Command Palette
Search for a command to run...
LingxiDiagBench: A Multi-Agent Framework for Benchmarking LLMs in Chinese Psychiatric Consultation and Diagnosis
LingxiDiagBench: A Multi-Agent Framework for Benchmarking LLMs in Chinese Psychiatric Consultation and Diagnosis
Abstract
Mental disorders are highly prevalent worldwide, but the shortage of psychiatrists and the inherent subjectivity of interview-based diagnosis create substantial barriers to timely and consistent mental-health assessment. Progress in AI-assisted psychiatric diagnosis is constrained by the absence of benchmarks that simultaneously provide realistic patient simulation, clinician-verified diagnostic labels, and support for dynamic multi-turn consultation. We present LingxiDiagBench, a large-scale multi-agent benchmark that evaluates LLMs on both static diagnostic inference and dynamic multi-turn psychiatric consultation in Chinese. At its core is LingxiDiag-16K, a dataset of 16,000 EMR-aligned synthetic consultation dialogues designed to reproduce real clinical demographic and diagnostic distributions across 12 ICD-10 psychiatric categories. Through extensive experiments across state-of-the-art LLMs, we establish key findings: (1) although LLMs achieve high accuracy on binary depression--anxiety classification (up to 92.3%), performance deteriorates substantially for depression--anxiety comorbidity recognition (43.0%) and 12-way differential diagnosis (28.5%); (2) dynamic consultation often underperforms static evaluation, indicating that ineffective information-gathering strategies significantly impair downstream diagnostic reasoning; (3) consultation quality assessed by LLM-as-a-Judge shows only moderate correlation with diagnostic accuracy, suggesting that well-structured questioning alone does not ensure correct diagnostic decisions. We release LingxiDiag-16K and the full evaluation framework to support reproducible research at https://github.com/Lingxi-mental-health/LingxiDiagBench.
One-sentence Summary
LingxiDiagBench is a multi-agent benchmark that evaluates large language models on Chinese psychiatric consultation and diagnosis by leveraging LingxiDiag-16K, a dataset of 16,000 EMR-aligned synthetic dialogues across twelve ICD-10 categories, to support dynamic multi-turn interactions and expose significant performance gaps in depression-anxiety comorbidity recognition and 12-way differential diagnosis.
Key Contributions
- The paper introduces LingxiDiag-16K, a dataset of 16,000 synthetic psychiatric consultation dialogues derived from electronic medical records that replicate clinical demographics and diagnostic distributions across twelve ICD-10 categories.
- The work develops Lingxi-iDiagBench, an agent-based evaluation framework that decouples patient simulation, consultation strategy execution, and diagnostic reasoning into specialized autonomous agents. The benchmark operationalizes assessment through three progressively complex diagnostic tasks, ranging from binary depression-anxiety classification to twelve-way ICD-10 multi-label prediction.
- Extensive experiments across state-of-the-art large language models reveal substantial performance gaps tied to diagnostic complexity, with binary classification accuracy reaching 92.3 percent while comorbidity recognition and twelve-way differential diagnosis drop to 43.0 percent and 28 percent respectively.
Introduction
The global shortage of mental health professionals and the subjective nature of clinical interviews create significant barriers to timely psychiatric assessment, making scalable AI diagnostic tools increasingly critical. Existing evaluation frameworks for psychiatric AI struggle to support real-world deployment because they rely on static question-answering, omit clinician-verified diagnostic labels, and rarely accommodate dynamic multi-turn consultation. To bridge this gap, the authors introduce LingxiDiagBench, a large-scale multi-agent benchmark that evaluates LLMs on Chinese psychiatric diagnosis and consultation. They construct LingxiDiag-16K, a dataset of 16,000 synthetic dialogues aligned with real electronic medical records across twelve ICD-10 categories, and deploy an agent-based evaluation system that simulates realistic patient interactions and diagnostic reasoning. This framework enables rigorous testing of both static classification and interactive information-gathering strategies, providing a reproducible platform to advance AI-assisted mental health assessment.
Dataset
-
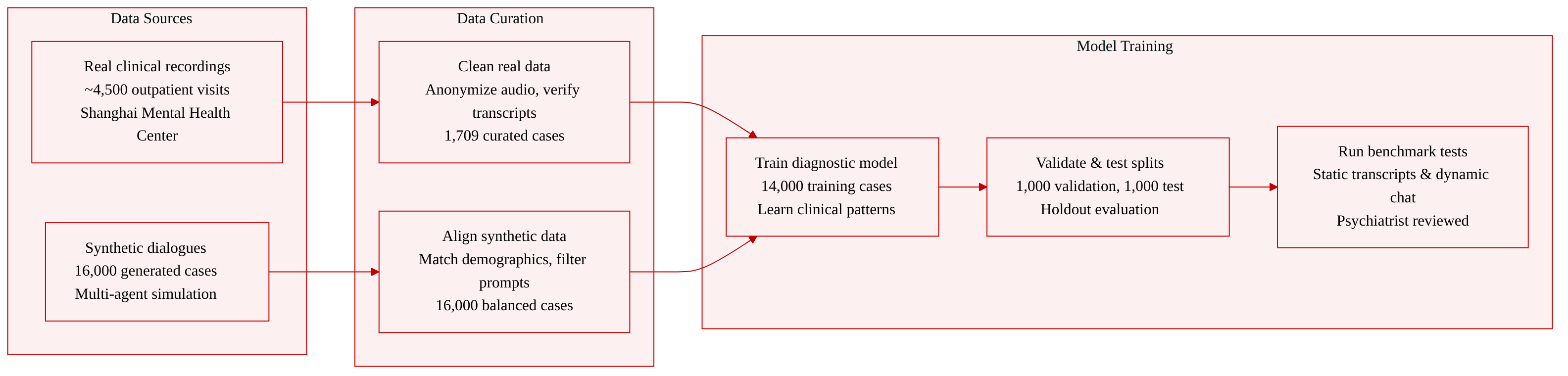
Dataset Composition and Sources The authors combine real-world clinical recordings with a large-scale synthetic dataset to balance diagnostic authenticity and scalable evaluation. The real data originates from outpatient visits at the Shanghai Mental Health Center, while the synthetic data is generated via a multi-agent framework to replicate clinical distributions without compromising patient privacy.
-
Subset Details
- LingxiDiag-Clinical: Derived from approximately 4,500 initial recordings, this subset contains 1,709 curated cases. The authors filter for cases with complete electronic medical records and verified transcriptions. Audio is anonymized, transcribed through automated speech recognition, and manually checked.
- LingxiDiag-16K: This synthetic subset contains 16,000 consultation dialogues paired with generated EMRs. The authors allocate 1,000 samples each for validation and testing, keeping the remainder for training while strictly matching demographic and diagnostic distributions across all splits.
-
Data Usage and Processing The authors use the clinical subset for model training and benchmarking, while the synthetic subset drives both static and dynamic evaluation paradigms. Static evaluation relies on fixed synthetic transcripts as ground truth, whereas dynamic evaluation tests real-time interaction between a Qwen3-32B powered doctor agent and a simulated patient. The authors control synthetic response length by sampling from the empirical distribution of real clinical data and apply targeted prompts to prevent unnatural phrasing and forced symptom disclosure.
-
Metadata Construction and Additional Processing To align synthetic outputs with real-world patterns, the authors extract demographic and clinical features from the clinical subset to construct a knowledge graph, which guides the probabilistic sampling of synthetic EMRs. They also build structured patient profiles combining demographics, chief complaints, illness history, and diagnostic labels to prompt the simulation agent. Two licensed psychiatrists review random synthetic samples to verify clinical realism and confirm the absence of protected health information. All data collection adheres to IRB approval and informed consent protocols.
Method
The authors propose a comprehensive framework for psychiatric diagnostic simulation and evaluation, illustrated in the framework diagram. The system is composed of a Data Foundation, an Agent System, and a Benchmark Evaluation module.
Data Foundation and Synthesis The foundation of the system is the LingxiDiag-16K dataset, which contains 16,000 synthetic Electronic Medical Records (EMRs) and dialogues. This dataset is synthesized from real clinical outpatient cases to preserve demographic and clinical distributions. The synthesis pipeline involves seven steps: sampling basic information (age, gender, ICD-10 code), generating accompanying person details, creating personal history based on age groups, generating chief complaints with specific symptom distributions, composing present illness narratives, sampling auxiliary fields (physical illness, drug allergies), and finally assembling these fields into complete EMR records. This ensures the synthetic data aligns with real-world distributions while providing a scalable resource for training.
Agent System Architecture The core of the system is the Agent System, which simulates a clinical consultation environment involving three distinct agents: the Patient Agent, the Doctor Agent, and the Diagnostic Agent.
As shown in the figure below:
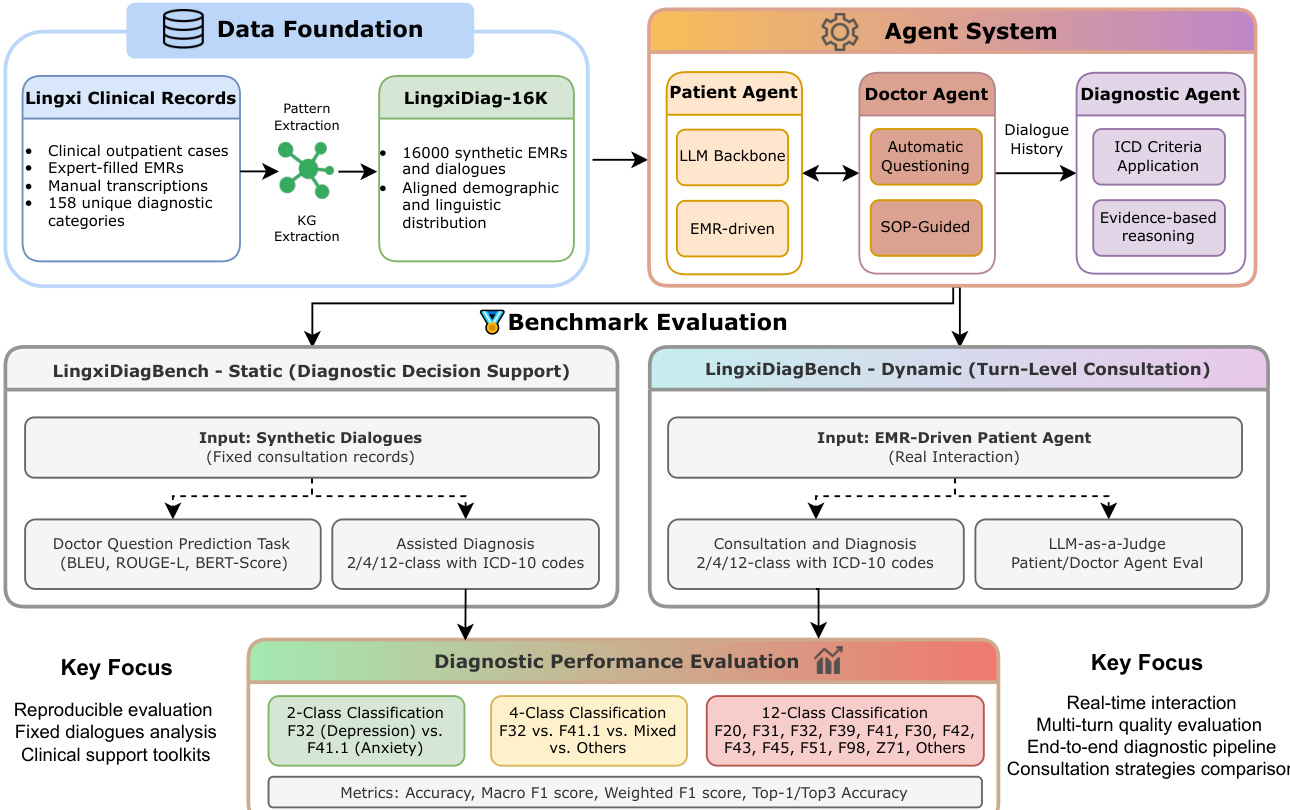
The Patient Agent is driven by the synthetic EMRs. It acts as the patient during the consultation, generating responses based on the pre-defined medical history.
The Doctor Agent simulates a psychiatrist conducting the interview. The authors implement four distinct consultation strategies to accommodate different clinical reasoning approaches:
- Free-form Strategy: The LLM acts as a senior psychiatrist without external guidance, autonomously selecting questioning directions based on patient responses.
- Symptom-Tree Strategy: This approach uses symptom-based decision trees derived from MDD-5K diagnostic protocols. However, to address the limitation of predefined finite symptom sets, the authors introduce a more flexible approach.
- APA-Guided Strategy: This follows a five-phase clinical guideline: screening (chief complaints and symptom duration), assessment (core symptom details and functional impairment), deep-dive (specific symptoms and underlying causes), risk assessment (suicide and self-harm screening), and closure (key information confirmation). Each phase includes mandatory and optional topics with explicit transition criteria.
- APA-Guided + MRD-RAG: This is a retrieval-augmented variant. During the Assessment and Deep-Dive phases, the Doctor Agent retrieves relevant diagnostic guidelines. The retrieval process involves embedding Chinese clinical guideline documents using a multilingual embedding model (Qwen3-Embedding-8B) and indexing them in a FAISS index. The top-k (k=5) similar chunks are retrieved, and an optional re-ranking step using a cross-encoder model (Qwen3-Reranker-8B) refines the results to the top 3 most relevant passages. These passages are injected into the prompt context to support next-question planning.
The Diagnostic Agent receives the complete dialogue history between the Doctor and Patient Agents. Unlike the Doctor Agent, which conducts real-time questioning, the Diagnostic Agent produces the final diagnostic conclusion along with supporting clinical rationales, applying ICD criteria to the full transcript.
Benchmark Evaluation The system is evaluated using the LingxiDiagBench, which is divided into two paradigms: Static and Dynamic.
- Static (Diagnostic Decision Support): This evaluates the model on fixed consultation records (synthetic dialogues). Tasks include Doctor Question Prediction (measured by BLEU, ROUGE-L, BERT-Score) and Assisted Diagnosis (2/4/12-class classification with ICD-10 codes).
- Dynamic (Turn-Level Consultation): This evaluates the model in real-time interaction scenarios using the EMR-Driven Patient Agent. It assesses the full consultation and diagnosis process (2/4/12-class classification) and uses an LLM-as-a-Judge for patient and doctor agent evaluation.
The performance is measured across 2-class (e.g., Depression vs. Anxiety), 4-class, and 12-class classification tasks, utilizing metrics such as Accuracy, Macro F1 score, Weighted F1 score, and Top-1/Top3 Accuracy.
Experiment
The evaluation framework utilizes both static transcript analysis and dynamic interactive consultations to assess Patient and Doctor Agents across clinical and conversational dimensions via a multi-model LLM-as-a-Judge protocol. Experiments validate that synthetic data effectively captures clinically meaningful patterns that generalize to real-world psychiatric scenarios, while human expert ratings confirm the reliability of the automated scoring pipeline. Qualitative analysis reveals that strong consultation quality does not consistently yield higher diagnostic accuracy, indicating that interviewing skills and diagnostic reasoning require separate optimization. Collectively, these findings establish a robust, clinically aligned foundation for developing and refining AI-driven psychiatric consultation systems.
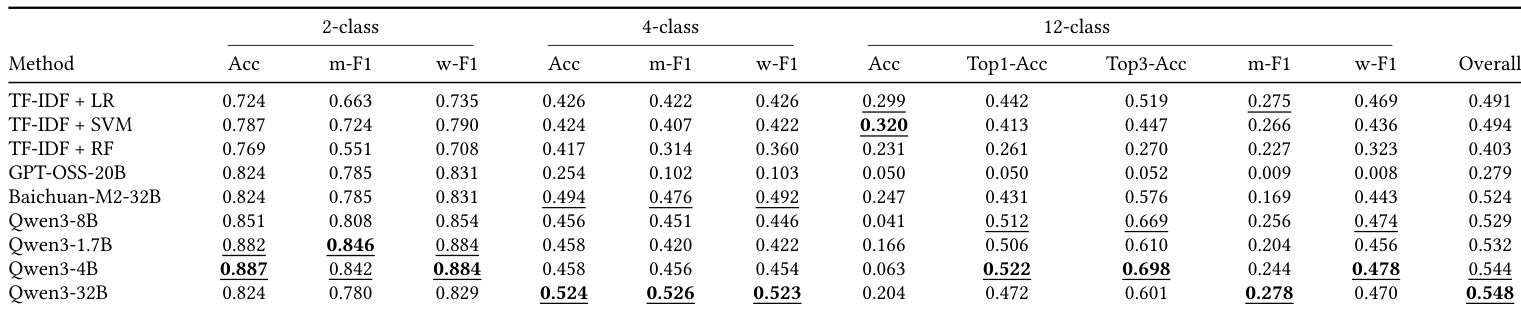
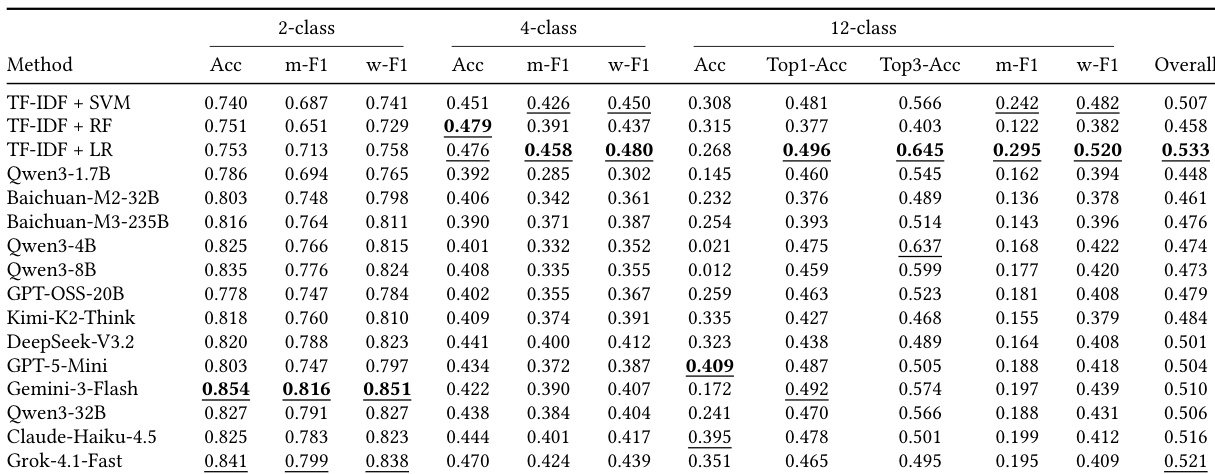
The the the table compares diagnostic performance on the LingxiDiag-Clinical dataset, evaluating both traditional machine learning techniques and large language models. While traditional methods maintain reasonable accuracy on binary classification, their performance declines significantly for multi-class tasks. In contrast, large language models, particularly the Qwen3 series, exhibit superior capabilities in complex diagnostic scenarios, with the largest model securing the best overall results. Traditional methods like TF-IDF show a marked decrease in performance as the classification task complexity increases from two to twelve classes. The Qwen3-32B model achieves the highest overall diagnostic accuracy across the evaluated multi-class tasks. The Qwen3-4B model demonstrates the strongest capability in Top-3 accuracy for the twelve-class classification task.
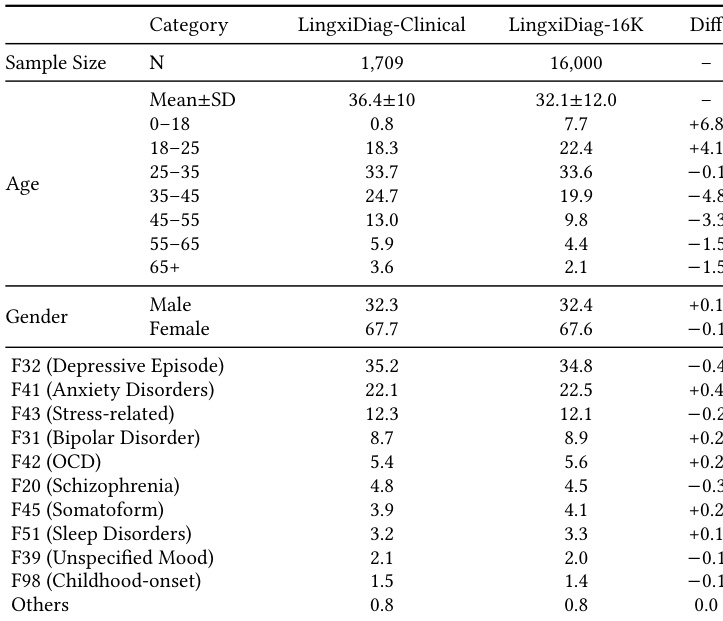
The the the table compares the demographic and diagnostic distributions of the real clinical dataset against the synthetic dataset. The data demonstrates that the synthetic dataset effectively mirrors the real-world clinical population in terms of gender balance and diagnostic category prevalence, with only minor deviations in specific age groups. The gender distribution is nearly identical between the two datasets, maintaining a consistent majority of female participants. Diagnostic category proportions are highly aligned, indicating that the synthetic dataset preserves the clinical prevalence of various mental health conditions. The synthetic dataset exhibits a slightly higher representation of younger individuals, particularly in the 0-18 and 18-25 age brackets, while showing lower representation in older age groups.
The authors evaluate Doctor Agents across four consultation strategies, identifying that the APA-Guided strategy augmented with MRD-RAG achieves the most consistent and superior performance across various models. Diagnostic accuracy is highly dependent on task complexity, with models demonstrating excellent capabilities in binary classification but significantly lower performance in fine-grained multi-class diagnosis. Furthermore, the results suggest a disconnect between consultation quality and diagnostic capability, as higher scores in interactive dialogue metrics do not reliably predict better diagnostic outcomes. The APA-Guided + MRD-RAG strategy consistently yields the highest performance across both consultation quality and diagnostic metrics compared to other methods. Diagnostic accuracy decreases substantially as the classification task becomes more granular, moving from binary to twelve-class prediction. Model performance is task-specific, with different models leading in binary classification versus multi-class diagnosis under the optimal strategy.
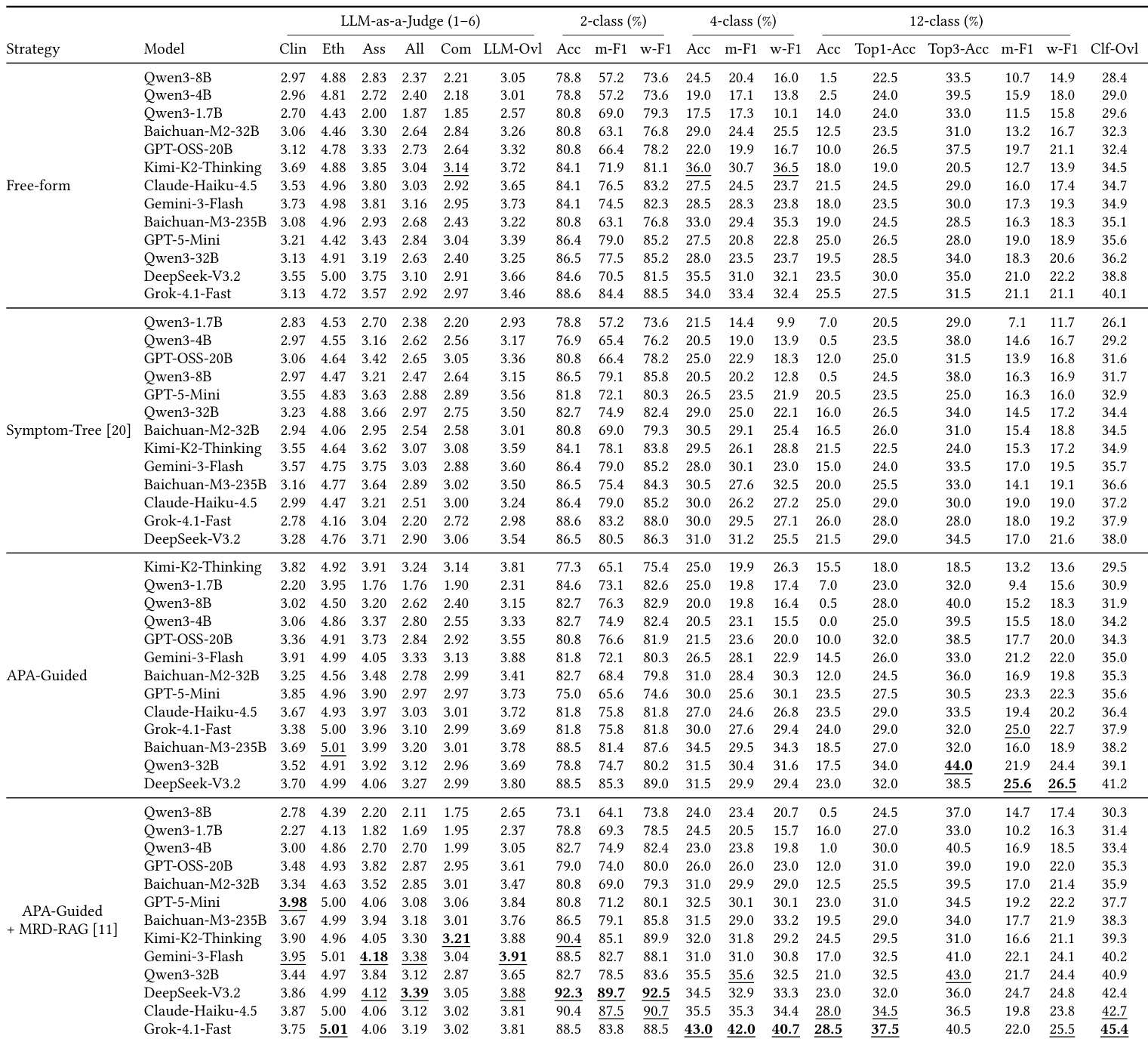
The experiment evaluates diagnostic accuracy across 2-class, 4-class, and 12-class tasks, comparing traditional machine learning methods with large language models. While binary classification performance is robust across most methods, accuracy decreases as the complexity of the diagnostic categories increases. Traditional approaches, specifically TF-IDF combined with logistic regression, demonstrate superior overall performance, particularly excelling in multi-class F1 scores where large models struggle. Gemini-3-Flash leads in accuracy for the 2-class classification task. TF-IDF + LR achieves the highest overall score, outperforming large language models on complex multi-class metrics. Diagnostic accuracy declines significantly for the 12-class task, with GPT-5-Mini recording the best accuracy for this category.
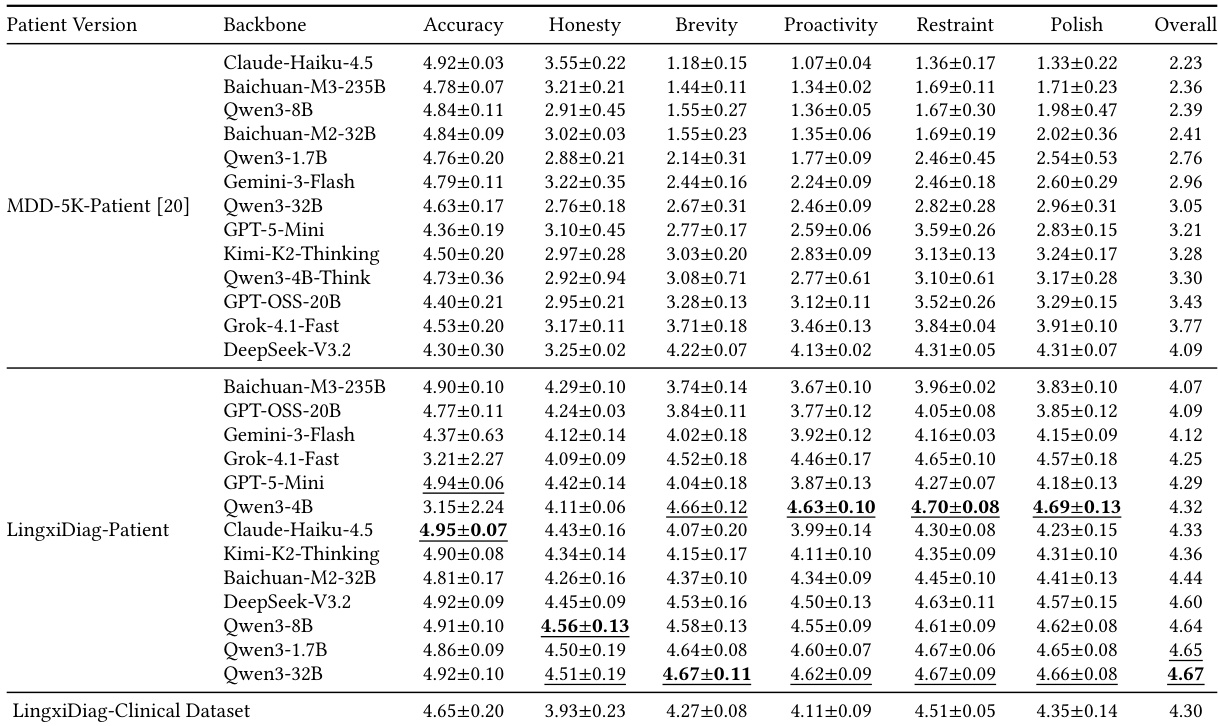
The experiment evaluates patient agent quality across six dimensions, comparing the MDD-5K-Patient benchmark against the LingxiDiag-Patient benchmark using various backbone models. The LingxiDiag-Patient version consistently yields higher performance scores across all dimensions compared to the MDD-5K-Patient version. Furthermore, the scores achieved by the top-performing LingxiDiag-Patient models are comparable to those observed in the real-world LingxiDiag-Clinical Dataset. LingxiDiag-Patient models consistently outperform MDD-5K-Patient models across all six evaluation metrics. Models like Qwen3-8B demonstrate significant performance gains when utilizing the LingxiDiag-Patient version. The performance of LingxiDiag-Patient models aligns closely with results from the real-world LingxiDiag-Clinical Dataset.
The experiments evaluate diagnostic and conversational capabilities across traditional machine learning, large language models, and synthetic versus real clinical datasets to assess model reliability, consultation strategy effectiveness, and data fidelity. Findings reveal that diagnostic accuracy is heavily influenced by task granularity, with binary classification remaining robust while fine-grained multi-class prediction exposes distinct architectural trade-offs between traditional algorithms and large language models. Structured consultation frameworks augmented with retrieval mechanisms consistently yield superior outcomes, demonstrating that guided interaction quality enhances diagnostic performance more reliably than unguided dialogue metrics. Furthermore, the synthetic benchmarks successfully replicate real-world demographic and diagnostic distributions, with the proposed patient dataset consistently aligning with actual clinical interactions and validating its utility for robust model training and evaluation.