Command Palette
Search for a command to run...
Learning beyond Teacher: Generalized On-Policy Distillation with Reward Extrapolation
Learning beyond Teacher: Generalized On-Policy Distillation with Reward Extrapolation
Wenkai Yang Weijie Liu Ruobing Xie Kai Yang Saiyong Yang Yankai Lin
Abstract
On-policy distillation (OPD), which aligns the student with the teacher's logit distribution on student-generated trajectories, has demonstrated strong empirical gains in improving student performance and often outperforms off-policy distillation and reinforcement learning (RL) paradigms. In this work, we first theoretically show that OPD is a special case of dense KL-constrained RL where the reward function and the KL regularization are always weighted equally and the reference model can by any model. Then, we propose the Generalized On-Policy Distillation (G-OPD) framework, which extends the standard OPD objective by introducing a flexible reference model and a reward scaling factor that controls the relative weight of the reward term against the KL regularization. Through comprehensive experiments on math reasoning and code generation tasks, we derive two novel insights: (1) Setting the reward scaling factor to be greater than 1 (i.e., reward extrapolation), which we term ExOPD, consistently improves over standard OPD across a range of teacher-student size pairings. In particular, in the setting where we merge the knowledge from different domain experts, obtained by applying domain-specific RL to the same student model, back into the original student, ExOPD enables the student to even surpass the teacher's performance boundary and outperform the domain teachers. (2) Building on ExOPD, we further find that in the strong-to-weak distillation setting (i.e., distilling a smaller student from a larger teacher), performing reward correction by choosing the reference model as the teacher's base model before RL yields a more accurate reward signal and further improves distillation performance. However, this choice assumes access to the teacher's pre-RL variant and incurs more computational overhead. We hope our work offers new insights for future research on OPD.
One-sentence Summary
Researchers from Renmin University and Tencent propose G-OPD, a generalized on-policy distillation framework with reward scaling and flexible reference models, enabling students to surpass teachers via reward extrapolation (ExOPD), especially in multi-expert merging and strong-to-weak settings.
Key Contributions
- We theoretically unify on-policy distillation (OPD) with dense KL-constrained reinforcement learning, showing that OPD is a special case where reward and KL terms are equally weighted and the reference model is arbitrary, enabling a generalized framework (G-OPD) with flexible reward scaling and reference model selection.
- We introduce ExOPD, a variant of G-OPD with reward scaling >1, which consistently outperforms standard OPD across teacher-student pairings and enables students to surpass domain-specific teachers when merging multiple RL-finetuned experts, validated on 4 math and 3 code generation benchmarks.
- In strong-to-weak distillation, we show that using the teacher’s pre-RL model as the reference in ExOPD improves reward accuracy and distillation performance, though it requires additional compute and access to the teacher’s base model, further boosting results over standard OPD.
Introduction
The authors leverage on-policy distillation (OPD) — where a student model learns from teacher logits on its own generated trajectories — to improve LLM post-training, especially in merging domain-specific capabilities or distilling large teachers into smaller students. Prior OPD methods treat reward and KL regularization as fixed-equal components, limiting their flexibility and potential to exceed teacher performance. The authors’ main contribution is Generalized OPD (G-OPD), which introduces a reward scaling factor and flexible reference model; they show that scaling rewards above 1 (ExOPD) lets students surpass teachers, particularly in multi-teacher fusion and strong-to-weak distillation, and further improve results by using the teacher’s pre-RL model as reference — though this adds computational cost.
Method
The authors leverage a generalized on-policy distillation (G-OPD) framework that extends traditional knowledge distillation by incorporating dense token-level rewards and flexible regularization control. Unlike off-policy distillation, which trains the student to mimic teacher-generated trajectories without feedback from its own actions, G-OPD operates on-policy: the student generates its own responses, and the training signal is derived from the divergence between its output distribution and that of the teacher, conditioned on the student’s own rollout.
The core of G-OPD lies in its reformulation of the on-policy distillation objective using a reference model πref and a reward scaling factor λ. Starting from the standard OPD objective, which minimizes the reverse KL divergence between the student πθ and teacher π∗ over student-generated trajectories, the authors re-express this as a KL-constrained reinforcement learning objective. Specifically, they show that OPD is equivalent to maximizing a reward function r(x,y)=logπref(y∣x)π∗(y∣x) while penalizing deviation from πref via a KL term. This equivalence allows them to introduce λ to modulate the relative weight of the reward versus regularization, yielding the generalized objective:
IG−OPD(θ)=θmax Ex∼D,y∼πθ(⋅∣x)[λlogπref(y∣x)π∗(y∣x)−DKL(πθ(y∣x)πref(y∣x))].This formulation enables two key operational regimes. When 0<λ<1, the student’s log-probability distribution is encouraged to interpolate between the teacher and reference models — a setting the authors term “reward interpolation.” When λ>1, the student is pushed beyond the teacher’s distribution by extrapolating the reward signal, which they call “reward extrapolation.” This flexibility allows practitioners to tune the student’s behavior along a spectrum from conservative imitation to aggressive optimization.
In the strong-to-weak distillation setting — where a large teacher is distilled into a smaller student — the authors propose a “reward correction” mechanism. Instead of using the student’s base model as the reference, they advocate for using the teacher’s pre-RL base model πbaseteacher, which yields a cleaner implicit reward signal aligned with the teacher’s RL training trajectory. This correction adjusts the reward from logπbasestudentπ∗ to logπbaseteacherπ∗, effectively compensating for architectural and capacity mismatches between teacher and student base models.
The training dynamics are governed by a policy gradient estimator derived from the G-OPD objective. The approximated gradient, computed under a zero discount factor for computational efficiency, takes the form:
∇θJG−OPD(θ)=Ex∼D,y∼πθ(⋅∣x)[t=1∑TAtG−OPD∇θlogπθ(yt∣x,y<t)],where the token-level advantage is defined as:
AtG−OPD=(logπθ(yt∣x,y<t)−logπ∗(yt∣x,y<t))+(λ−1)(logπref(yt∣x,y<t)−logπ∗(yt∣x,y<t)).This advantage function encapsulates both the student-teacher mismatch and the reference-induced reward shift, enabling dense, per-token credit assignment that accelerates convergence and improves generalization.
Experiment
- Single-teacher distillation shows that standard OPD fully recovers teacher behavior, while reward interpolation (0 < λ < 1) enables controlled trade-offs between performance and response length; reward extrapolation (λ = 1.25) consistently surpasses the teacher, though λ = 1.5 risks instability due to reward hacking.
- In multi-teacher distillation, ExOPD with λ = 1.25 outperforms both OPD and SFT, producing a unified student that exceeds all domain teachers—unlike weight extrapolation (ExPO), which lacks consistent gains and controllability.
- In strong-to-weak distillation, ExOPD significantly outperforms standard OPD and SFT, demonstrating that reward extrapolation can overcome knowledge gaps between large and small models.
- Reward correction—using the teacher’s pre-RL variant as reference—further boosts ExOPD performance, though it incurs higher computational cost and requires access to additional model variants.
- Across settings, ExOPD consistently increases response length and entropy, indicating greater output diversity, while maintaining or exceeding teacher-level accuracy.
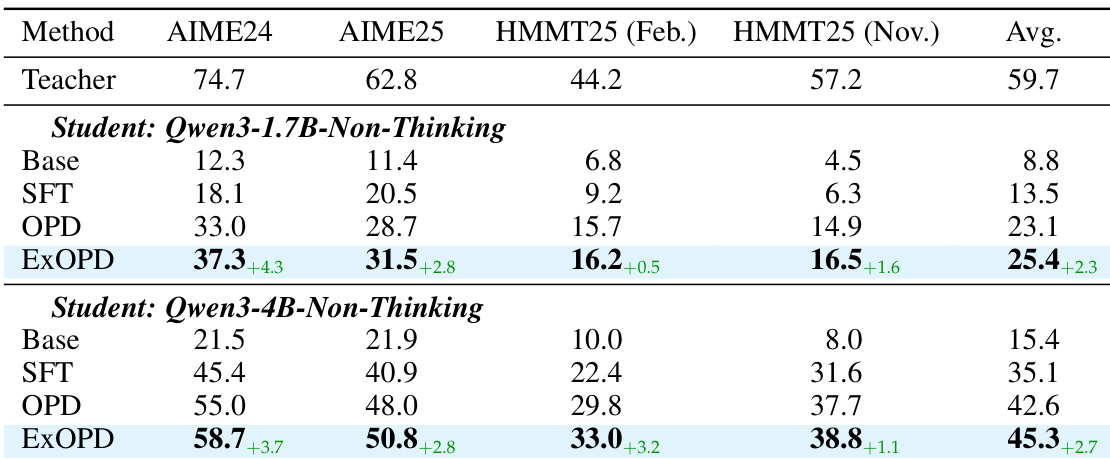
The authors use ExOPD to distill knowledge from stronger teacher models into smaller students in a strong-to-weak setting, achieving consistent improvements over standard OPD and SFT across multiple math reasoning benchmarks. Results show that ExOPD not only outperforms baseline methods but also scales effectively with student model size, delivering larger gains for smaller students. The method demonstrates robustness to model capacity gaps, suggesting reward extrapolation can push beyond standard distillation limits even when teachers and students differ significantly in scale.
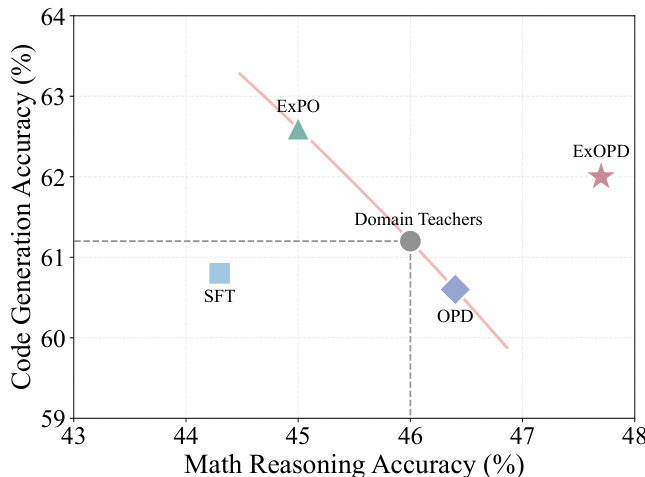
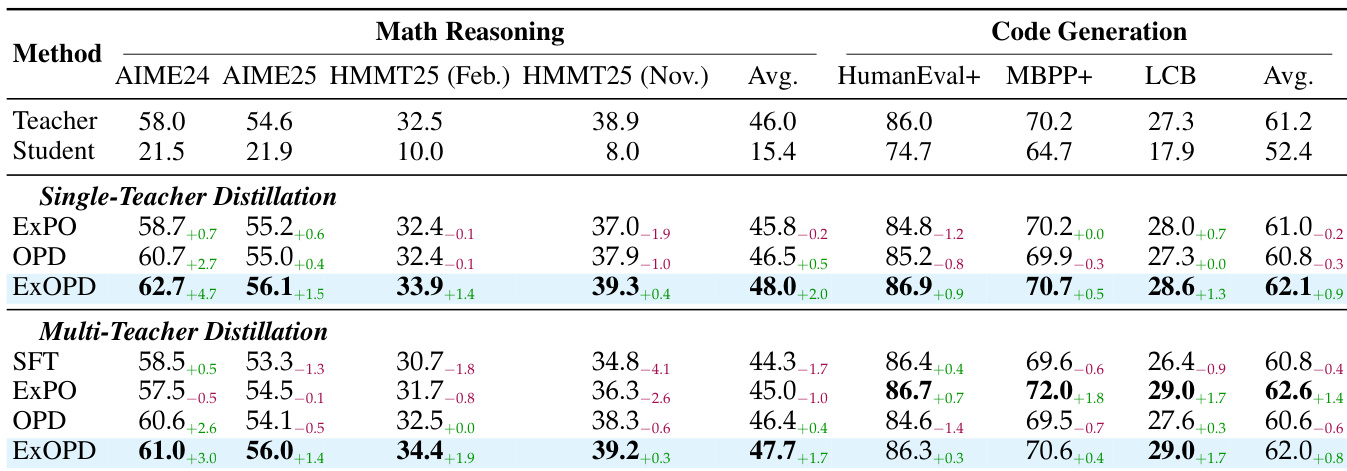
The authors use ExOPD with a reward scaling factor of 1.25 to distill knowledge from domain-specific teachers into a base model, achieving consistent performance gains over standard OPD and the original teachers across both math reasoning and code generation tasks. In multi-teacher settings, ExOPD is the only method that produces a unified student surpassing all individual domain teachers, while SFT and ExPO show limited or inconsistent improvements. Results also confirm that ExOPD’s gains are not due to insufficient teacher training, as continued RL on teachers yields smaller improvements than ExOPD with fewer steps.
The authors use ExOPD with a reward scaling factor of 1.25 to distill knowledge from domain-specific teachers into a base model, achieving performance that exceeds both the original teacher and standard OPD. Results show that even with fewer training steps, ExOPD consistently outperforms the teacher model across multiple math reasoning benchmarks, indicating its ability to push beyond the teacher’s capabilities. This improvement is not due to extended teacher training, as additional RL steps on the teacher yield smaller gains compared to ExOPD.
