Command Palette
Search for a command to run...
Composition-RL: Compose Your Verifiable Prompts for Reinforcement Learning of Large Language Models
Composition-RL: Compose Your Verifiable Prompts for Reinforcement Learning of Large Language Models
Xin Xu Clive Bai Kai Yang Tianhao Chen Yangkun Chen Weijie Liu Hao Chen Yang Wang Saiyong Yang Can Yang
Abstract
Large-scale verifiable prompts underpin the success of Reinforcement Learning with Verifiable Rewards (RLVR), but they contain many uninformative examples and are costly to expand further. Recent studies focus on better exploiting limited training data by prioritizing hard prompts whose rollout pass rate is 0. However, easy prompts with a pass rate of 1 also become increasingly prevalent as training progresses, thereby reducing the effective data size. To mitigate this, we propose Composition-RL, a simple yet useful approach for better utilizing limited verifiable prompts targeting pass-rate-1 prompts. More specifically, Composition-RL automatically composes multiple problems into a new verifiable question and uses these compositional prompts for RL training. Extensive experiments across model sizes from 4B to 30B show that Composition-RL consistently improves reasoning capability over RL trained on the original dataset. Performance can be further boosted with a curriculum variant of Composition-RL that gradually increases compositional depth over training. Additionally, Composition-RL enables more effective cross-domain RL by composing prompts drawn from different domains. Codes, datasets, and models are available at https://github.com/XinXU-USTC/Composition-RL.
One-sentence Summary
Researchers from USTC and collaborators propose Composition-RL, a method that composes pass-rate-1 prompts into new verifiable questions to enhance RL training efficiency, outperforming prior approaches across 4B–30B models and enabling cross-domain adaptation through curriculum-based compositional depth scaling.
Key Contributions
- Composition-RL addresses the diminishing effectiveness of verifiable prompts in RLVR by automatically composing multiple easy prompts (pass rate 1) into harder, novel questions, thereby expanding the useful training signal without requiring new data collection.
- Evaluated across 4B to 30B parameter models, Composition-RL consistently improves reasoning performance over standard RLVR, with further gains achieved via a curriculum variant that incrementally increases compositional depth during training.
- The method enables more effective cross-domain reinforcement learning by composing prompts from different domains (e.g., math and physics), outperforming simple mixing strategies and demonstrating broader generalization potential.
Introduction
The authors leverage Reinforcement Learning with Verifiable Rewards (RLVR) to enhance large language models’ reasoning, but face a key bottleneck: as training progresses, many prompts become too easy (pass rate 1), yielding no useful gradient signals. Prior work focused on hard prompts (pass rate 0) via advantage shaping or sampling, but ignored the growing pool of trivial prompts. To address this, they introduce Composition-RL, which automatically combines multiple simple prompts into harder, verifiable composite questions, effectively refreshing the training signal. Their approach consistently boosts performance across 4B to 30B models, especially when paired with a curriculum that gradually increases compositional depth, and enables stronger cross-domain learning by mixing prompts from different subjects like math and physics.
Dataset

- The authors use three dataset configurations for ablation studies on candidate sets 𝒟₁ and 𝒟₂, all derived from a base prompt pool 𝒟 of 12,000 prompts.
- Default Composition-RL: 𝒟₂ = 𝒟 (12,000 prompts), 𝒟₁ = random subset of 20 prompts. Final dataset size after filtering: 199K.
- Variant A: Both 𝒟₁ and 𝒟₂ are random subsets of 500 prompts each. After three filtering steps, sizes reduce from 240K → 202K → 200K.
- Variant B: 𝒟₁ = full 𝒟 (12,000 prompts), 𝒟₂ = random subset of 20 prompts. After filtering, sizes go from 231K → 201K → 200K.
- All variants are designed to produce roughly equivalent final dataset sizes (~200K) for fair comparison.
- Filtering follows the procedure in Section D.1, applied in three sequential steps to prune the compositional dataset.
Method
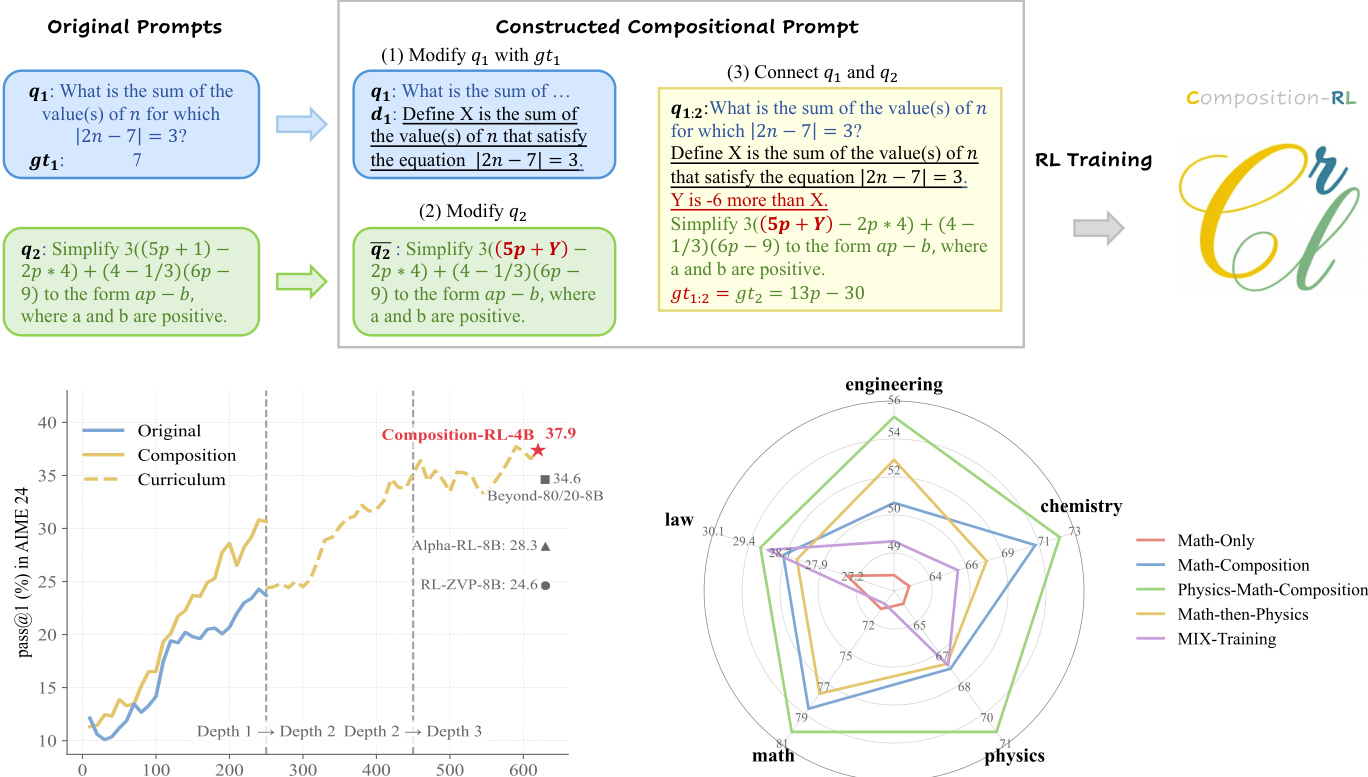
The authors leverage a structured pipeline for training large language models via reinforcement learning with compositional prompts, termed Composition-RL. The core innovation lies in the Sequential Prompt Composition (SPC) module, which algorithmically constructs complex, multi-step prompts from simpler ones, thereby inducing a curriculum of increasing compositional depth. This framework is designed to enhance the model’s ability to solve problems that require chaining multiple reasoning steps.
The SPC procedure begins by selecting two base prompts, q1 and q2, each with known ground-truth answers gt1 and gt2. The composition operator first modifies q1 by extracting a numeric value v1 from gt1 and embedding it into a natural-language definition d1, forming qˉ1=q1⊕d1. For instance, if q1 asks for the sum of values satisfying ∣2n−7∣=3 and gt1=7, the system defines X as that sum. Next, q2 is modified by replacing a numeric constant with a variable v2, yielding qˉ2. Finally, the two modified prompts are connected via a relational statement r that links v1 and v2—for example, “Y is 6 less than X”—resulting in the composed prompt q1:2=qˉ1⊕r⊕qˉ2. The ground-truth answer for the composed prompt is inherited from q2. This process is recursively extended to compose K prompts, where solving q1:K necessitates solving all constituent prompts in sequence.
Refer to the framework diagram, which illustrates the three-stage SPC pipeline: modifying q1 with its ground truth, modifying q2 by variable substitution, and connecting them with a relational constraint to form the final compositional prompt. The diagram also shows how these prompts feed into RL training under the Composition-RL paradigm.
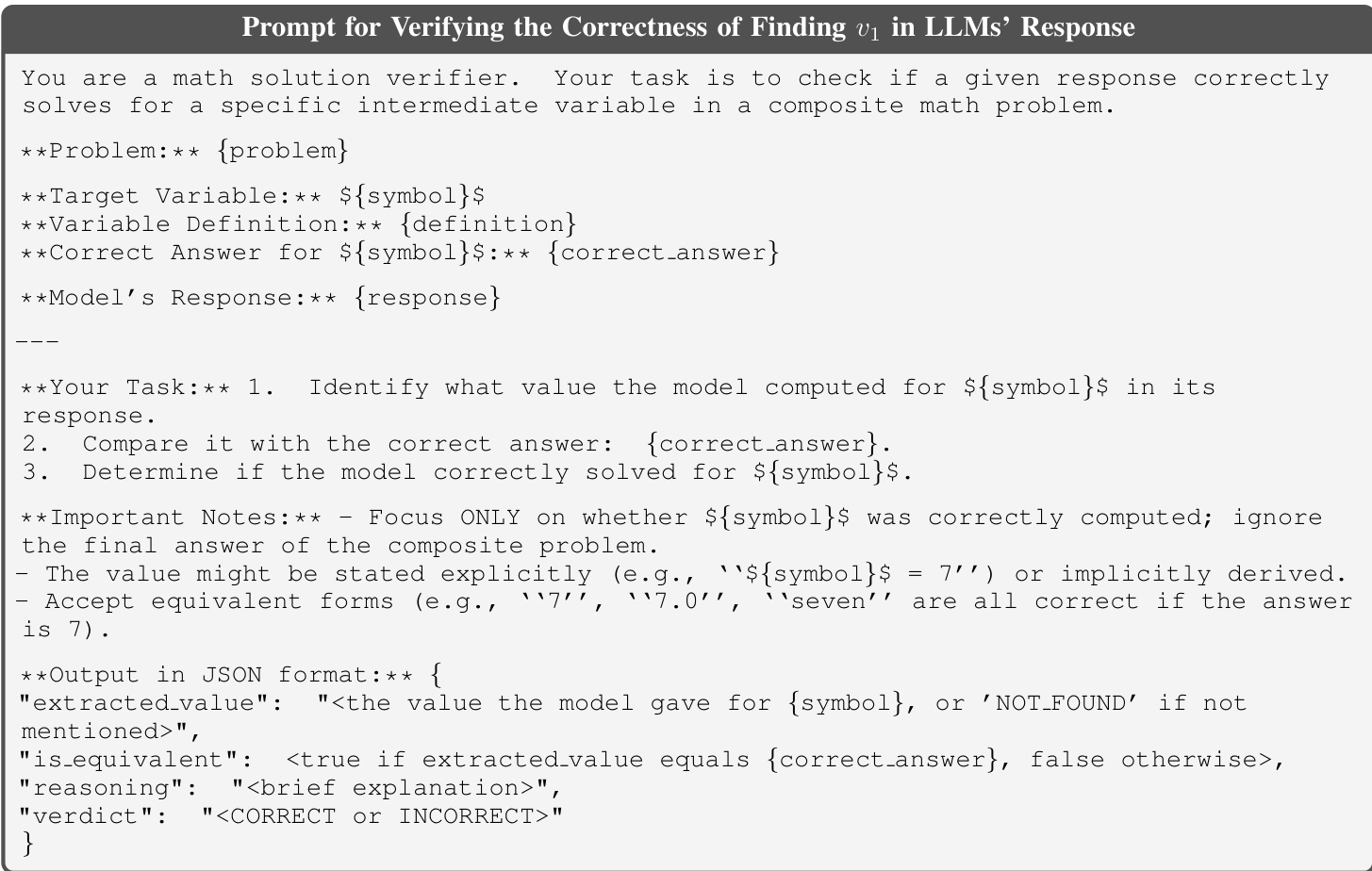
To ensure the reliability of automatically generated compositional prompts, the authors implement a multi-stage verification protocol using the same LLM as a self-checking agent. At each step of SPC, the model is prompted to validate its own modifications. For the first step—modifying q1 with gt1—the LLM is asked to compute the value of the newly defined variable v1 given the modified prompt and compare it against the originally extracted value. If the values mismatch, the composition is discarded. A similar verification is applied to the modification of q2, ensuring the substituted variable v2 remains consistent with the original problem. The final connection step is verified for syntactic and semantic consistency, such as variable name conflicts.
As shown in the figure below, the verification prompt for the first step instructs the LLM to extract the value of the new variable, compute it from the modified problem, and return a structured JSON verdict indicating whether the computed value matches the expected one. This self-verification mechanism reduces the error rate of compositional prompts to under 2%, ensuring high-quality training data.
For numerical and symbolic consistency, the authors further employ a Python-based verification step. The LLM is prompted to generate a Python script using the sympy library to symbolically compare the extracted value v1 against the ground truth, handling irrational constants and equivalent expressions. The script must output a boxed final comparison result, ensuring machine-verifiable correctness. This dual-layer verification—natural language and code-based—enhances the robustness of the compositional data generation pipeline.

During training, Composition-RL optimizes the RLVR objective over the generated compositional dataset DCK, using the Group Relative Policy Optimization (GRPO) algorithm. The policy gradient is estimated using a group of G responses sampled from the old policy, with advantages normalized by the group’s mean and standard deviation. To avoid vanishing gradients from uninformative prompts (those with all correct or all incorrect responses), dynamic sampling is employed: a larger candidate batch B^ is filtered to retain only prompts with intermediate success rates, ensuring non-zero advantage signals. The training objective is thus computed over a curated set of prompts that provide meaningful learning signals, enabling stable and effective policy updates.
Experiment
- Meta-experiments reveal that solve_all prompts, not just solve_none, severely limit RL training effectiveness; SPC mitigates this by making easy prompts harder and reducing solve_all rates.
- Composition-RL consistently outperforms standard RL on both in-domain math and out-of-domain benchmarks, with gains scaling significantly with model size, especially for larger models.
- Curriculum-based Composition-RL, progressing from depth-1 to depth-3 prompts, yields progressive performance gains and surpasses baselines even when using smaller models and fewer training prompts.
- Cross-domain Composition-RL (e.g., physics + math) outperforms mixed or sequential training, demonstrating broader generalization across law, engineering, and chemistry.
- Ablation studies confirm that using a diverse candidate set for the second prompt (q2) is critical for performance, as it exposes models to a wider range of verified answers.
- Composition-RL works by promoting compositional generalization—acquiring reusable reasoning skills—and provides implicit process supervision by encouraging correct intermediate reasoning steps.
The authors use compositional prompts to enhance RL training, finding that this approach consistently improves performance across both in-domain math and out-of-domain multi-task benchmarks. Results show that larger models benefit more significantly, with gains scaling up to over 14% in math tasks for the largest model. Curriculum-based training that progressively increases compositional depth further boosts performance, demonstrating that structured prompt composition can effectively mitigate saturation from overly easy prompts.

The authors use compositional prompt construction to enhance RL training, finding that sampling the first prompt from a small random subset and the second from the full dataset yields the strongest performance across both math and multi-task benchmarks. Results show that this configuration significantly improves overall accuracy compared to alternatives, particularly on challenging math tasks like AIME24 and MMLU-Pro, indicating that answer diversity in the second prompt component is critical for effective training.

Results show that training on cross-domain compositional prompts significantly improves performance on both in-domain math tasks and out-of-domain multi-task benchmarks compared to training on single-domain or mixed datasets. The Physics-MATH-Composition-141K dataset yields the highest gains, particularly on AIME24, AIME25, and MMLU-Pro, indicating that composed prompts requiring multi-domain reasoning enhance generalization across subjects. This suggests that structured composition of existing prompts can effectively expand training signal diversity without requiring new data collection.
