Command Palette
Search for a command to run...
ABot-M0: VLA Foundation Model for Robotic Manipulation with Action Manifold Learning
ABot-M0: VLA Foundation Model for Robotic Manipulation with Action Manifold Learning
Abstract
Building general-purpose embodied agents across diverse hardware remains a central challenge in robotics, often framed as the ''one-brain, many-forms'' paradigm. Progress is hindered by fragmented data, inconsistent representations, and misaligned training objectives. We present ABot-M0, a framework that builds a systematic data curation pipeline while jointly optimizing model architecture and training strategies, enabling end-to-end transformation of heterogeneous raw data into unified, efficient representations. From six public datasets, we clean, standardize, and balance samples to construct UniACT-dataset, a large-scale dataset with over 6 million trajectories and 9,500 hours of data, covering diverse robot morphologies and task scenarios. Unified pre-training improves knowledge transfer and generalization across platforms and tasks, supporting general-purpose embodied intelligence. To improve action prediction efficiency and stability, we propose the Action Manifold Hypothesis: effective robot actions lie not in the full high-dimensional space but on a low-dimensional, smooth manifold governed by physical laws and task constraints. Based on this, we introduce Action Manifold Learning (AML), which uses a DiT backbone to predict clean, continuous action sequences directly. This shifts learning from denoising to projection onto feasible manifolds, improving decoding speed and policy stability. ABot-M0 supports modular perception via a dual-stream mechanism that integrates VLM semantics with geometric priors and multi-view inputs from plug-and-play 3D modules such as VGGT and Qwen-Image-Edit, enhancing spatial understanding without modifying the backbone and mitigating standard VLM limitations in 3D reasoning. Experiments show components operate independently with additive benefits. We will release all code and pipelines for reproducibility and future research.
One-sentence Summary
The AMAP CV Lab team introduces ABot-M0, a unified framework leveraging Action Manifold Learning and UniACT-dataset to enable efficient, general-purpose embodied agents across diverse robots; it shifts action prediction to low-dimensional manifolds, integrates modular 3D perception, and boosts stability without altering backbones.
Key Contributions
- ABot-M0 introduces a unified framework that standardizes heterogeneous robotic datasets into UniACT-dataset (6M+ trajectories, 9.5K hours) and jointly optimizes architecture and training to enable cross-embodiment generalization without custom hardware or proprietary data.
- It proposes the Action Manifold Hypothesis and Action Manifold Learning (AML), using a DiT backbone to directly predict clean, continuous actions on a low-dimensional manifold, improving decoding speed and policy stability over traditional denoising methods.
- The framework integrates modular 3D perception via plug-and-play modules like VGGT and Qwen-Image-Edit into a dual-stream VLM architecture, enhancing spatial reasoning while maintaining backbone integrity, and achieves state-of-the-art results on Libero, RoboCasa, and RoboTwin benchmarks.
Introduction
The authors leverage a unified framework to tackle the challenge of building general-purpose robotic agents that work across diverse hardware, a key goal in embodied AI. Prior efforts struggle with fragmented datasets, inconsistent representations, and misaligned training, which limit cross-platform generalization. Their main contribution is ABot-M0, which combines a large curated dataset (UniACT, 6M+ trajectories) with a novel Action Manifold Learning module that predicts actions as smooth, low-dimensional sequences—improving efficiency and stability over traditional denoising methods. They also introduce a dual-stream perception system that integrates VLM semantics with plug-and-play 3D modules, enhancing spatial reasoning without modifying the backbone. Experiments show state-of-the-art performance across multiple benchmarks, proving that high-quality embodied intelligence can emerge from systematically engineered public resources.
Dataset
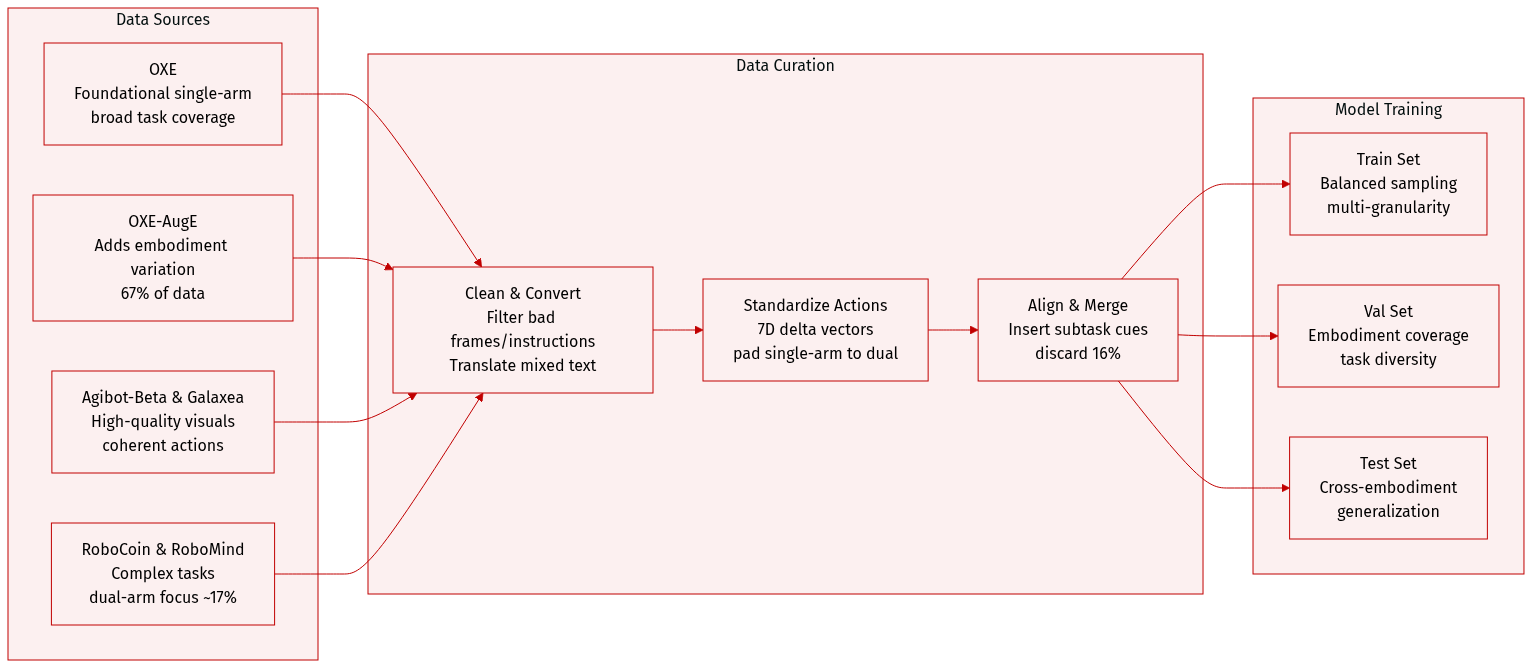
The authors use a curated, large-scale dataset called UniACT-dataset to train a general-purpose Vision-Language-Action (VLA) model for embodied intelligence. Here’s how they built and used it:
-
Dataset Composition & Sources:
They integrate six open-source datasets: OXE, OXE-AugE, Agibot-Beta, RoboCoin, RoboMind, and Galaxea. These collectively provide over 7 million raw trajectories, covering diverse robot embodiments, task types, and visual conditions. The final cleaned dataset contains over 6 million trajectories spanning 9,500+ hours and 20+ unique robot embodiments. -
Key Subset Details:
- OXE: Serves as the foundational single-arm dataset with broad task coverage.
- OXE-AugE: Augments embodiment variation within single-arm setups; contributes 67% of total data.
- Agibot-Beta & Galaxea: Provide high-quality visual observations and coherent action sequences; Agibot-Beta is downsampled to reduce embodiment bias.
- RoboCoin & RoboMind: Prioritized for complex task planning and cross-embodiment generalization (dual-arm); contribute ~17.2% combined.
- All datasets are cleaned and converted to LeRobot v2 format for consistency.
-
Cleaning & Filtering Rules:
- Remove trajectories with empty, garbled, or non-English instructions; translate mixed-language prompts.
- Discard visually degraded frames (black, blurred, occluded) or ineffective camera views.
- Filter out abnormal trajectories (wrong length, large action deltas, mismatched frame rates).
- Reject ambiguous or incomplete action annotations (e.g., missing dimensions, unclear rotation formats).
- Resolve subtask-level instruction alignment by inserting frame-aligned granular guidance.
- ~16% of trajectories are discarded during cleaning; the rest are refined and merged.
-
Standardization & Processing:
- All actions standardized to 7D delta vectors per arm: [Δx, Δy, Δz, rotation vector, gripper]. Rotation vectors (axis-angle) replace Euler/quaternions for stability.
- Single-arm data padded to dual-arm format (unused arm = zero), enabling unified training.
- Model always outputs dual-arm actions but activates only relevant channels during execution.
- Training uses multi-granularity uniform sampling to balance embodiment coverage and skill learning despite data imbalance.
-
Usage in Model Training:
The cleaned, standardized UniACT-dataset is split into training, validation, and test sets. The model is trained end-to-end on this mixture, with sampling strategies ensuring balanced exposure across embodiments and task types. The dataset’s scale, quality, and diversity jointly support cross-embodiment generalization and precise vision-language-action alignment.
Method
The authors leverage a two-component architecture for the ABot-M0 model, designed to map multimodal perception directly to robot action generation. The framework separates vision-language understanding from action generation into a Visual Language Model (VLM) and an action expert, respectively. The VLM, implemented using Qwen3-VL, processes stacked multi-view image sequences—typically from front-facing, wrist-mounted, and top-down cameras—alongside natural language instructions. These modalities are independently tokenized and fused into a unified token sequence to enable cross-modal reasoning. The VLM outputs spatially aligned multimodal representations, which serve as contextual input to the action expert for action prediction.
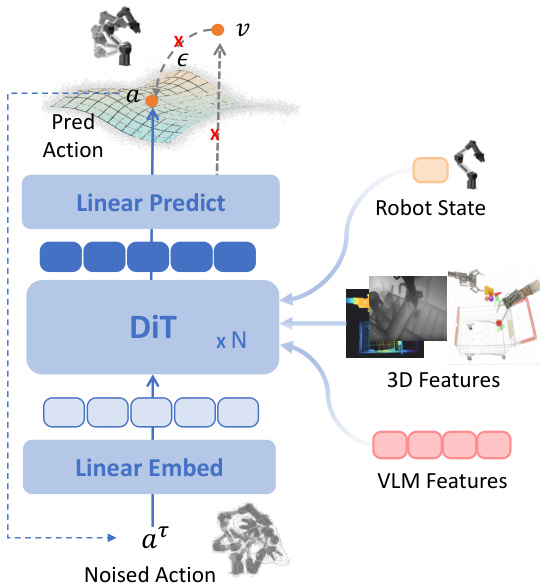
Refer to the framework diagram, which illustrates the end-to-end pipeline from data preprocessing through two-stage training to action generation. The model ingests multi-view images and text, processes them through the pre-trained VLM, and routes the resulting features—optionally augmented with 3D spatial information—to the action expert. The action expert, built upon a Diffusion Transformer (DiT), predicts denoised action chunks directly rather than velocity or noise, aligning with the action manifold hypothesis. This design enables the model to focus on learning the intrinsic structure of meaningful action sequences, which are posited to lie on a low-dimensional manifold, rather than regressing high-dimensional, off-manifold targets.

The action expert operates under a flow matching paradigm but predicts the denoised action chunk A^t directly, given noisy action Atτ, robot state qt, and contextual features ϕt from the VLM and optional 3D modules:
A^t=Vtheta(phit,Attau,qt).Although the model predicts actions, the training loss is computed on velocity to improve performance. The estimated and ground-truth velocities are derived as:
beginarrayrhatv=(hatAt−Attau)/(1−tau),v=(At−Attau)/(1−tau)endarrayThe loss function is a weighted mean squared error on velocity, equivalent to a reweighted action loss:
mathcalL(theta)=mathbbE∣vmathrmpred−vmathrmtarget∣2=mathbbEleft[w(tau)∣Vtheta(phit,Attau,qt)−At∣2right],where w(tau)=frac1(1−tau)2. This weighting dynamically adjusts the learning signal strength across noise levels, emphasizing fine-grained refinement as τ approaches 1.
During inference, the model follows an ODE-based trajectory to generate actions. Starting from pure noise At0simmathcalN(0,mathbfI), it iteratively denoises the action using the predicted velocity v^ and updates the state via numerical integration:
Attau+Deltatau=Attau+Deltataucdothatv.This approach retains the smooth trajectory generation of flow models while enabling direct action prediction at the model level.
The training process follows a two-stage paradigm. Stage 1 performs large-scale pre-training on the UniACT dataset, which contains over 6 million trajectories across 20+ embodiments. Actions are represented as delta actions in the end-effector frame, with single-arm actions as R7 and dual-arm as R14. A pad-to-dual-arm strategy ensures parameter sharing across embodiments, and a dual-weighted sampling strategy balances task and embodiment distributions to mitigate long-tail bias.
Stage 2 introduces supervised fine-tuning (SFT) to inject 3D spatial priors for high-precision tasks. The VLM and action expert are jointly fine-tuned with a small learning rate, dropout, and action noise perturbation to enhance robustness. This stage preserves generalization while improving performance on tasks requiring metric spatial reasoning, such as insertion or bimanual coordination.
To enhance spatial reasoning, the authors introduce a modular 3D information injection module that operates alongside the VLM. It integrates feedforward single-image 3D features (via VGGT) and implicit multi-view features (via Qwen-Image-Edit) to enrich the VLM’s semantic features with geometric priors. As shown in the figure below, these 3D features are fused with the final-layer VLM features via cross-attention before being passed to the action expert. This fusion strategy harmonizes semantic and geometric streams, enabling precise and spatially grounded action generation.
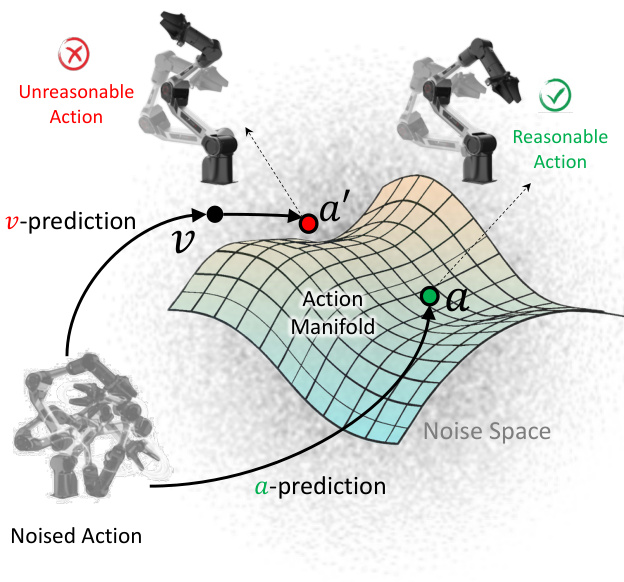
The action manifold hypothesis underpins the design of the action expert. As illustrated in the figure below, conventional velocity prediction (v-pred) can lead to unreasonable actions by projecting off the low-dimensional action manifold. In contrast, direct action prediction (a-pred) constrains the model to learn meaningful, coherent action sequences that lie on the manifold, reducing learning burden and improving action quality.
Experiment
- Task-uniform sampling outperforms trajectory- and embodiment-uniform strategies by balancing embodiment coverage and skill diversity, leading to stronger cross-embodiment, cross-dataset, and downstream task generalization.
- Pretraining with task-uniform sampling reduces redundancy and enhances exposure to rare skills and embodiments, improving overall model robustness without requiring strict embodiment-level balancing.
- Final-layer VLM features, pretrained on robotics data, are most effective for action prediction—outperforming intermediate layers, multi-layer concatenation, and action-query augmentation, indicating sufficient internal alignment with action semantics.
- Action Manifold Learning (AML), which directly predicts actions instead of noise, consistently surpasses noise-prediction paradigms across varying denoising steps and action chunk sizes, especially under high-dimensional or long-horizon conditions.
- Injecting 3D spatial features via cross-attention improves performance on both LIBERO and LIBERO-Plus, with multi-view synthesis further enhancing robustness to camera viewpoint perturbations.
- ABot-M0 achieves state-of-the-art results across multiple benchmarks (LIBERO, LIBERO-Plus, RoboCasa, RoboTwin2.0), demonstrating strong generalization, robustness to perturbations, and scalability to complex, high-dimensional manipulation tasks.
The authors use a task-uniform sampling strategy during pretraining to balance embodiment diversity and skill coverage, which leads to stronger cross-embodiment and cross-dataset generalization compared to trajectory- or embodiment-uniform approaches. Results show that this strategy reduces redundancy in skill sampling while improving exposure to rare embodiments, translating into better downstream performance across multiple benchmarks. The ABot-M0 model, built on this foundation, consistently outperforms prior methods in both single- and multi-arm manipulation tasks, demonstrating superior generalization and robustness.
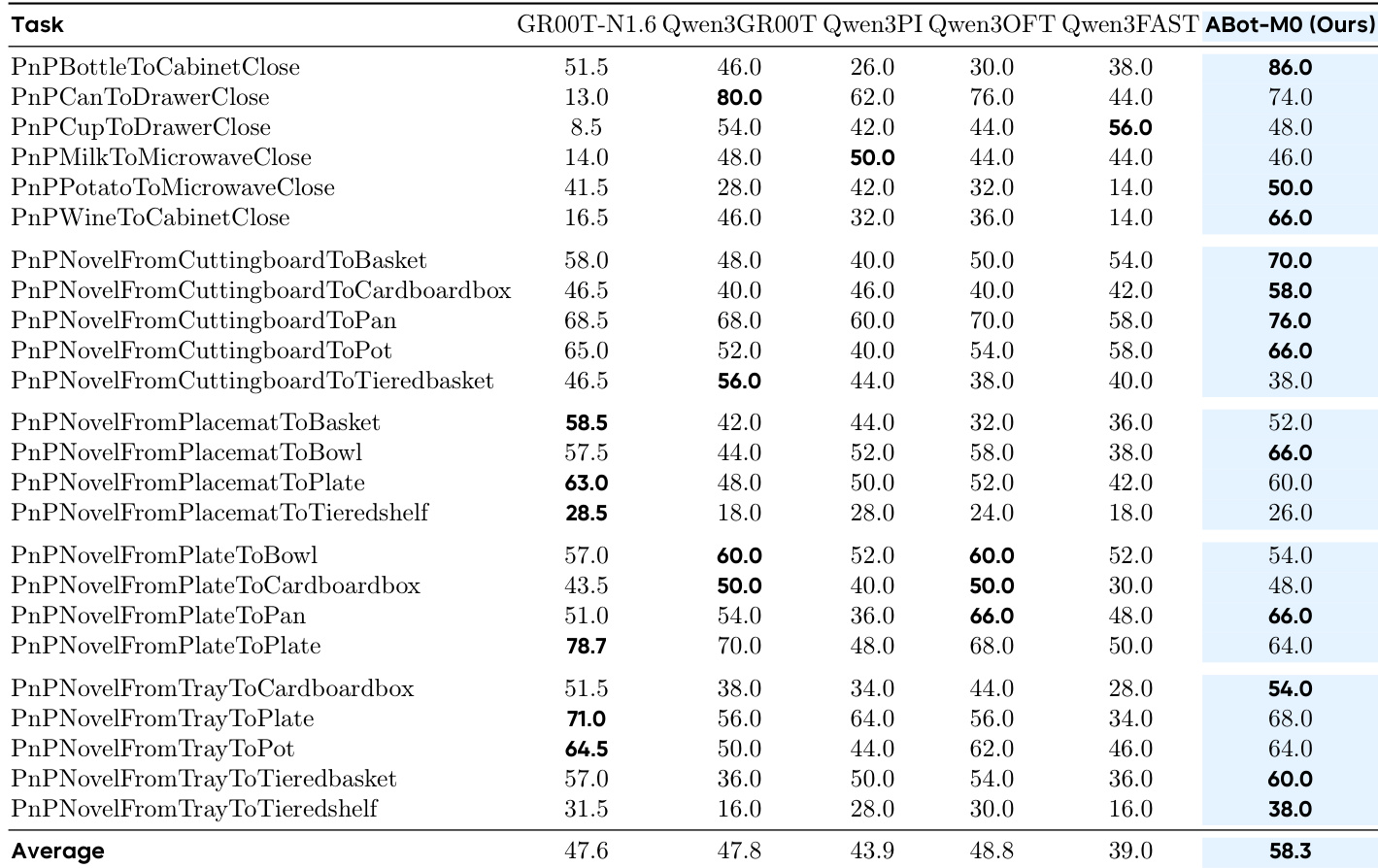
The authors use ABot-M0 to evaluate how varying action chunk sizes and denoising steps affect performance under perturbations in the LIBERO-Plus benchmark. Results show that ABot-M0 consistently outperforms Qwen3-VL-GR00T across most perturbation dimensions, especially at smaller chunk sizes, and maintains robustness even as chunk size increases, while GR00T’s performance degrades sharply. This supports the effectiveness of direct action prediction over noise prediction in handling high-dimensional action spaces under varying conditions.
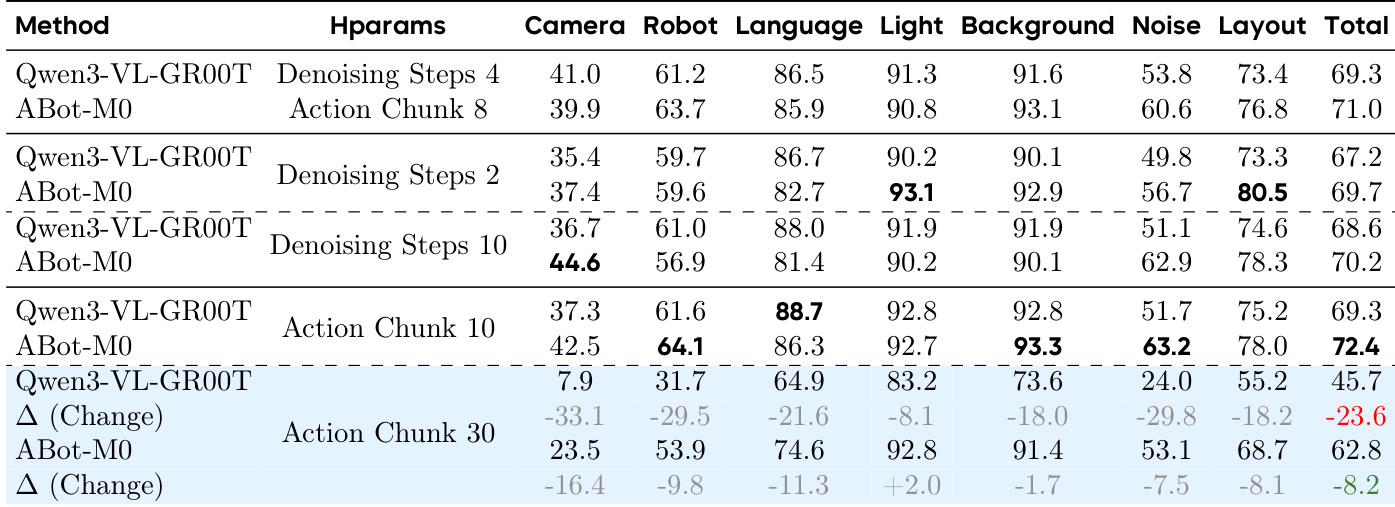
The authors evaluate how different VLM feature layers and query mechanisms affect action prediction performance after robotics pretraining. Results show that using features from the final layer without action queries consistently yields the highest success rates, indicating that deep representations already encode sufficient action-relevant semantics. Incorporating intermediate layers or action queries does not improve performance and may even degrade it, suggesting that the pre-trained model’s internal structure is optimally aligned with the action space without additional adaptation.
The authors use three sampling strategies—Trajectory-Uniform, Embodiment-Uniform, and Task-Uniform—to pretrain models on multi-embodiment robotic datasets and evaluate downstream performance on Libero Plus. Results show that Task-Uniform sampling achieves the highest overall success rate, indicating it better balances embodiment diversity and skill coverage during training. This strategy consistently outperforms the others in cross-embodiment generalization and downstream task adaptation.

The authors use a unified model trained across multiple suites to evaluate performance on the LIBERO benchmark, achieving state-of-the-art success rates across all task categories. Results show consistent superiority over prior methods, particularly in long-horizon and goal-conditioned tasks, indicating strong spatial reasoning and multi-step planning capabilities. The model’s high average performance reflects robust generalization across diverse manipulation scenarios without task-specific tuning.