Command Palette
Search for a command to run...
SkillsBench: Benchmarking How Well Agent Skills Work Across Diverse Tasks
SkillsBench: Benchmarking How Well Agent Skills Work Across Diverse Tasks
Abstract
Agent Skills are structured packages of procedural knowledge that augment LLM agents at inference time. Despite rapid adoption, there is no standard way to measure whether they actually help. We present SkillsBench, a benchmark of 86 tasks across 11 domains paired with curated Skills and deterministic verifiers. Each task is evaluated under three conditions: no Skills, curated Skills, and self-generated Skills. We test 7 agent-model configurations over 7,308 trajectories. Curated Skills raise average pass rate by 16.2 percentage points(pp), but effects vary widely by domain (+4.5pp for Software Engineering to +51.9pp for Healthcare) and 16 of 84 tasks show negative deltas. Self-generated Skills provide no benefit on average, showing that models cannot reliably author the procedural knowledge they benefit from consuming. Focused Skills with 2--3 modules outperform comprehensive documentation, and smaller models with Skills can match larger models without them.
One-sentence Summary
Researchers from multiple institutions introduce SKILLSBENCH, a benchmark evaluating how structured agent Skills impact LLM performance across 86 tasks; curated Skills boost success by 16.2pp on average, while self-generated ones offer no benefit, revealing models cannot reliably create the procedural knowledge they need.
Key Contributions
- SKILLSBENCH introduces the first standardized benchmark for evaluating Agent Skills, measuring their impact across 84 tasks in 11 domains using deterministic verifiers and three evaluation conditions: no Skills, curated Skills, and self-generated Skills.
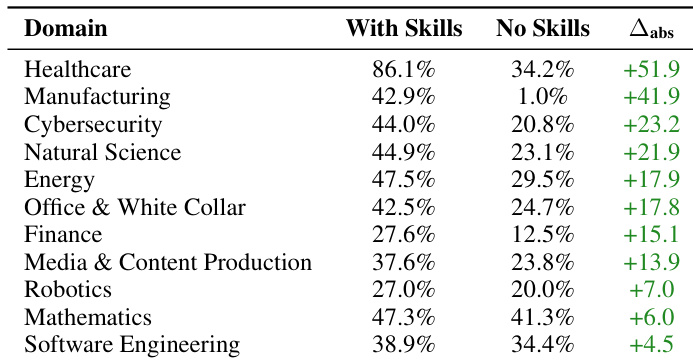
- Curated Skills boost average task pass rates by 16.2 percentage points across 7 agent-model configurations, but effectiveness varies widely by domain—ranging from +4.5pp in Software Engineering to +51.9pp in Healthcare—with 16 tasks even showing performance degradation.
- Self-generated Skills provide no net benefit on average, revealing that models cannot reliably author the procedural knowledge they need, while focused Skills with 2–3 modules outperform comprehensive documentation and enable smaller models to match larger ones without Skills.
Introduction
The authors leverage agent Skills—structured packages of instructions, code, and verification logic—to augment large language models at inference time without fine-tuning, addressing the gap between broad foundation models and domain-specific workflows. Prior agent benchmarks evaluate raw model performance but fail to isolate how Skills improve outcomes or what design elements drive success, leaving practitioners without evidence-based guidance. The authors introduce SkillsBench, the first benchmark treating Skills as first-class evaluation artifacts, by testing 84 tasks across 11 domains under three conditions—no Skills, curated Skills, and self-generated Skills—across 7 agent-model configurations, revealing that curated Skills boost resolution rates by 16.2 percentage points on average while self-generated ones offer little to no benefit.
Dataset

The authors use SKILLSBENCH, a benchmark designed to evaluate how Skills augmentation improves LLM-based agents. The dataset is built on the Harbor framework and includes 84 evaluated tasks across 11 domains, selected from 322 community-submitted candidates. Each task is self-contained in a Docker container and includes four components: human-authored instructions, an isolated environment, a reference solution (oracle), and deterministic verifiers to ensure reproducible evaluation.
Key details per subset:
- Task sources: 105 contributors from academia and industry submitted 322 candidate tasks; 84 were curated after automated and human review.
- Filtering rules: Tasks must have human-written instructions, general-purpose Skills (not task-specific), deterministic verification, and pass automated structural checks and oracle execution. Human reviewers evaluate data validity, task realism, oracle quality, Skill utility, and anti-cheating measures.
- Skill sources: 47,150 unique Skills were collected from GitHub (12,847), community marketplaces (28,412), and corporate partners (5,891), then deduplicated by content hash.
- Skill selection: Only Skills from the top quality quartile (score ≥ 9/12) were used in the benchmark to isolate procedural knowledge from quality variance.
- Task difficulty: Stratified by human completion time estimates, reviewed by domain experts.
How the paper uses the data:
- Tasks are evaluated under three conditions: no Skills, curated Skills, and self-generated Skills.
- Three commercial agent harnesses (Claude Code, Gemini CLI, Codex CLI) run 7 agent-model configurations, producing 7,308 trajectories.
- Curated Skills yield a +12.66pp average improvement in pass rate.
- Training split: Not applicable—SKILLSBENCH is used for evaluation only, not training.
- Mixture ratios: Not used; all tasks are evaluated independently under controlled conditions.
Processing and metadata:
- Each task directory includes a TOML config (task.toml), Dockerfile, skills/, solution/, and tests/ with pytest scripts.
- Resource limits (CPU, memory, timeout) are specified per task in task.toml.
- Skills must not contain task-specific identifiers, hardcoded values, or exact command sequences; they must provide procedural guidance applicable to a class of tasks.
- Leakage prevention: A Claude Code Agent SDK-based validation agent runs in CI to detect Skill-solution leakage; failed tasks are rejected.
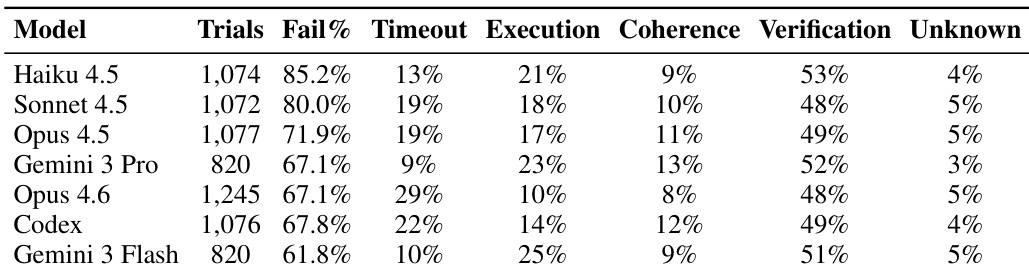
- Failure taxonomy: Agent failures are classified programmatically into five categories—Timeout, Execution, Coherence, Verification, and Unknown—based on structured test outputs, avoiding LLM-as-judge variance.
Method
The authors leverage a three-phase pipeline to construct, validate, and evaluate a skill-augmented agent benchmark, with each phase designed to ensure procedural fidelity, structural integrity, and measurable performance gains. The overall workflow begins with the aggregation of candidate skills from diverse sources—represented by icons for GitHub, e-commerce, and enterprise systems—followed by deduplication to yield 47,150 unique skills. These are then paired with 322 human-submitted tasks across 105 contributors, forming the initial benchmark corpus.
Refer to the framework diagram: the pipeline progresses into Phase 2, Quality Filtering, where automated and human review mechanisms act as a dual-stage funnel. Automated checks validate structural compliance, ensure 100% oracle execution, screen for AI-generated content, and audit for leakage or cheating. Human reviewers then assess data validity, task realism, skill quality, and anti-cheating robustness. This filtering reduces the task set to 84 high-fidelity tasks spanning 11 domains.
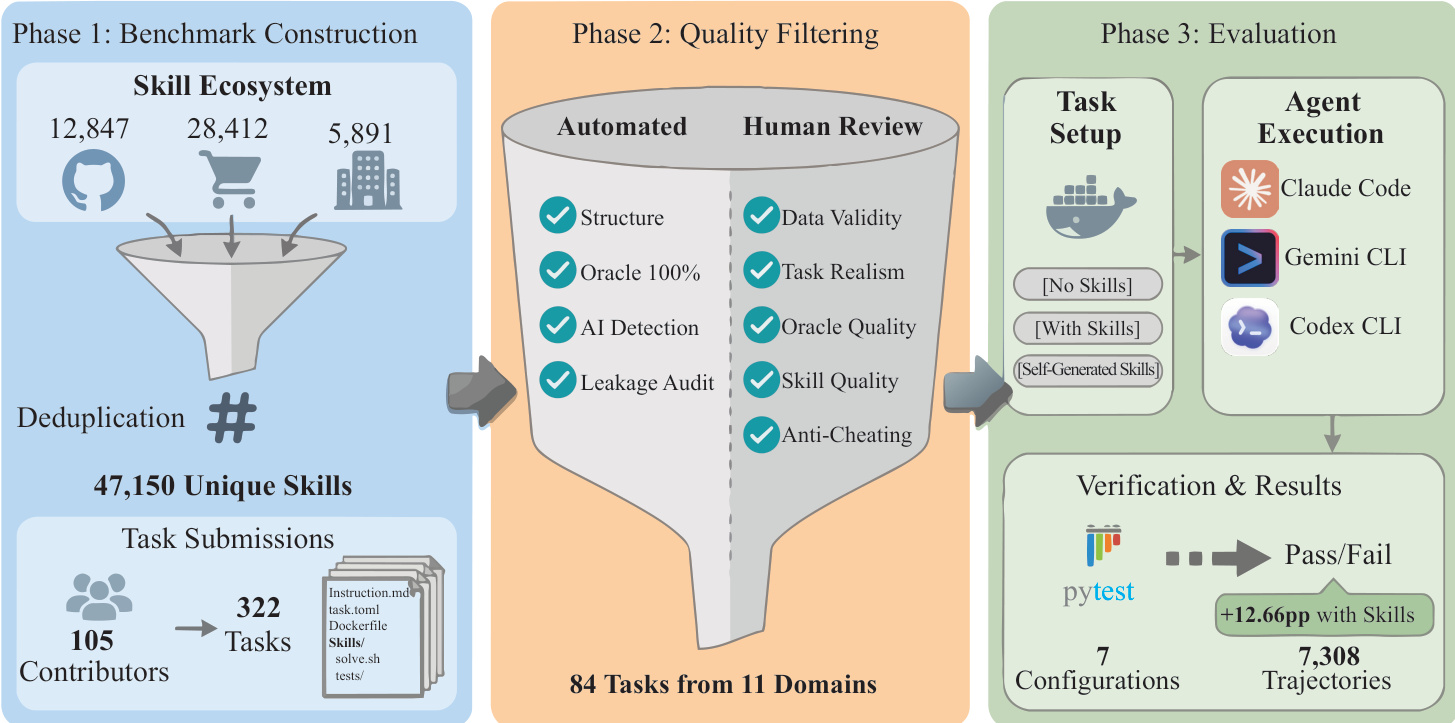
In Phase 3, Evaluation, agents interact with containerized environments under three conditions: no skills, pre-provided skills, or self-generated skills. The agent interface is standardized via an abstract base class requiring a step method that maps terminal observations to actions. Skills are injected into each container by copying the skills directory to agent-specific paths—such as /root/.claude/skills or /root/.agents/skills—enabling native discovery mechanisms. Claude Code and Codex CLI parse SKILL.md frontmatter for relevance, while Gemini CLI exposes an explicit activate_skill tool. Agents must autonomously determine which skills to apply, as instructions never specify them.
Each Skill is structured as a directory containing a required SKILL.md file with YAML frontmatter (name and description) and a procedural body, optionally supplemented by scripts or reference materials. During execution, agents operate under time or round limits, and outcomes are verified via deterministic assertions using pytest, yielding binary pass/fail results. The evaluation reports 7,308 trajectories across 7 configurations, with a measured +12.66 percentage point improvement when skills are available.
Experiment
- Curated Skills significantly boost agent performance on average (+16.2pp), but effectiveness varies widely across domains and agent-model combinations, with healthcare and manufacturing seeing the largest gains.
- Self-generated Skills offer no net benefit and often degrade performance, revealing that models cannot reliably produce the procedural knowledge they need to succeed.
- Focused Skills (2–3 modules) outperform comprehensive documentation, indicating that concise, modular guidance is more effective than exhaustive content.
- Smaller models equipped with Skills can match or exceed larger models without Skills, demonstrating that Skills can partially compensate for model scale limitations.
- Agent harnesses mediate Skills usage—some reliably integrate Skills, while others ignore or underutilize them, highlighting the importance of harness design in real-world deployment.
- Skills are most effective on tasks requiring domain-specific procedures or brittle formats, and can backfire when they introduce unnecessary complexity or conflict with existing model priors.
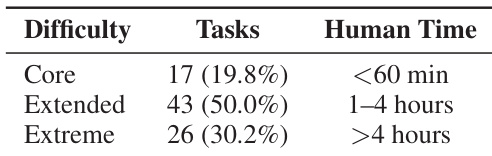
The authors categorize tasks by difficulty and estimated human effort, showing that most tasks fall into the Extended tier requiring 1–4 hours, while Core tasks take under 60 minutes and Extreme tasks exceed 4 hours. This distribution reflects a deliberate design to cover a broad spectrum of real-world procedural complexity, with the majority of tasks demanding moderate to substantial human effort.
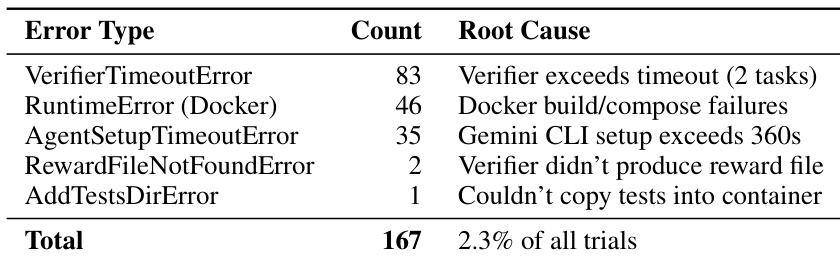
The authors use a structured error taxonomy to identify infrastructure-level failures during evaluation, finding that 2.3% of all trials encountered non-agent errors such as verifier timeouts, Docker setup issues, or missing reward files. These errors are treated as failures in scoring but are distinct from agent capability limitations, highlighting the importance of isolating system-level noise when measuring agent performance.
Curated Skills significantly boost agent performance across most domains, with gains ranging from +4.5 to +51.9 percentage points, reflecting strong domain-specific value where procedural knowledge is sparse in pretraining. However, the benefits are not uniform—domains like Healthcare and Manufacturing show dramatic improvements, while Software Engineering and Mathematics see more modest gains, indicating that Skills efficacy depends heavily on the task’s reliance on external, structured guidance.
The authors evaluate failure modes across six model configurations, finding that verification failures dominate across all models, indicating output quality—not structural understanding—is the primary bottleneck. Smaller models like Haiku 4.5 show higher overall failure rates and execution errors, while larger models like Opus 4.6 exhibit higher timeout rates, suggesting they pursue more ambitious but time-consuming strategies. Gemini 3 Flash and Pro show lower timeout rates but higher execution failure rates, reflecting faster but less reliable execution.
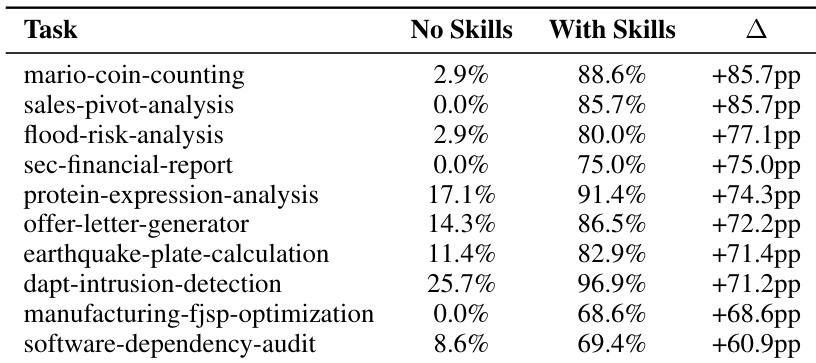
The authors use a curated set of procedural Skills to evaluate their impact on agent performance across multiple tasks, finding that Skills dramatically improve success rates on domain-specific tasks requiring specialized workflows or APIs. Results show that Skills can turn near-zero performance into high pass rates—such as in sales-pivot-analysis and flood-risk-analysis—by providing precise, actionable guidance that models cannot reliably generate on their own. However, the benefit is not universal, as some tasks show no improvement or even degradation, highlighting that Skills are most effective when they fill concrete procedural gaps rather than add redundant or conflicting information.