Command Palette
Search for a command to run...
GigaBrain-0.5M*: a VLA That Learns From World Model-Based Reinforcement Learning
GigaBrain-0.5M*: a VLA That Learns From World Model-Based Reinforcement Learning
Abstract
Vision-language-action (VLA) models that directly predict multi-step action chunks from current observations face inherent limitations due to constrained scene understanding and weak future anticipation capabilities. In contrast, video world models pre-trained on web-scale video corpora exhibit robust spatiotemporal reasoning and accurate future prediction, making them a natural foundation for enhancing VLA learning. Therefore, we propose GigaBrain-0.5M, a VLA model trained via world model-based reinforcement learning. Built upon GigaBrain-0.5, which is pre-trained on over 10,000 hours of robotic manipulation data, whose intermediate version currently ranks first on the international RoboChallenge benchmark. GigaBrain-0.5M further integrates world model-based reinforcement learning via RAMP (Reinforcement leArning via world Model-conditioned Policy) to enable robust cross-task adaptation. Empirical results demonstrate that RAMP achieves substantial performance gains over the RECAP baseline, yielding improvements of approximately 30% on challenging tasks including Laundry Folding, Box Packing, and Espresso Preparation. Critically, GigaBrain-0.5M^* exhibits reliable long-horizon execution, consistently accomplishing complex manipulation tasks without failure as validated by real-world deployment videos on our https://gigabrain05m.github.io{project page}.
One-sentence Summary
The GigaBrain Team proposes GigaBrain-0.5M*, a world model-enhanced VLA trained via RAMP reinforcement learning, enabling robust cross-task adaptation and 30% gains over RECAP on complex robotic tasks like Laundry Folding and Espresso Preparation, validated through real-world deployment.
Key Contributions
- GigaBrain-0.5M* addresses the limited scene understanding and weak future anticipation of standard VLA models by integrating a video world model trained on web-scale and robotic manipulation data, enabling more robust spatiotemporal reasoning for long-horizon tasks.
- The model introduces RAMP (Reinforcement leArning via world Model-conditioned Policy), a novel training framework that conditions policy learning on world model predictions, allowing self-improvement through human-in-the-loop rollouts and enhancing cross-task adaptation without relying on imitation or policy gradients.
- Evaluated on challenging real-world tasks including Laundry Folding and Espresso Preparation, GigaBrain-0.5M* achieves approximately 30% improvement over the RECAP baseline and demonstrates reliable long-horizon execution, validated by real-world deployment videos and top performance on the RoboChallenge benchmark.
Introduction
The authors leverage world model-based reinforcement learning to address the limited temporal reasoning in vision-language-action (VLA) models, which typically generate actions based only on immediate observations—hindering performance on long-horizon robotic tasks. Prior approaches rely on imitation learning or policy gradients, which suffer from compounding errors, sample inefficiency, or instability at scale. Their main contribution is GigaBrain-0.5M*, a VLA model built atop GigaBrain-0.5 that integrates RAMP—a reinforcement learning framework conditioned on world model predictions—to enable self-improvement through human-in-the-loop rollouts. This yields ~30% gains over RECAP baselines and enables reliable real-world execution of complex tasks like laundry folding and espresso preparation.
Method
The authors leverage a unified end-to-end Vision-Language-Action (VLA) architecture, GigaBrain-0.5, as the foundational policy model, which maps multimodal inputs—visual observations and natural language instructions—to sequences of robot actions. This model employs a mixture-of-transformers backbone, integrating a pre-trained PaliGemma-2 vision-language encoder for input representation and an action Diffusion Transformer (DiT) with flow matching for action chunk prediction. To enhance reasoning, GigaBrain-0.5 generates an Embodied Chain-of-Thought (Embodied CoT), comprising autoregressive subgoal language, discrete action tokens, and 2D manipulation trajectories t1:10. While language and discrete tokens are decoded via the VLM head, the 2D trajectory is regressed from learnable tokens through a lightweight GRU decoder. Depth and 2D trajectory information are treated as optional states, enabling adaptation to heterogeneous sensor modalities. All components are jointly optimized under a unified objective that balances CoT token prediction, diffusion-based action denoising, and trajectory regression:
L=EP,τ,ϵ[−j=1∑n−1MCoT,jlogpθ(xj+1∣x1:j)+∥ϵ−achunk−fθ(achunkτ,ϵ)∥2+λGRU(t^1:10)−t1:102],where MCoT,j masks CoT tokens, τ is the flow-matching timestep, ϵ is Gaussian noise, and λ balances trajectory loss. Knowledge Insulation ensures decoupled optimization between language and action prediction terms.
To further refine policy behavior, the authors introduce RAMP (Reinforcement leArning via world Model-conditioned Policy), a four-stage iterative training framework that integrates world model predictions to guide policy learning through experience and corrective feedback. As shown in the figure below, RAMP begins with World Model Pre-training, where a latent dynamics model Wϕ is trained to predict future visual states and value estimates from current observations and actions. The world model uses a Wan2.2 DiT backbone and is trained via flow matching on 4K hours of real robot manipulation data. Future visual states are encoded into spatiotemporal latents zt, while scalar signals (value vt, proprioception pt) are spatially tiled and concatenated to form a unified latent state st=[zt;Ψ(vt);Ψ(pt)]. The training objective minimizes the squared error between the model’s denoised output and the ground-truth latent state:
LWM=ED,τ,ϵ[∥Wϕ(sfutureτ,ϵ)−(sfuture−ϵ)∥2].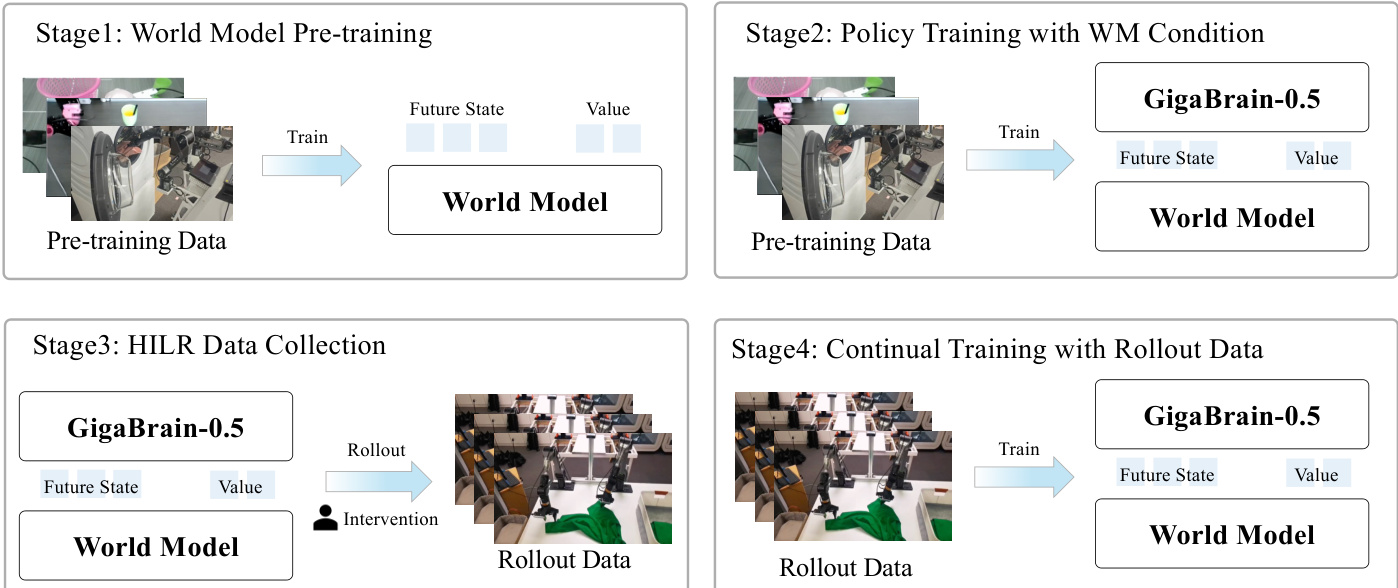
In Stage 2, the GigaBrain-0.5 policy is fine-tuned with world model conditioning. The policy receives future state tokens zfuture and value estimates vt, which are projected and converted into binary advantage indicators I=1(A(st,at)>ϵ) via n-step TD estimation:
A(st,at)=k=0∑n−1γkrt+k+γnvt+n−vt.The policy is trained to minimize the weighted negative log-likelihood of action generation conditioned on (I,z), as defined in the RAMP objective:
L(θ)=ED[−logπθ(a∣o,z,l)−αlogπθ(a∣I,o,zt,l)].To ensure robustness, stochastic attention masking randomly suppresses world model tokens with 20% probability during training, preventing over-reliance on synthetic signals.
Stage 3 deploys the policy for Human-in-the-Loop Rollout (HILR) data collection, where autonomous execution is interleaved with expert interventions. A smoothing mechanism removes temporal artifacts at intervention boundaries, preserving trajectory coherence. The resulting dataset combines native policy actions with expert corrections, reducing action distribution gaps compared to teleoperation.
In Stage 4, the policy is continually fine-tuned on the HILR dataset, while the world model is jointly updated to prevent advantage collapse. Stochastic masking is maintained to ensure training-inference consistency. The iterative rollout-annotation-training loop enables progressive policy improvement: as the policy becomes more capable, its autonomous rollouts generate higher-quality data for subsequent training cycles.
During inference, the authors enforce an optimistic control strategy by fixing I=1. Two execution modes are supported: an efficient mode that bypasses the world model for maximum inference frequency, and a standard mode that leverages predicted future states z for long-horizon planning. This architectural decoupling, enabled by stochastic masking, ensures flexible deployment across varying computational constraints.
Experiment
- GigaBrain-0.5 excels in complex, long-horizon robotic tasks like box packing and coffee preparation, outperforming prior models including π₀.5 and GigaBrain-0 across internal evaluations and the RoboChallenge benchmark.
- RAMP, the world model-based reinforcement learning method, demonstrates superior sample efficiency and multi-task generalization compared to baselines like AWR and RECAP, achieving near-perfect success in challenging real-world tasks.
- Ablation studies confirm the critical role of joint value and future state prediction in the world model, enhancing policy accuracy and task success while maintaining efficient inference.
- World model conditioning significantly boosts performance in both single-task and multi-task settings, with the largest gains observed in multi-task training, indicating strong cross-task knowledge transfer.
- Real-world deployments on PiPER arms and G1 humanoid robots validate robust, reliable execution across diverse manipulation tasks, including juice prep, laundry folding, and table bussing.
The authors compare value prediction methods and find that their world model-based approach, which jointly predicts future states and values, achieves the best balance of accuracy and speed. While a value-only world model variant is faster, it sacrifices prediction quality, and the VLM-based method is slower despite comparable accuracy. Results show that incorporating future state context significantly improves value estimation reliability.
