Command Palette
Search for a command to run...
OPUS: Towards Efficient and Principled Data Selection in Large Language Model Pre-training in Every Iteration
OPUS: Towards Efficient and Principled Data Selection in Large Language Model Pre-training in Every Iteration
Abstract
As high-quality public text approaches exhaustion, a phenomenon known as the Data Wall, pre-training is shifting from more tokens to better tokens. However, existing methods either rely on heuristic static filters that ignore training dynamics, or use dynamic yet optimizer-agnostic criteria based on raw gradients. We propose OPUS (Optimizer-induced Projected Utility Selection), a dynamic data selection framework that defines utility in the optimizer-induced update space. OPUS scores candidates by projecting their effective updates, shaped by modern optimizers, onto a target direction derived from a stable, in-distribution proxy. To ensure scalability, we employ Ghost technique with CountSketch for computational efficiency, and Boltzmann sampling for data diversity, incurring only 4.7% additional compute overhead. OPUS achieves remarkable results across diverse corpora, quality tiers, optimizers, and model scales. In pre-training of GPT-2 Large/XL on FineWeb and FineWeb-Edu with 30B tokens, OPUS outperforms industrial-level baselines and even full 200B-token training. Moreover, when combined with industrial-level static filters, OPUS further improves pre-training efficiency, even with lower-quality data. Furthermore, in continued pre-training of Qwen3-8B-Base on SciencePedia, OPUS achieves superior performance using only 0.5B tokens compared to full training with 3B tokens, demonstrating significant data efficiency gains in specialized domains.
One-sentence Summary
Researchers from EPIC Lab, Qwen Team, UW-Madison, UIUC, and Mila propose OPUS, a dynamic data selection method that projects optimizer-shaped updates onto stable directions, boosting efficiency 8× and accuracy 2.2% over random selection, especially effective for specialized domains like SciencePedia with minimal tokens.
Key Contributions
- OPUS introduces an optimizer-aware utility metric for dynamic data selection, scoring tokens based on their projected impact in the actual update space of adaptive optimizers like AdamW and Muon, addressing the misalignment between gradient-based scoring and modern training dynamics.
- The method employs a stable, in-distribution proxy (BENCH-PROXY) derived from the training corpus and scales efficiently via Ghost technique with CountSketch projections, adding only 4.7% compute overhead while preserving data diversity through Boltzmann sampling.
- Empirically, OPUS outperforms industrial baselines in pre-training GPT-2 Large/XL on FineWeb datasets using 30B tokens (vs 200B) and achieves superior results in continued pre-training of Qwen3-8B-Base on SciencePedia with just 0.5B tokens (vs 3B), demonstrating significant data efficiency across model scales and domains.
Introduction
The authors leverage the growing scarcity of high-quality pre-training data to reframe data selection as an optimizer-aware, dynamic process rather than a static preprocessing step. Prior methods either rely on fixed quality heuristics that ignore model evolution or score samples in raw gradient space, misaligned with modern adaptive optimizers like AdamW and Muon that reshape update directions. OPUS introduces optimizer-induced utility—a principled, scalable framework that scores data based on how effectively each sample moves parameters under the actual optimizer geometry, using efficient projections and a stable in-distribution proxy. It further preserves diversity via Boltzmann sampling and achieves empirical gains over static filters and prior dynamic selectors across multiple LLMs and datasets.
Dataset
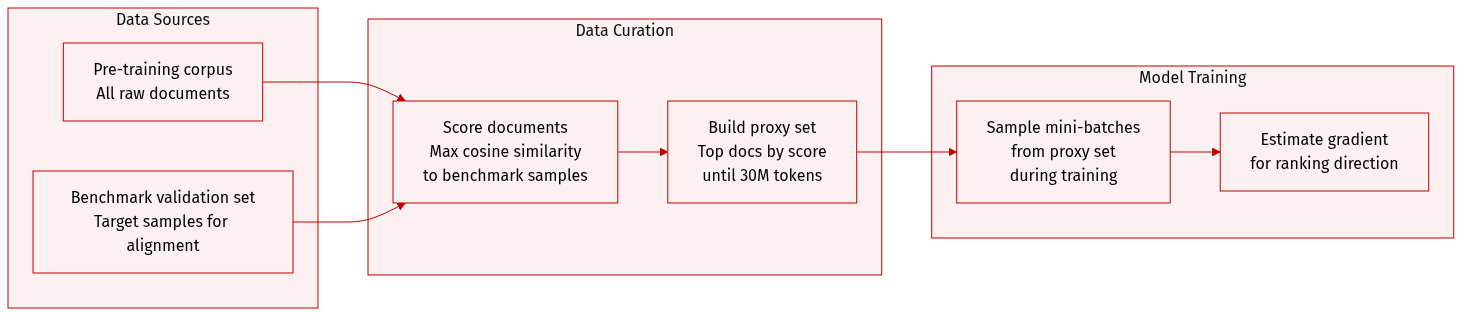
- The authors construct BENCH-PROXY, a small proxy dataset sampled from the pre-training corpus to approximate the target benchmark’s distribution, enabling efficient gradient computation during training.
- They compute benchmark relevance scores for each pre-training document using cosine similarity between embeddings from Arctic-Embed-L v2 (Yu et al., 2024a) — comparing each document to all benchmark validation samples and taking the max similarity per document.
- The proxy set 𝒟_proxy is built by sorting documents by relevance score and greedily selecting top-scoring ones until reaching a 30M-token budget, ensuring compactness and distributional alignment.
- During training, mini-batches are repeatedly sampled from 𝒟_proxy to estimate the gradient direction for within-step ranking, maintaining stable, low-variance scoring while steering toward benchmark-aligned data.
Method
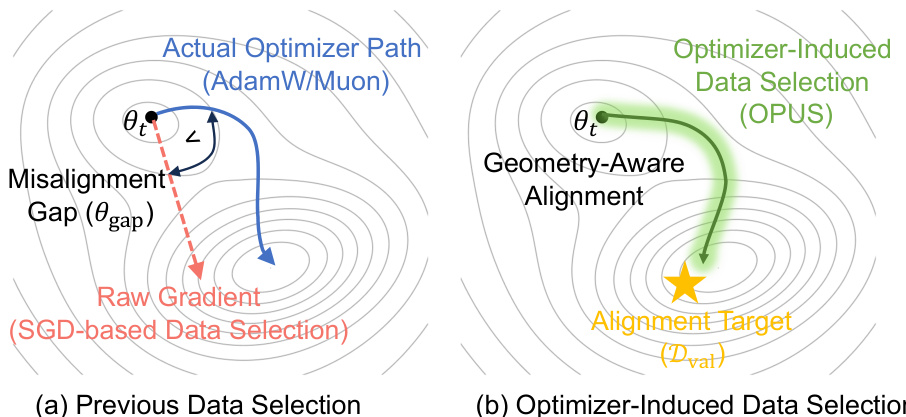
The authors leverage OPUS, a dynamic data selection framework that operates within the optimizer-induced update geometry to prioritize training samples that maximally reduce validation loss under the actual trajectory of modern optimizers. Unlike prior methods that score candidates using raw gradients—implicitly assuming an SGD-like update space—OPUS explicitly accounts for the state-dependent preconditioning applied by optimizers such as AdamW and Muon. This is critical because modern optimizers reshape gradient directions via momentum, adaptive scaling, or matrix orthogonalization, thereby altering the effective update path. As shown in the figure below, OPUS aligns selection with the actual optimizer-induced path (green curve), avoiding the misalignment gap (red dashed arrow) that arises when using raw-gradient-based selection (blue curve) under non-SGD optimizers.
At each training step t, OPUS receives a candidate buffer Bt and selects a subset Bt of size K=⌊ρN⌋ to form the update batch. The selection is guided by a utility function derived from the expected reduction in validation loss after one optimizer step. Specifically, the marginal utility of adding a candidate z to the current selected subset Bt is approximated as:
Uz(t)≈ηt⟨uz(t),gproxy(t)⟩−ηt2⟨uz(t),G(t)⟩,where uz(t)=Pt∇θL(z;θt) is the optimizer-induced effective update for sample z, gproxy(t) is the proxy gradient estimated from a stable, in-distribution validation proxy pool Dproxy, and G(t)=∑zj∈Btuzj(t) is the accumulated effective direction of already selected samples. The first term encourages alignment with the proxy target direction, while the second term penalizes redundancy by discouraging selection of samples whose updates are geometrically aligned with those already chosen.
To construct the proxy direction, OPUS employs BENCH-Proxy: a retrieval-based method that embeds both benchmark validation data and pre-training documents using a frozen text encoder, then selects the top-M most similar pre-training documents to form Dproxy. This ensures the proxy remains within the pre-training manifold while being aligned with downstream task distributions, yielding a stable and task-relevant gradient signal.
To scale this utility computation to LLM-sized models, OPUS avoids materializing full per-sample gradients by leveraging the ghost technique. For each linear layer r, the per-sample gradient ∇WrL(z;θt) is factorized into the outer product of input activation ar(z) and output gradient br(z). The optimizer-induced effective update Pt,r(ar(z)⊗br(z)) is then projected into a low-dimensional space Rm using a CountSketch operator Πr, enabling efficient inner product computation without materializing the full gradient. For diagonal preconditioners (e.g., AdamW), this projection is interleaved with preconditioning, preserving computational efficiency at O(din+dout) per layer. For dense preconditioners (e.g., Muon), the cost increases to O(dindout), but remains tractable due to the sketch dimension m≪d.
Finally, to maintain data diversity and avoid overfitting to transient proxy noise, OPUS replaces deterministic greedy selection with Boltzmann sampling. Each candidate z is sampled with probability proportional to exp(Uz(t)/τ), where τ>0 is a temperature hyperparameter. This stochastic selection ensures high-utility samples are favored while preserving non-zero probability for complementary candidates, enhancing robustness to estimation noise and non-stationarity in the data stream.
Refer to the framework diagram for a complete overview of the OPUS pipeline, which integrates proxy construction, efficient gradient projection, iterative utility estimation, and diversity-preserving sampling within a single training loop.
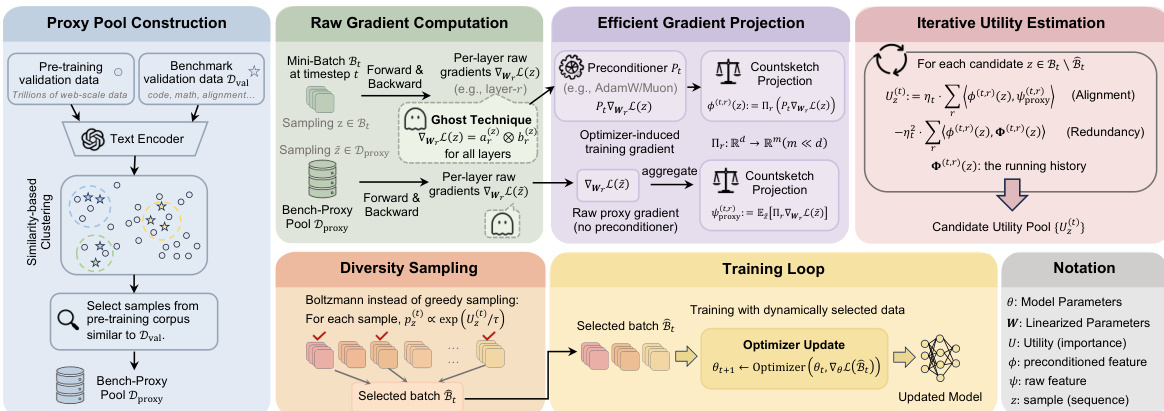
The entire process is executed iteratively: at each step, OPUS computes the optimizer-induced preconditioner Pt, generates per-layer sketches for both proxy and candidate samples, estimates marginal utilities in the projected space, samples the next batch via Boltzmann distribution, and updates the model using the selected subset. This ensures that every training step is informed by the optimizer’s actual geometry, the proxy’s task-relevant direction, and the diversity of the selected data.
Experiment
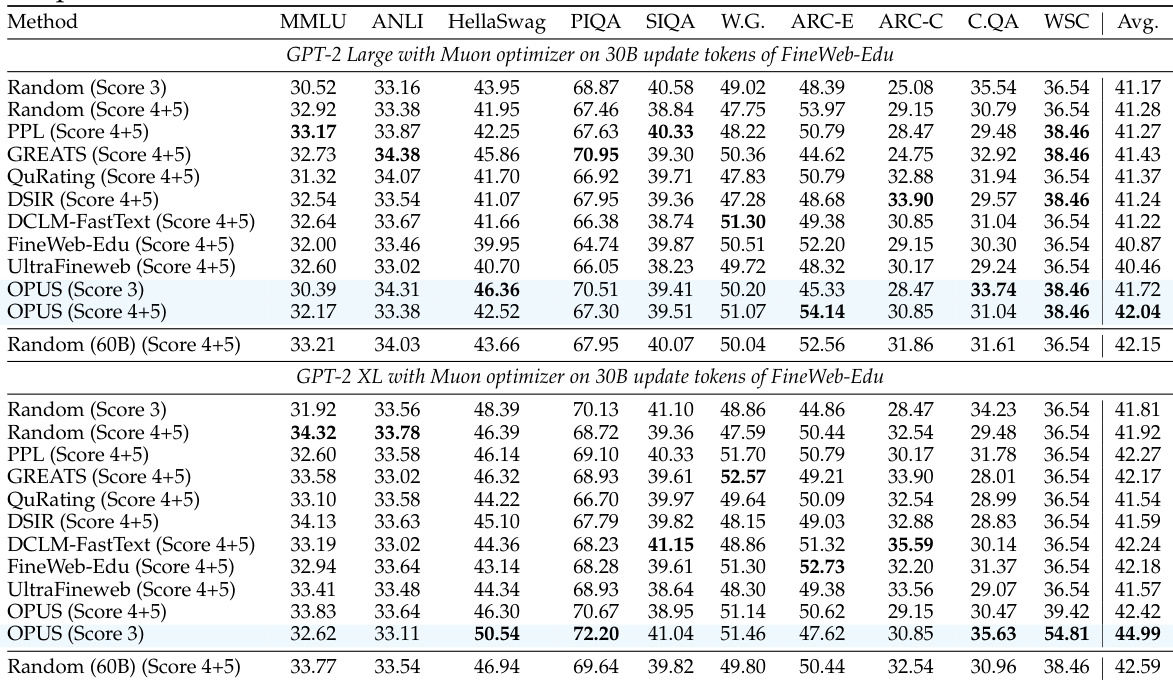
- OPUS significantly improves pre-training efficiency, achieving 2.2% average accuracy gain across 10 benchmarks and 8x compute reduction versus random selection on GPT-XL using FineWeb.
- It outperforms static and dynamic baselines even when selecting from lower-quality data (FineWeb-Edu score 3), matching or exceeding methods trained on higher-quality data (scores 4–5).
- Performance gains hold under both AdamW and Muon optimizers, validating that aligning data selection with preconditioned update trajectories enhances training signal quality.
- OPUS generalizes beyond proxy-aligned benchmarks, showing superior performance on out-of-distribution reasoning and comprehension tasks.
- In continued pre-training on SciencePedia, OPUS reaches top performance with just 0.5B tokens—6x more data-efficient than random selection trained on 3B tokens—while improving across scientific domains.
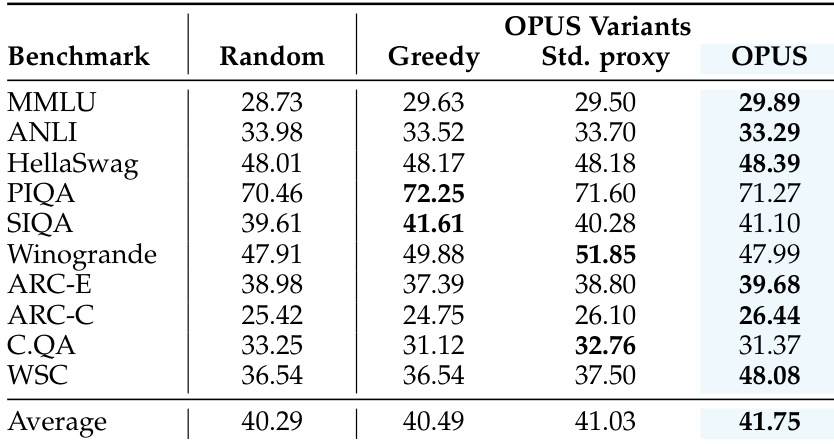
- Ablations confirm that stochastic sampling and benchmark-matched proxies are critical; greedy selection and default proxies underperform.
- OPUS maintains minimal computational overhead (4.7% slowdown) via CountSketch projections, outperforming static methods that incur higher selection costs.
- Qualitatively, OPUS selects more diverse, broadly useful samples compared to static methods that over-concentrate on narrow or high-loss patterns.
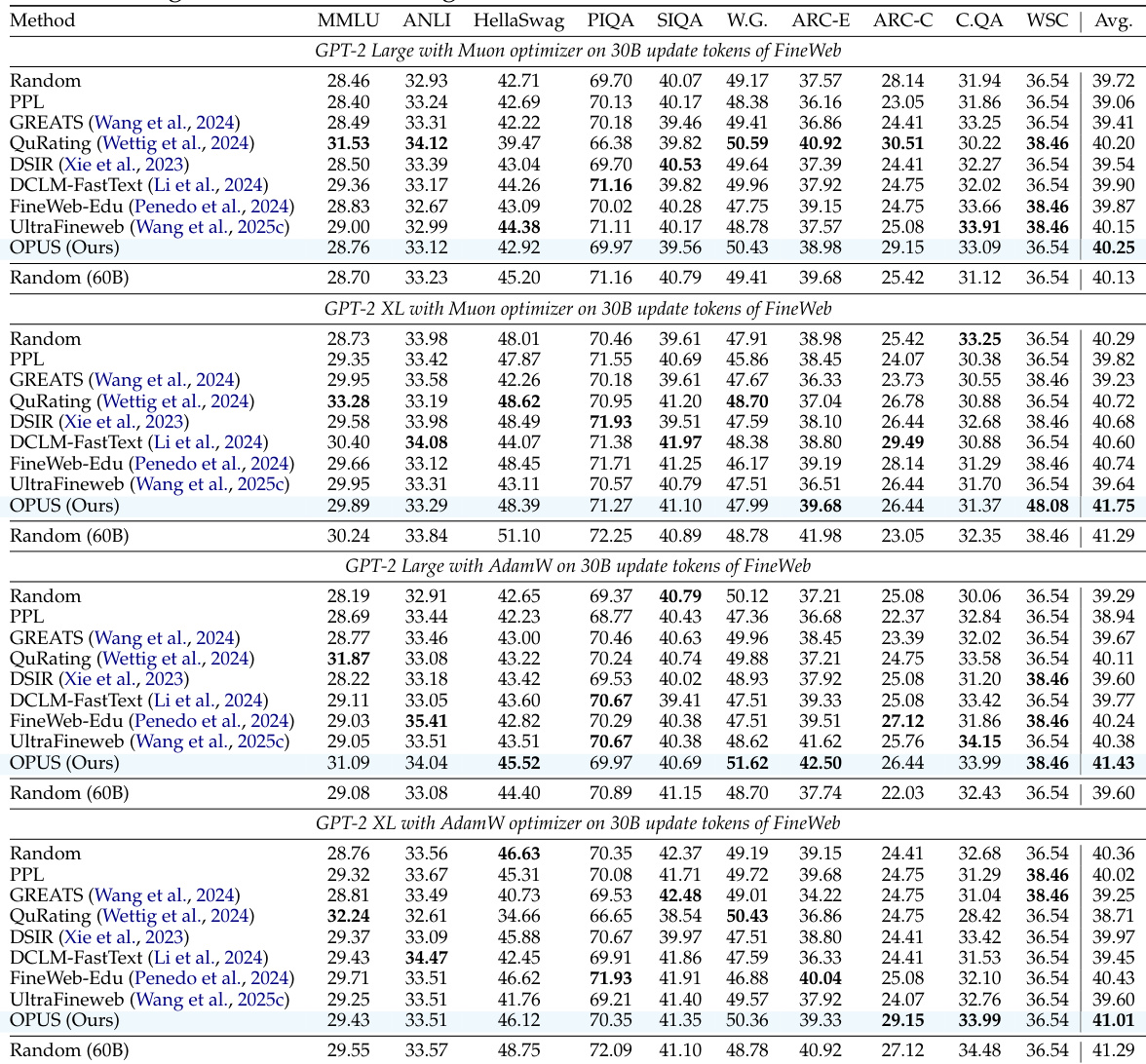
The authors use OPUS to dynamically select training data during pre-training, aligning selection with optimizer-specific update directions. Results show OPUS consistently outperforms both static filtering and other dynamic methods across multiple model sizes and optimizers, achieving higher average benchmark scores while maintaining computational efficiency. The method also demonstrates strong generalization and faster convergence, often matching or exceeding models trained with twice the compute budget.
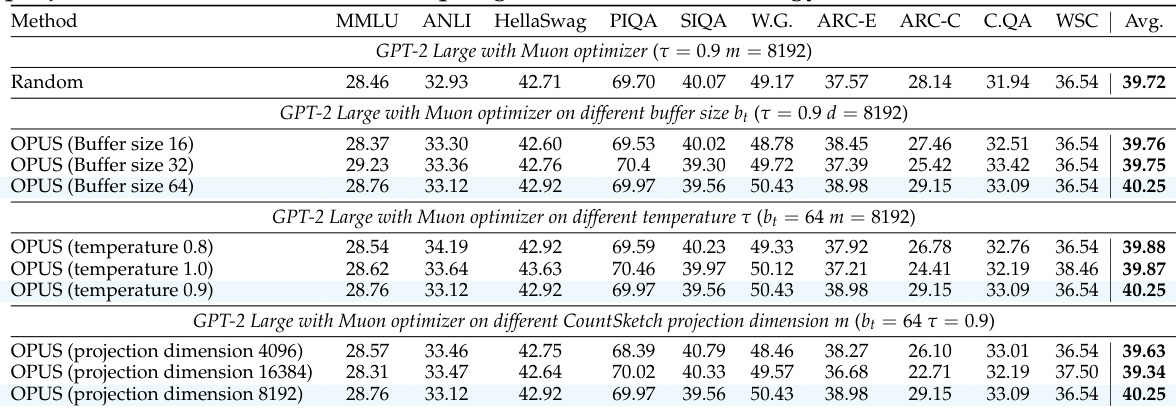
The authors evaluate OPUS under varying hyperparameters including buffer size, sampling temperature, and projection dimension, finding that larger buffers and moderate temperatures yield the best performance, while the 8192-dimensional projection consistently delivers optimal results. Results show that OPUS consistently outperforms random selection across all configurations, confirming its robustness to hyperparameter changes. The method’s effectiveness is maintained even when adjusting key components, indicating stable and reliable gains in model performance.
The authors use OPUS to dynamically select training data aligned with optimizer-specific update directions, achieving higher average benchmark performance than random, greedy, or standard proxy-based selection. Results show that incorporating stochastic sampling and benchmark-matched proxies improves generalization beyond narrow optimization signals. OPUS consistently outperforms baselines across diverse reasoning and knowledge tasks under the same compute budget.
The authors use OPUS to dynamically select training data during pre-training, aligning selection with optimizer-specific update directions. Results show OPUS consistently outperforms static and dynamic baselines across model sizes and datasets, even when selecting from lower-quality data subsets. The method achieves stronger generalization and faster convergence while maintaining minimal computational overhead.
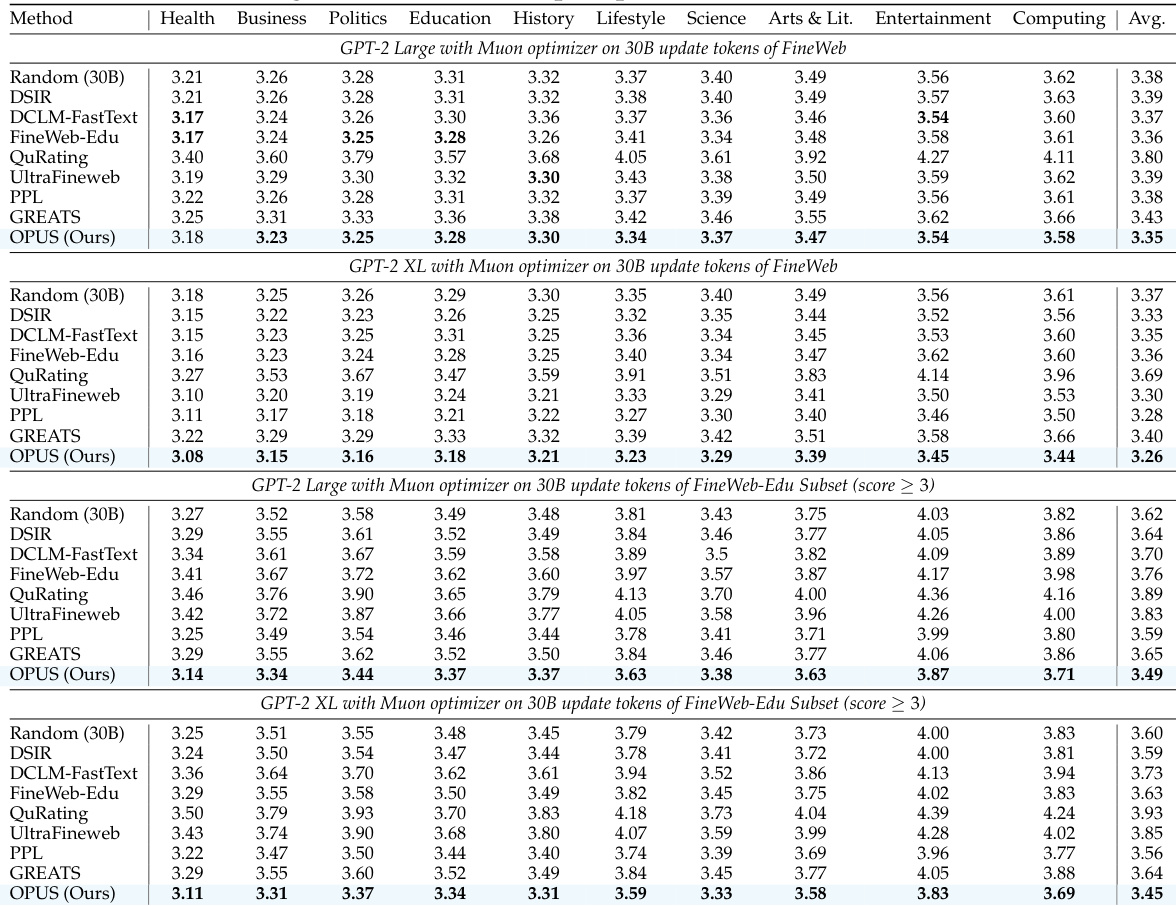
The authors use OPUS to dynamically select training data during pre-training, aligning selection with the optimizer’s update direction. Results show OPUS consistently outperforms static and dynamic baselines—even when selecting from lower-quality data—while achieving faster convergence and better generalization across benchmarks. The method also maintains efficiency, adding minimal computational overhead compared to random sampling.