Command Palette
Search for a command to run...
SoMA: A Real-to-Sim Neural Simulator for Robotic Soft-body Manipulation
SoMA: A Real-to-Sim Neural Simulator for Robotic Soft-body Manipulation
Mu Huang Hui Wang Kerui Ren Linning Xu Yunsong Zhou Mulin Yu Bo Dai Jiangmiao Pang
Abstract
Simulating deformable objects under rich interactions remains a fundamental challenge for real-to-sim robot manipulation, with dynamics jointly driven by environmental effects and robot actions. Existing simulators rely on predefined physics or data-driven dynamics without robot-conditioned control, limiting accuracy, stability, and generalization. This paper presents SoMA, a 3D Gaussian Splat simulator for soft-body manipulation. SoMA couples deformable dynamics, environmental forces, and robot joint actions in a unified latent neural space for end-to-end real-to-sim simulation. Modeling interactions over learned Gaussian splats enables controllable, stable long-horizon manipulation and generalization beyond observed trajectories without predefined physical models. SoMA improves resimulation accuracy and generalization on real-world robot manipulation by 20%, enabling stable simulation of complex tasks such as long-horizon cloth folding.
One-sentence Summary
Researchers from multiple institutions propose SoMA, a Gaussian Splat-based neural simulator that unifies deformable dynamics and robot actions for stable, long-horizon real-to-sim manipulation, outperforming prior methods by 20% in accuracy and generalization for tasks like cloth folding.
Key Contributions
- SoMA introduces a novel real-to-sim neural simulator for soft-body manipulation that operates on 3D Gaussian splats, unifying deformable dynamics, environmental forces, and robot joint actions in a latent space to enable stable, long-horizon simulation without predefined physics models.
- It proposes robot-conditioned dynamics modeling and force-driven updates on Gaussian splats to ensure kinematically and physically consistent interactions, even under partial occlusion, combined with multi-resolution training and blended supervision to maintain stability over extended manipulation sequences.
- Evaluated on real-world benchmarks, SoMA achieves a 20% improvement in resimulation accuracy and generalization over prior methods, enabling reliable simulation of complex tasks like cloth folding under both seen and unseen robot actions.
Introduction
The authors leverage Gaussian splat representations to build SoMA, a neural simulator that enables real-to-sim soft-body manipulation by learning deformable dynamics directly from multi-view RGB videos and robot joint actions. Prior simulators either rely on rigid physics models that are hard to calibrate from visual data or neural models that lack robot-conditioned interaction and drift during long-horizon tasks. SoMA overcomes these limitations by modeling force-driven dynamics on splats, anchoring simulations to real robot kinematics, and using multi-resolution training with blended supervision to maintain stability and generalization — achieving 20% higher accuracy in resimulation and enabling complex tasks like cloth folding under unseen manipulations.
Dataset
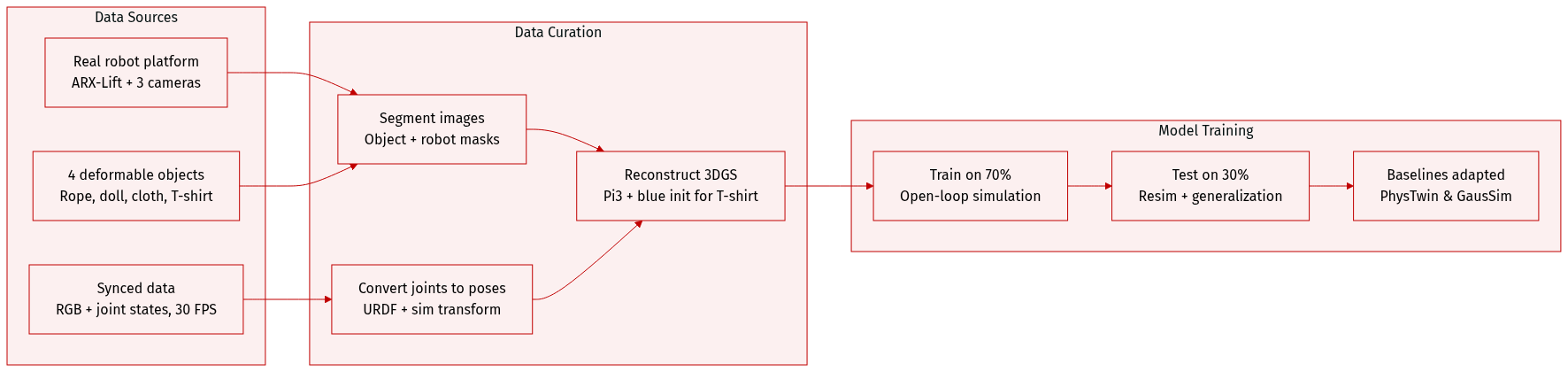
-
The authors collect real-world robot manipulation data on an ARX-Lift platform, featuring four deformable objects: rope, doll, cloth, and T-shirt. Each object has 30–40 sequences, with 100–150 frames per sequence, captured at 640×480 resolution and 30 FPS alongside synchronized robot joint states. Datasets are split 7:3 into training and test sets.
-
Data is captured using three Intel RealSense D405 cameras: one mounted on the robot end-effector for robot-conditioned mapping, and two fixed around the tabletop for multi-view coverage. All images are segmented using GroundingDINO and Grounded-SAM2 to generate object masks (for supervision) and robot masks (to identify occlusions).
-
Robot joint states are converted into end-effector poses and gripper parameters using a URDF model, then mapped into a unified simulation coordinate system via a learned robot-to-sim transformation. This transformation is derived from known camera poses in both robot and reconstruction frames using Pi3 for camera pose estimation and 3D point cloud reconstruction.
-
The reconstructed point clouds are converted into 3D Gaussian Splatting (3DGS) representations. For T-shirt sequences, splat colors are initialized to blue to maintain consistent appearance for occluded or weakly observed regions.
-
The authors train models using the training split, with no explicit mixture ratios mentioned. During evaluation, models are initialized with reconstructed Gaussian splats and perform open-loop simulation conditioned on per-frame robot actions. Baselines like PhysTwin and GausSim are adapted: PhysTwin uses a circular control point for interaction, while GausSim operates autoregressively without explicit control inputs, using initial splat states for rollout prediction.
Method
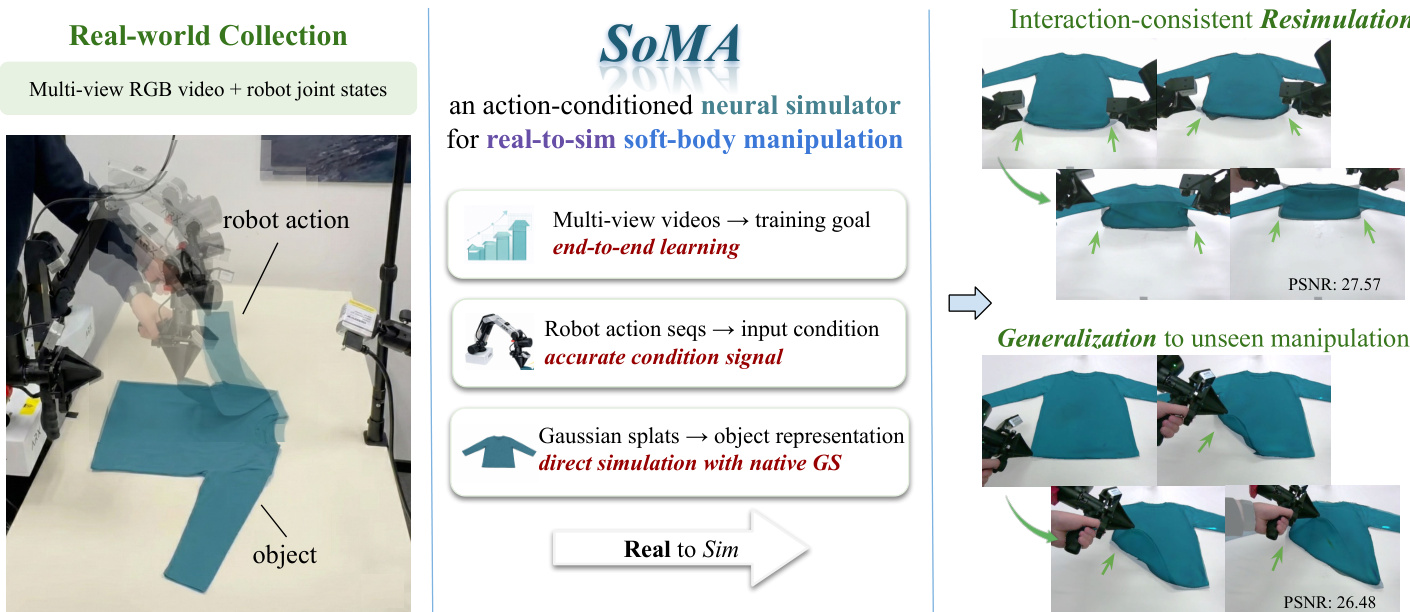
The authors leverage a unified neural simulation framework called SoMA to model deformable object dynamics under robot manipulation, directly conditioned on robot joint-space actions and multi-view visual observations. The architecture integrates real-world perception, hierarchical physical simulation, and multi-resolution training to enable stable, long-horizon resimulation and generalization to unseen interactions.
At the core of SoMA is a scene-to-simulation mapping that aligns heterogeneous coordinate systems—robot kinematics, camera poses, and reconstructed object geometry—into a shared physical space. The initial object state is reconstructed as a set of Gaussian splats (GS) from multi-view RGB images, with robot end-effector poses transformed into the simulation frame via a learned similarity transformation that enforces metric and gravitational consistency. This unified initialization ensures that robot actions, such as gripper state and end-effector pose, can directly drive object dynamics without decoupling control from geometry.
Refer to the framework diagram, which illustrates the end-to-end pipeline: real-world multi-view video and robot joint states are mapped into a simulation space where Gaussian splats serve as the native object representation. The simulator then predicts future states Gt=ϕθ(Gt−1,Gt−2,Rt) conditioned on robot actions, and renders the predicted state under known camera poses to compute image reconstruction loss. This closed-loop training enables direct supervision from visual observations while preserving physical plausibility.
The dynamics model operates on a hierarchical graph of Gaussian splats, where nodes at coarser levels represent aggregated local structures. Dynamics are propagated top-down: each cluster node predicts latent motion and deformation states, which are then transferred to child nodes via learned affine transformations Fki. This hierarchical structure enables global coherence while preserving local detail, as expressed in the state propagation equations:
x^kh−1=x^chh+j=h∏LFkj(Xk−Xch), Σ^kh−1=(i=h∏LFki)Σk(i=h∏LFki)⊤.Crucially, SoMA models object dynamics as force-driven rather than state-only. Interaction forces—environmental (gravity and support) and robot-induced—are computed at the GS level and aggregated hierarchically. Robot forces are predicted via a graph-based interaction module Φθ that considers neighboring robot control points and gripper state. The total force fi=fienv+firob is fed into a hierarchical dynamics predictor ψθ that outputs linear and angular velocities for each node:
(vi,ωi)=ψθ(git−1,git−2,fi).To stabilize long-horizon simulation, the authors adopt a multi-resolution training strategy. Temporally, the model is first trained with coarse frame gaps to capture motion patterns, then fine-tuned at native resolution using randomly sampled subsequences. Spatially, dynamics are trained at original image resolution while geometry is reconstructed from super-resolved images to preserve detail. This dual-resolution approach mitigates error accumulation and reduces computational cost.
As shown in the figure below, the training pipeline integrates occlusion-aware image supervision and physics-inspired momentum consistency. Image loss is masked to visible regions using object masks Mt, combining L2 and D-SSIM terms:
Limg(t)=λMt⊙(I^t−It)22+(1−λ)LD−SSIM(Mt⊙I^t,Mt⊙It).For occluded regions lacking visual feedback, momentum consistency regularization enforces physical plausibility across hierarchy levels:
Lmom=l=1∑L−1mclx^cl−i∈Cl−1∑mix^iO2.This blended supervision ensures stable, interaction-aware simulation even under partial observability.
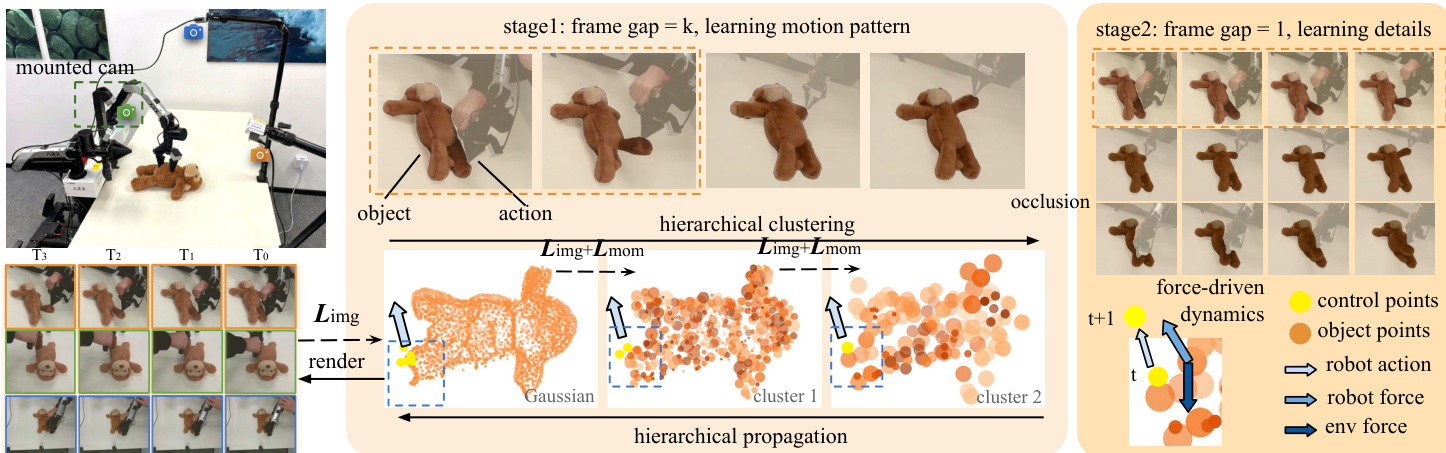
Together, these components form a cohesive simulation pipeline that enables accurate resimulation of training trajectories and generalization to novel robot actions and contact configurations, as demonstrated across diverse soft-body objects including ropes, cloths, and volumetric toys.
Experiment
- Successfully simulates deformable objects (cloth, rope, doll) under diverse manipulations, maintaining stable dynamics and accurate visual reconstructions over long horizons.
- Generalizes well to unseen actions and contact configurations, outperforming state-based and physics-based baselines that degrade under novel interactions.
- Handles complex, long-horizon tasks like T-shirt folding with large deformations and self-contacts, preserving coherent geometry where other methods fail.
- Ablation studies confirm key components—blended supervision, multi-resolution training, and joint domain training—are critical for stability and generalization.
- Demonstrates cross-setting applicability, including hand-driven motion from PhysTwin datasets, showing robustness beyond robot-action conditioning.
- Enables practical simulation for embodied manipulation, supporting policy development and reducing reality gap for real-world transfer.
The authors evaluate SoMA against PhysTwin on image and depth metrics, showing SoMA achieves superior performance across all measures. Results indicate SoMA produces more accurate visual reconstructions and geometric consistency, particularly under complex robot-object interactions. This demonstrates its robustness in real-to-sim simulation compared to physics-based differentiable simulators.

The authors evaluate the impact of multi-resolution temporal training by varying the frame subsampling interval k, finding that performance remains stable across tested values. Results show that PSNR peaks at k=10 and k=15, while RMSE stays consistently low, indicating the training strategy is robust to moderate changes in temporal resolution. This supports the use of coarse-to-fine training for stabilizing long-horizon simulation without requiring precise tuning of the subsampling rate.

The authors use SoMA to simulate deformable objects under robot manipulation, showing it outperforms PhysTwin across all image-based metrics including PSNR, SSIM, and LPIPS. Results show SoMA maintains higher visual fidelity and structural consistency, particularly for rope, cloth, and doll objects, indicating stronger generalization and stability in resimulation tasks.

The authors evaluate ablation variants of their model on cloth resimulation and generalization tasks, finding that the full model achieves the highest resimulation accuracy while joint training improves generalization. Removing multi-resolution training or blended supervision degrades performance, with the image-only variant showing the largest drop, especially in generalization. These results highlight the importance of multi-resolution training and physics-informed supervision for stable, transferable deformable object simulation.

The authors use SoMA to simulate deformable objects under robot manipulation, showing it outperforms PhysTwin and GausSim in both resimulation and generalization tasks across image and depth metrics. Results show SoMA maintains stable, accurate dynamics over long horizons and adapts well to unseen actions, while baselines exhibit increasing error or structural collapse. The method’s robustness stems from its interaction-aware design and multi-resolution training, enabling reliable simulation even under complex, self-contact-heavy scenarios.
