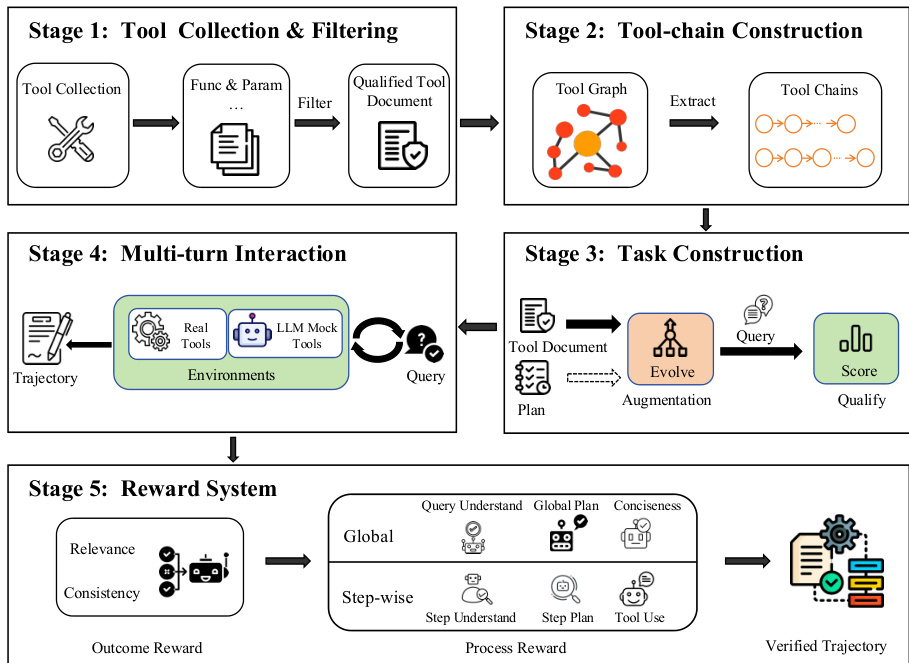
For RL, the authors adopt a QA-based environment synthesis framework that models multi-turn tool use as navigation over a latent semantic topology. As illustrated in the figure below, the pipeline comprises four stages: Q-A instance synthesis, quality validation, environment synthesis, and sub-environment merging. In Stage 1, the system generates a main question q0 and its answer a0, along with a set of intermediate sub-questions S={(qi,ai)}i=1m that form a dependency graph G, such that a0=Φ({ai},G). Synthesis is conditioned on a knowledge source K and a hop budget H, operating in either question-conditional or unconditional mode. Stage 2 validates each decomposed instance across four dimensions: dependency consistency (ensuring each sub-question’s dependencies are logically necessary), sub-question atomicity (verifying indivisibility), sequential rationality (checking execution order validity), and task completeness (confirming sufficiency to solve q0). The overall quality score QS(τ) is the mean of these four binary indicators. Stage 3 synthesizes executable sub-environments for each non-leaf sub-task node by generating tool specifications, augmenting their complexity, and implementing Python-based tool code validated in a sandbox. Stage 4 merges functionally equivalent sub-environments by identifying homogeneous sub-questions and expanding their underlying data structures to support multiple parameter variants while preserving correctness.
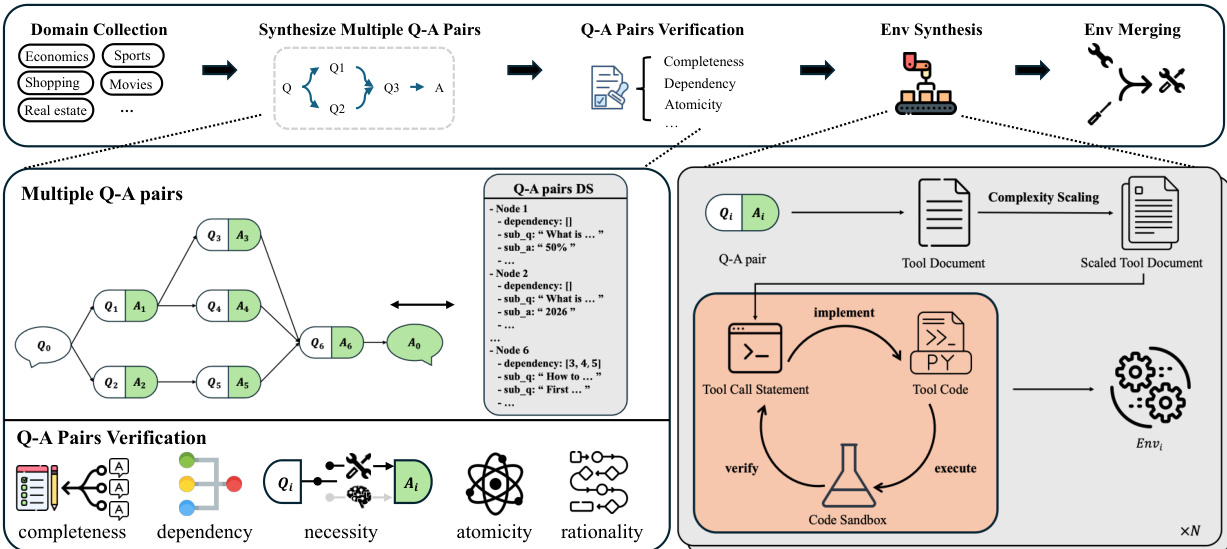
The RL training infrastructure implements an online, multi-turn agentic paradigm. At each step, the policy model generates a tool invocation statement, which is executed in a code sandbox alongside its corresponding tool implementation. The sandbox returns the tool output, which is fed back as an observation to condition subsequent decisions. The interaction terminates upon reaching a maximum turn limit, sequence length, or when the model ceases tool calls. The resulting trajectory is used for policy optimization via a modified GRPO objective that omits KL and entropy terms for stability. To mitigate training instability from degenerate reward variance, the authors introduce Adaptive Batch Filling: a strategy that maintains a buffer of valid rollouts (those with non-zero reward variance) and selects the first n valid samples for each optimization step, ensuring dense gradient signals. The reward function is F1-style, defined as the harmonic mean of sub-task recall r=n^/n and tool usage precision p=n^/(c+ϵ), where n^ is the number of solved sub-tasks and c is the total tool calls. This design incentivizes both task completion and interaction efficiency.
To enhance robustness, the authors augment each training instance with task-irrelevant tools sampled from three semantic similarity bands (high, medium, low) derived from cosine similarity of tool documentation embeddings. This encourages the model to discriminate relevant tools rather than overfit to minimal sets. Training operates in a strictly online setting with batch size 256, fixed learning rate 2×10−6, and long-context support (25,600-token prompts, 49,152-token responses) to accommodate multi-turn interactions.
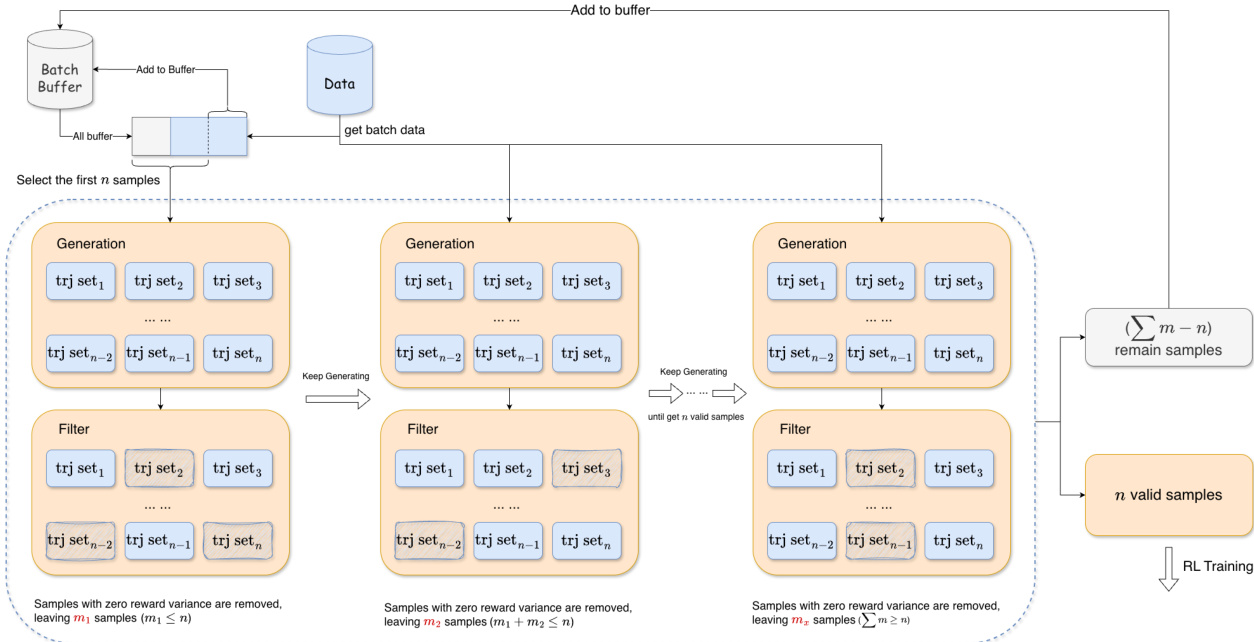
The SFT infrastructure employs a modified checkpointing strategy in HuggingFace Transformers to reduce I/O and storage overhead: model weights are saved at high frequency, while training-state checkpoints (optimizer, scheduler) are retained only for the most recent 1–2 saves. This preserves fine-grained observability for analysis without compromising scalability.
Experiment
- Trained Qwen3-14B and Qwen3-32B via SFT and RL with context parallelism to handle long sequences; used cosine learning rate schedules with warmup.
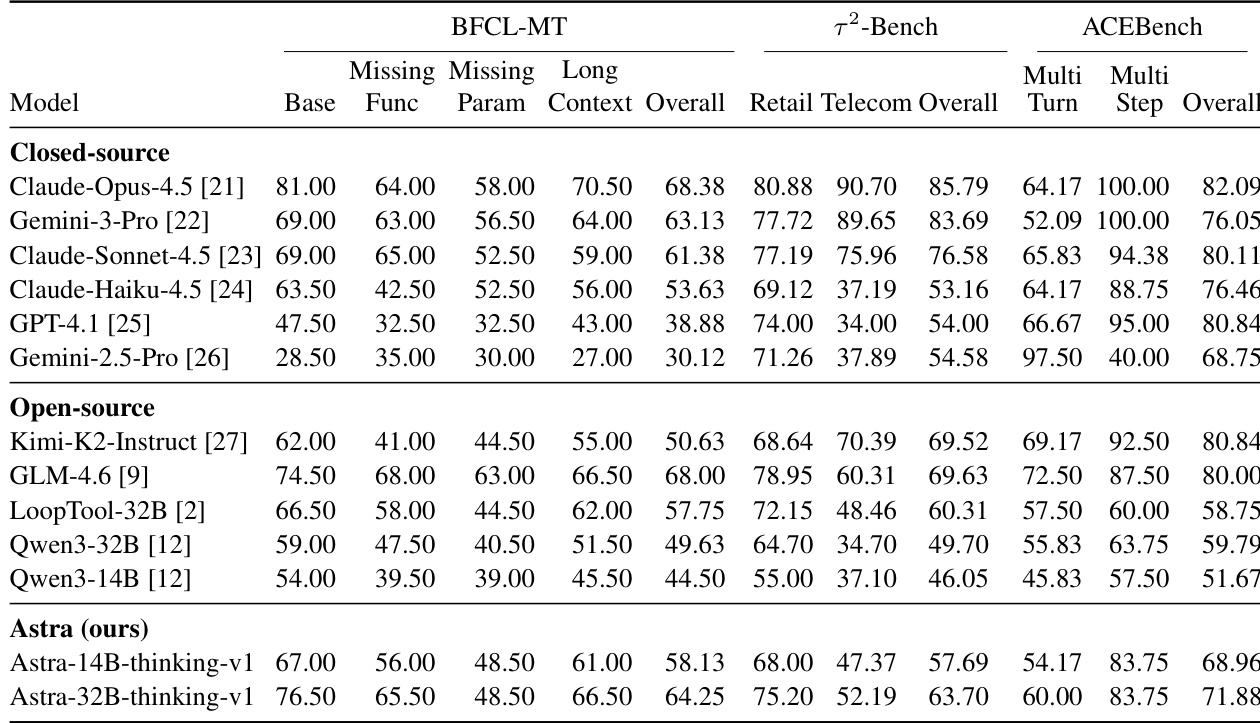
- Evaluated on agentic benchmarks (BFCL-MT, τ²-Bench, ACEBench) requiring multi-turn tool use and user simulation, plus non-agentic math benchmarks (AIME2024/2025) to assess core reasoning.
- Achieved state-of-the-art or competitive results across model scales; RL stage delivered the largest performance gains over SFT and original models.
- Irrelevant tool mixing during RL improved tool discrimination by forcing the model to reject incorrect options, with balanced similarity coverage yielding best results.
- F1-style reward (balancing recall and precision) stabilized training and prevented extremes of tool overuse or underuse; recall-only and precision-only rewards led to training collapse.
- SFT improved structured tool use and state tracking; RL enabled broader exploration via sub-QA supervision, supporting recovery from suboptimal decisions.
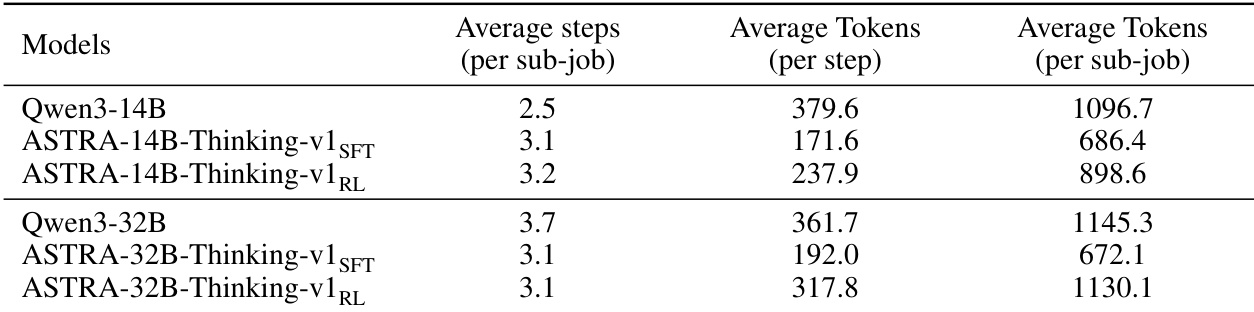
- Output length decreased after SFT, then increased moderately after RL; interaction steps remained stable across stages, indicating performance gains were not due to length changes.
- Method preserved strong reasoning on non-agentic tasks while enhancing agentic tool-use capability.
The authors use a two-stage training approach—supervised fine-tuning followed by reinforcement learning—to enhance tool-use capabilities in Qwen3 models, with RL delivering the largest performance gains across agentic benchmarks. Results show consistent improvements in multi-turn tool interaction and task completion, while maintaining strong performance on non-agenetic reasoning tasks. The final RL-trained models outperform both their base and SFT counterparts, achieving state-of-the-art or competitive results relative to larger open-source and closed-source models.
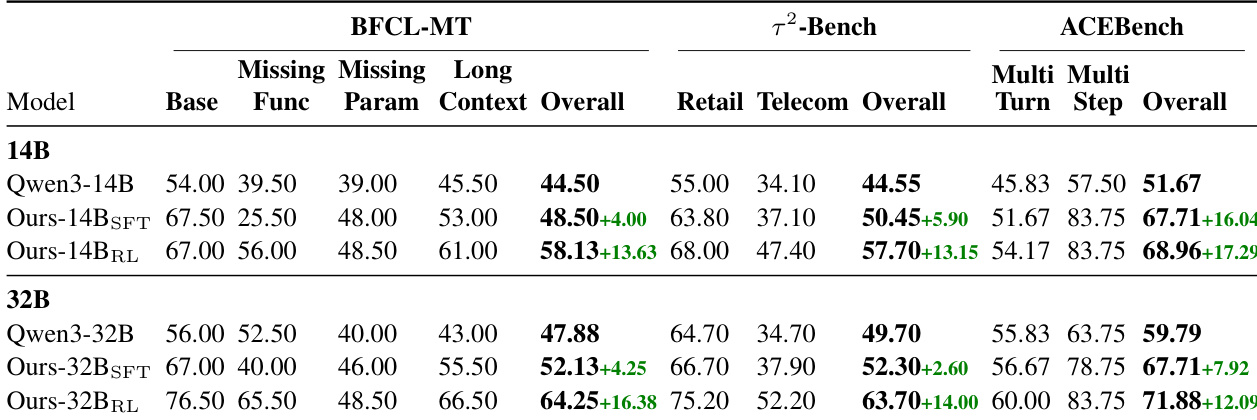
The authors observe that while fine-tuning stages do not significantly alter the average number of interaction steps per subtask, they substantially reduce token usage per step, with the RL stage producing outputs of intermediate length between the original and SFT models. This suggests that performance gains stem from more efficient reasoning and tool-use patterns rather than changes in dialogue depth. The RL-trained models maintain higher token efficiency per subtask compared to the base models, indicating improved conciseness without sacrificing task coverage.
The authors use a two-stage training approach combining supervised fine-tuning and reinforcement learning to enhance agentic tool-use capabilities in Qwen3 models. Results show that their method achieves state-of-the-art performance on multi-turn tool-use benchmarks at matched parameter scales, with reinforcement learning delivering the largest performance gains. The approach also maintains strong performance on non-agenetic reasoning tasks, indicating that tool-use optimization does not compromise core reasoning ability.
The authors evaluate their ASTRA models on non-agenetic mathematical reasoning benchmarks AIME2024 and AIME2025 under two decoding settings, showing that performance remains stable or slightly improves after training, with no significant degradation despite the focus on agentic tool use. Results indicate that the 32B variant consistently outperforms the 14B variant, and both ASTRA versions maintain competitive scores across both decoding configurations.